
我 4K 240fps!NVIDIA GeForce RTX 5090 顯示卡測試報告 / 無敵連技 DLSS 4 + Reflex 2

30% 效能提升靠實力、4K 240fps 靠 AI 加速,試問誰能追上!NVIDIA 新一代 Blackwell 架構、GeForce RTX 50 系列 GPU,專為新一代 Neural Rendering 打造,藉助生成式 AI 提升超解析度、光線重構、多畫格生成,憑著 DLSS 4 與 Reflex 2 Frame Warp 連技,讓玩家可擁有 4K 240fps 的全光追遊戲的極致性能,首波主打「GeForce RTX 5090」創始版效能解禁,究竟創作、生成 AI、電競、AAA 遊戲與光追遊戲的效能提升如何,就讓我們一邊測試一邊報告了。
新一代神 Blackwell 世代 NVIDIA GeForce RTX 5090
NVIDIA 新一代 GeForce RTX 顯示卡更新,採用最新 RTX Blackwell GPU 架構,針對 Neural Rendering 打造更適合混合渲染、光追、AI 運算的 GPU。NVIDIA 將在 1/30 日推出旗艦 GeForce RTX 5090 與 RTX 5080 顯示卡,而 RTX 5070 Ti 與 RTX 5070 則是 2 月推出。
RTX 5090 – 3,400 AI TOPS 美金定價 $1,999 元 / 台幣定價 NT$ 71,990 元
RTX 5080 – 1,800 AI TOPS 美金定價 $999 元 / 台幣定價 NT$ 35,990 元
RTX 5070 Ti – 1,400 AI TOPS 美金定價 $749 元 / 台幣定價 NT$ 26,990 元
RTX 5070 – 1,000 AI TOPS 美金定價 $549 元 / 台幣定價 NT$ 19,990 元。
NVIDIA 台灣公布的定價是建議售價,普遍品牌廠商推出的超頻 OC 版本價格會在貴一些;而美金-台幣建議售價相比之下這 4 張卡都抓在 36 的匯率,因此新卡的售價勢必會高一些。

↑ GeForce RTX 50 系列推出時間與美金定價。
從簡易的規格表來比較 RTX 50 系列與上一代產品的差異,RTX 50 的 SM 單元針對 Neural Rendering 打造、第 4 代 RT Core 支援 Mega Geometry、第 5 代 Tensor Core 加入 FP4 精度可原生支援 FP4/FP8/FP16 等 AI 運算。
以及最重要的 DLSS 4 多畫格生成、負責調度 GPU 負載的 AMP 處理器(獨立硬體支援 Win 11 硬體加速GPU 排程)、以及全面採用 GDDR7 記憶體、PCIe 5.0 等新技術;此外,影像編解碼引擎也有著升級,最高 3 個第 9 代編碼、2 個第 6 代解碼引擎。

↑ NVIDIA RTX 50 系列主要差異。
RTX 50 世代依然使用 TSMC 4nm 4N NVIDIA 客制化製程,意味著這代的效能提升都要靠著 RTX Blackwell GPU 架構、GDDR7 記憶體、Max-Q 電源效率、DLSS 4 等技術來實現。
這代旗艦的「RTX 5090」有著最高 21760 個 CUDA 核心、680 個 Tensor Core 與 176 個 RT Core,預設 GPU Boost 時脈為 2407 MHz。同時 RTX 5090 也是市售顯示卡中有著最大 32GB GDDR7 記憶體,記憶體介面來到 512-bit、1792 GB/s 的超高頻寬,以及驚人的 TGP 575W 的高功耗。
至於 RTX 5080 則被大砍一刀,10752 個 CUDA 核心、336 個 Tensor Core 與 84 個 RT Core,預設 GPU Boost 時脈為 2617 MHz,搭配 16GB GDDR7 記憶體、256-bit / 960 GB/s 頻寬、TGP 360W 等規格。
這代的規格策略與上一代相同,RTX 5090 有著幾乎完整的 GB202 核心,亦是這代 RTX Blackwell 在消費端零售市場最旗艦的 GPU,更適合做為 AI 運算、渲染等專業工作使用;至於 RTX 5080 幾乎砍半的規格,但也較為合理的零售價格與效能,更能被遊戲玩家族群接受,當然這空間未來一定還會有 RTX 5080 Super 或 Ti 的型號出現,但少說也要 2026 或 2027 了。
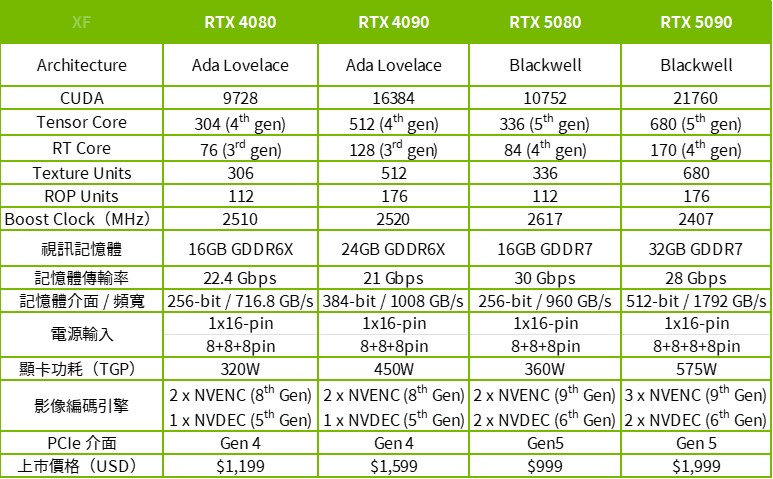
↑ RTX 5090 與 RTX 5080 規格表。
Blackwell 架構 Neural Rendering 全新電腦繪圖世代
半導體最著名的摩爾定律如今在物理極限下越來越難實現,但靠著「Neural Rendering」能夠讓影像品質快過於摩爾定律,這也就是大家熟悉的「DLSS」。DLSS 藉助超解析度 SR 提升畫質、RR 光線重構讓路徑追蹤得以即時渲染,為玩家帶來更真實的影像與順暢的遊戲體驗。
RTX Blackwell 帶來 DLSS 4 多畫格生成技術,以及全新 Neural Rendering 渲染技術:RTX Neural Materials、RTX Neural Faces、RTX Neural Radiance Cache (NRC) 等,更為所有 DLSS 玩家帶來全新的 Transformer 神經網路,讓遊戲的影像細節、動態表現更佳出色。
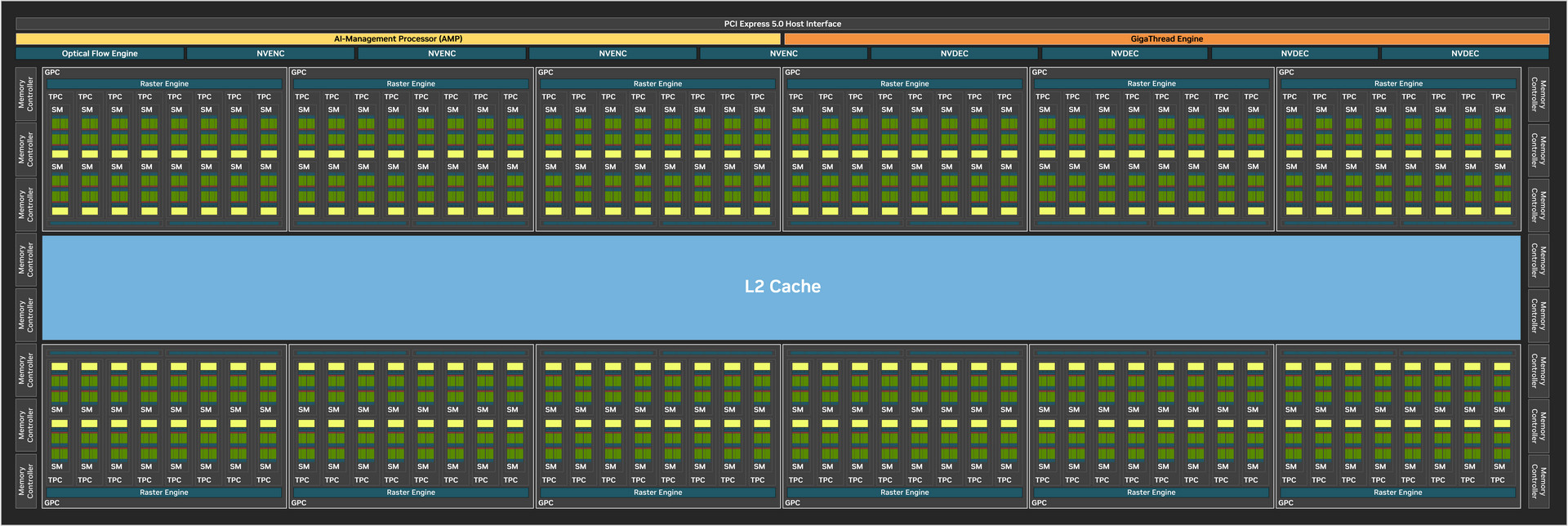
↑ 完整 GB202 GPU 區塊圖。
而 RTX 5090 與 RTX 5080 都採用 Blackwell GB202 GPU,完整版 GB202 具備 12 組 GPC(Graphics Processing Clusters)、96 組 TPC(Texture Processing Clusters)、192 組 SM(Streaming Multiprocessors)與 512-bit 記憶體介面(共 16 個 32-bit 記憶體控制器)。
GPC 做為主要的硬體區塊,具備專用的光柵化(Raster Engine)、2 個 ROP 分區(Raster Operations)每個分區各有 8 個獨立 ROP 單元,以及 8 組 TPC 單元,每組 TPC 之下具備 2 組 SM 單元;而 GB202 有著 128MB L2 快取,至於 RTX 5090 則是 96MB L2 快取。
NVIDIA SM 是 GPU 平行運算的主要核心,內部包含著 CUDA、Tensor 與 RT 等核心,每個 SM 單元具備 128 個 CUDA 核心、1 個 RT Core、4 個 Tensor Core、4 個 Texture 單元,以及 256KB Register File 暫存器與 128KB的L1 共享記憶體。
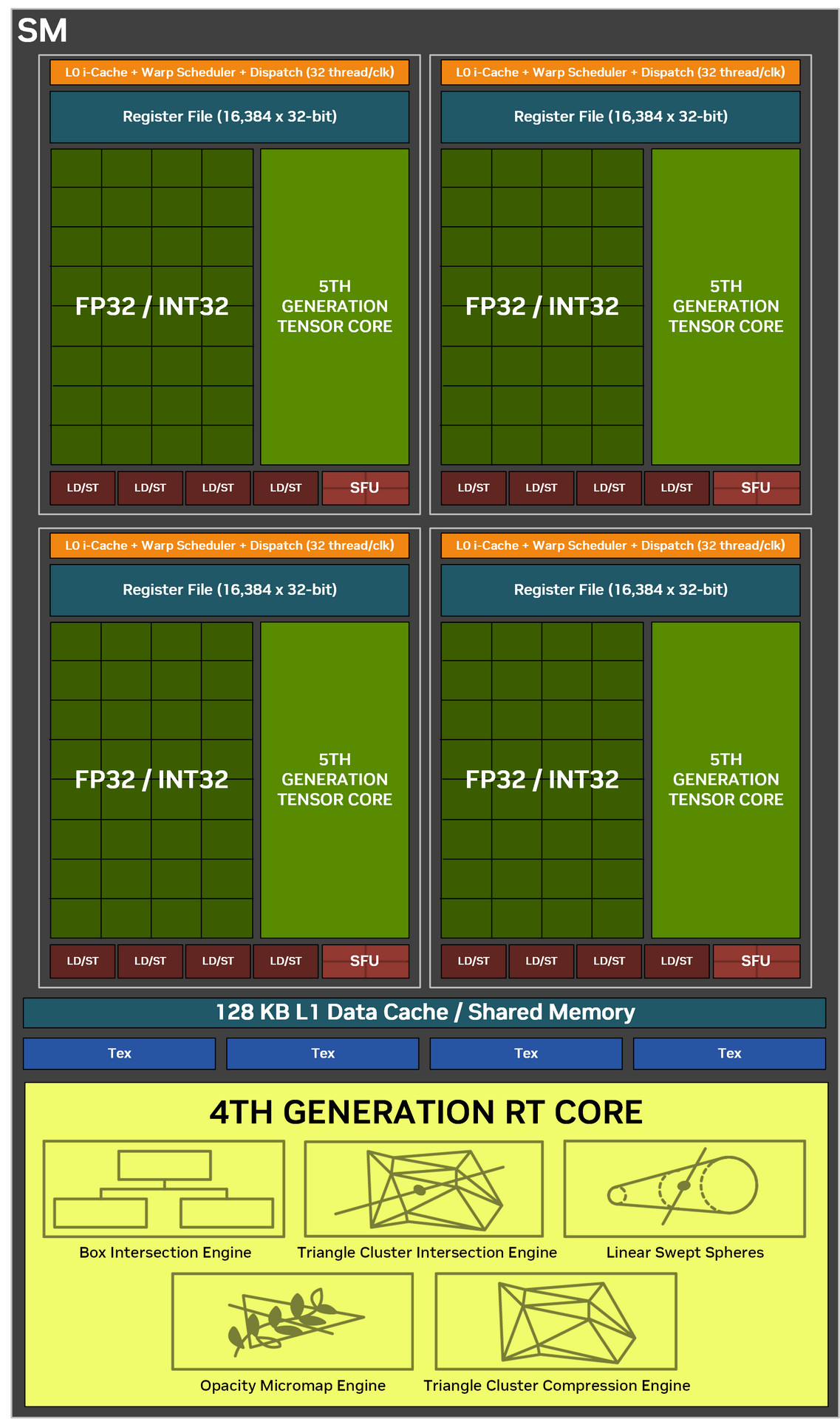
↑ SM 單元區塊圖。
此外,Blackwell SM 改用統一的 FP32/INT32 核心,意味著核心每週期可做為 FP32 或 INT32 的運算;同時 SM 當中的 Texture 單元也跟著提升。
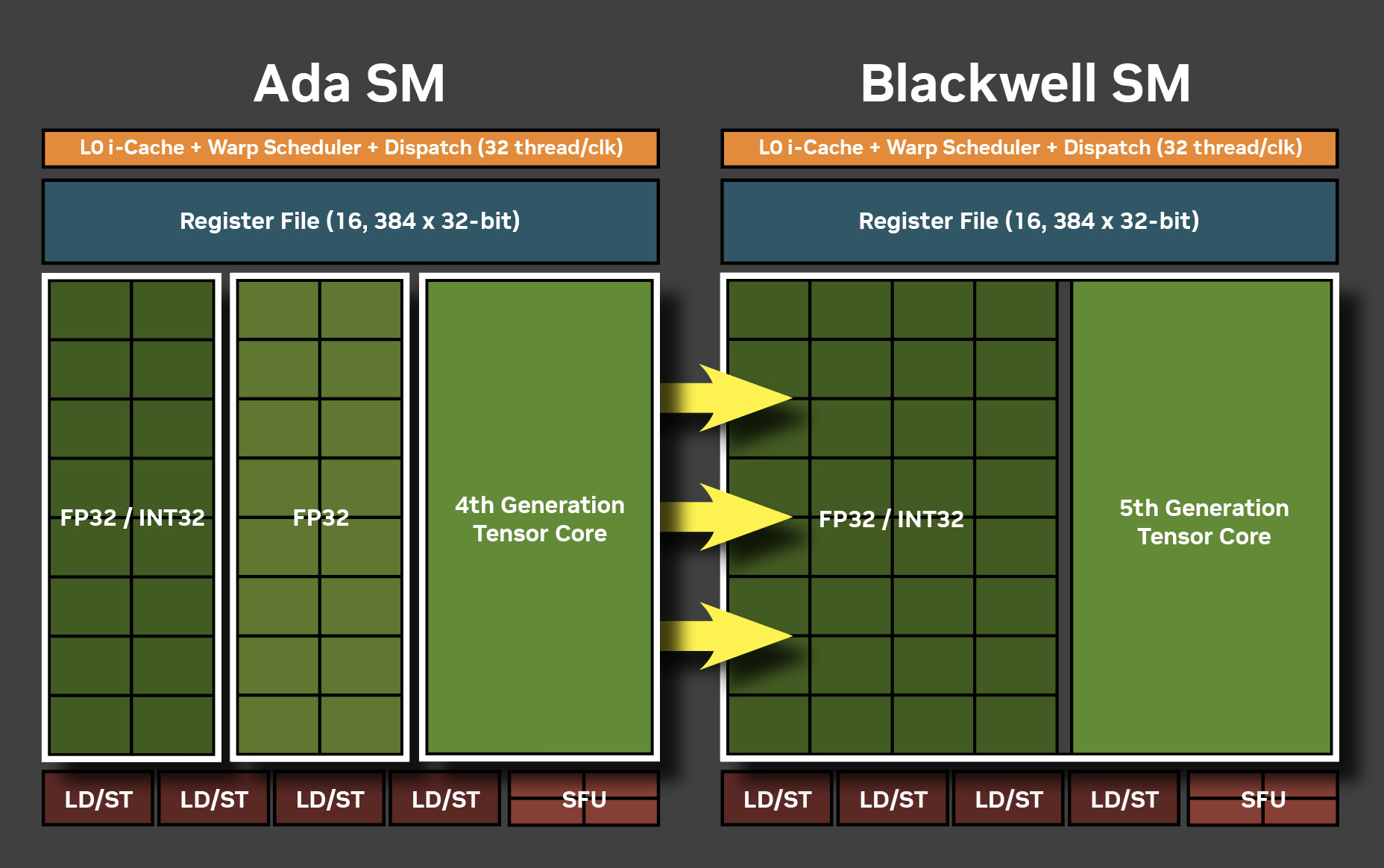
↑ Blackwell SM 統一 FP32/INT32 核心。
NVIDIA 一直以來與 Micron 和 JEDEC 協會合作,在 RTX 50 系列 GPU 採用 GDDR7 視訊記憶體,基於 PAM3 編碼方式三個電壓位階、1.5bit/cycle,能有更高的時脈更低的電壓表現。GDDR7 的資料傳輸率是當時 GDDR6 的兩倍,且每 bit 能源消耗也是 2x 倍的降低(更省電)。

↑ GDDR7 視訊記憶體。
這代加入的 RTX Neural Shaders 與微軟合作,DirectX 也將支援 Cooperative Vectors,讓遊戲開發者可以更容易解鎖 Tensor Core 的運算效能。開發者可藉由 Slang 渲染程式語言針對遊戲資料與渲染程式碼進行訓練,即時的藉由 NVIDIA Tensor Cores 來進行訓練神經網路的表現與權重,而且在訓練過程中經由神經網路生成的資料會與傳統資料比較,並在多個週期中細化神經網路的表現。
但這需要遊戲引擎支援,因此目前 RTX 50 玩家還未能體驗到,而 RTX Neural Shaders 可以利用在:RTX Neural Texture Compression、RTX Neural Materials、RTX Neural Radiance Cache、RTX Skin 等渲染應用當中。通過 RTX Neural Shaders 技術,可以獲得更出色的影像材質、材料與光線等表現,而且可以有效降低傳統渲染所需的記憶體使用量。
此外,這代也帶來 Mega Geometry API 與架構支援,以及讓 RT Core 更好追蹤頭髮光線的 Linear Swept Spheres(LSS)。並可通過 API 控制的 Shader Execution Reordering (SER) 2.0,讓開發人員更好調度 GPU 平行運算能力。
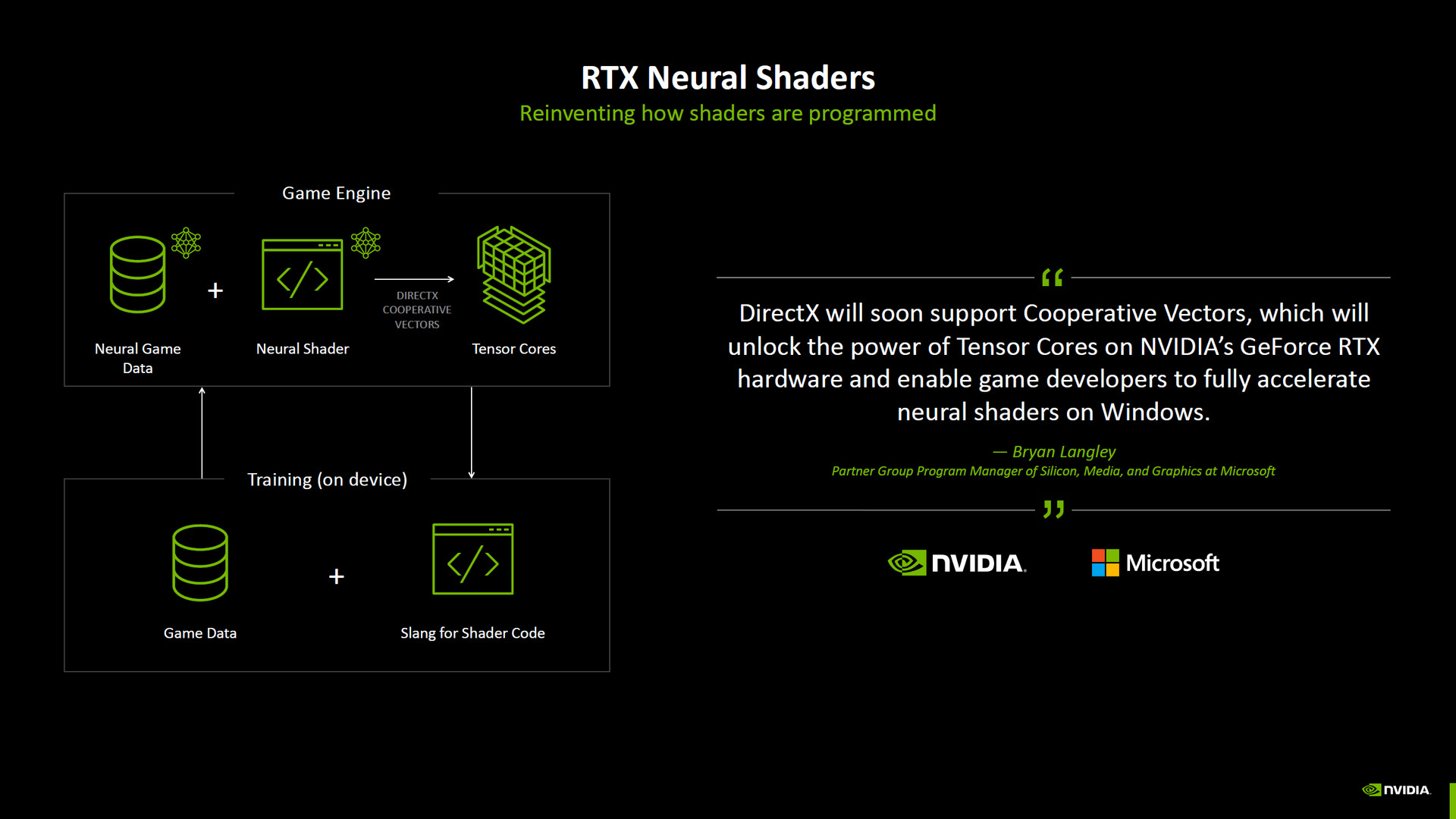
↑ RTX Neural Shaders。
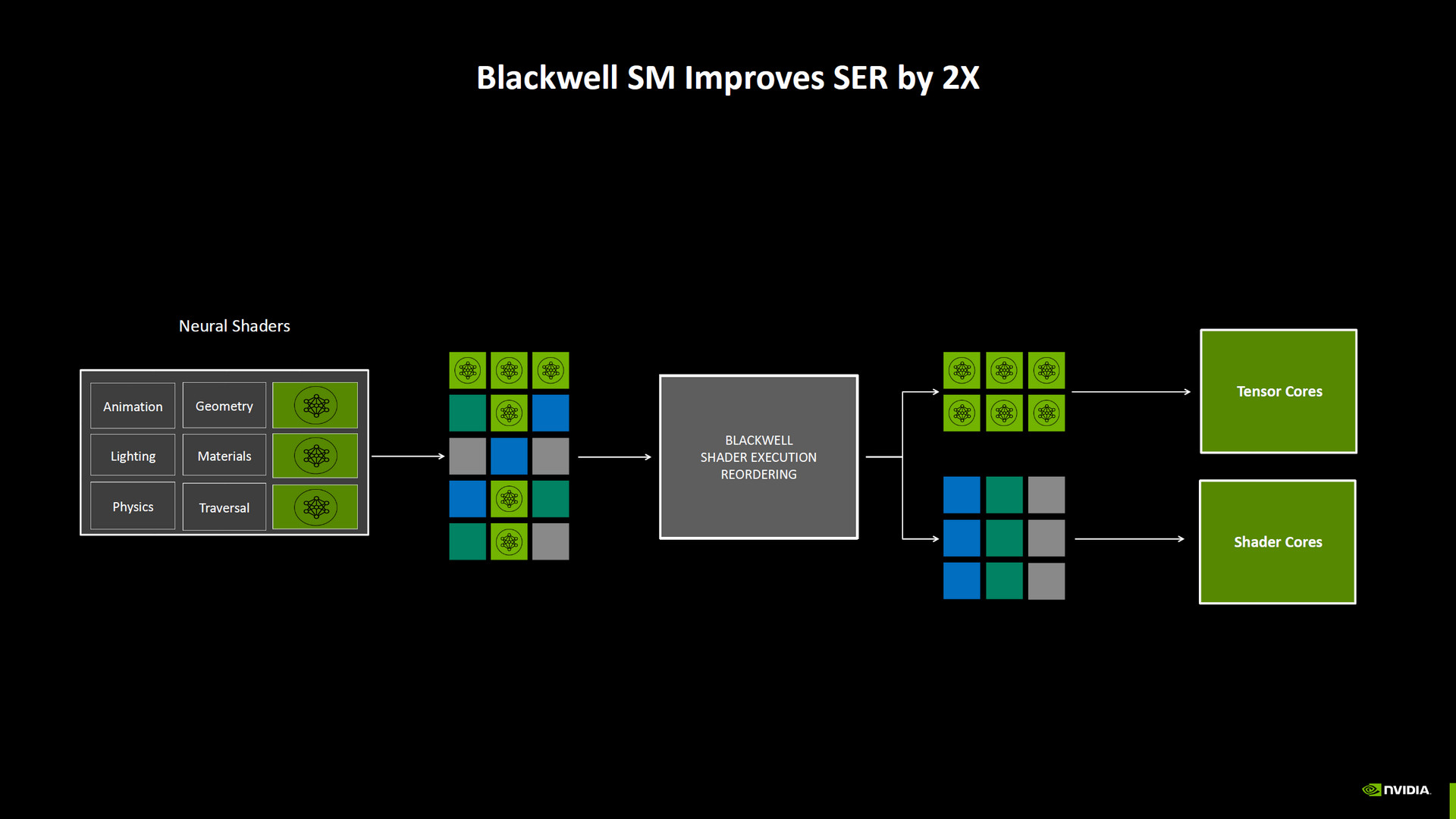
↑ Shader Execution Reordering (SER) 2.0。
8x 倍提升的 DLSS 4 多畫格生成與 Flip Metering
NVIDIA 提到新一代 DLSS 4 多畫格生成技術,會自動啟用 Reflex 2 Frame Warp 功能,當遊戲透過神經網路運算生成遊戲影像提升 FPS,也可保證遊戲有著極低的延遲表現。
首先遊戲最原始渲染的影像,通過 DLSS Super Resolution(SR)超解析度提升畫質,以及利用 Ray Reconstruction(RR)加強光追下的表現,並通過下一代 DLSS Frame Generation 多畫格生成搭配 AI Optical Flow 兩個神經網路生成未來的 Generated Fram 1 遊戲影像。
而原始畫面要更新到 Generated Fram 1 時會使用 Blackwell 硬體的 Flip Metering 確保影像順暢,而接下來的生成 Generated Fram 2 時也會依據神經網路與遊戲輸入來調整生成的畫面,並搭配 Flip Metering 來更新顯示遊戲影像。
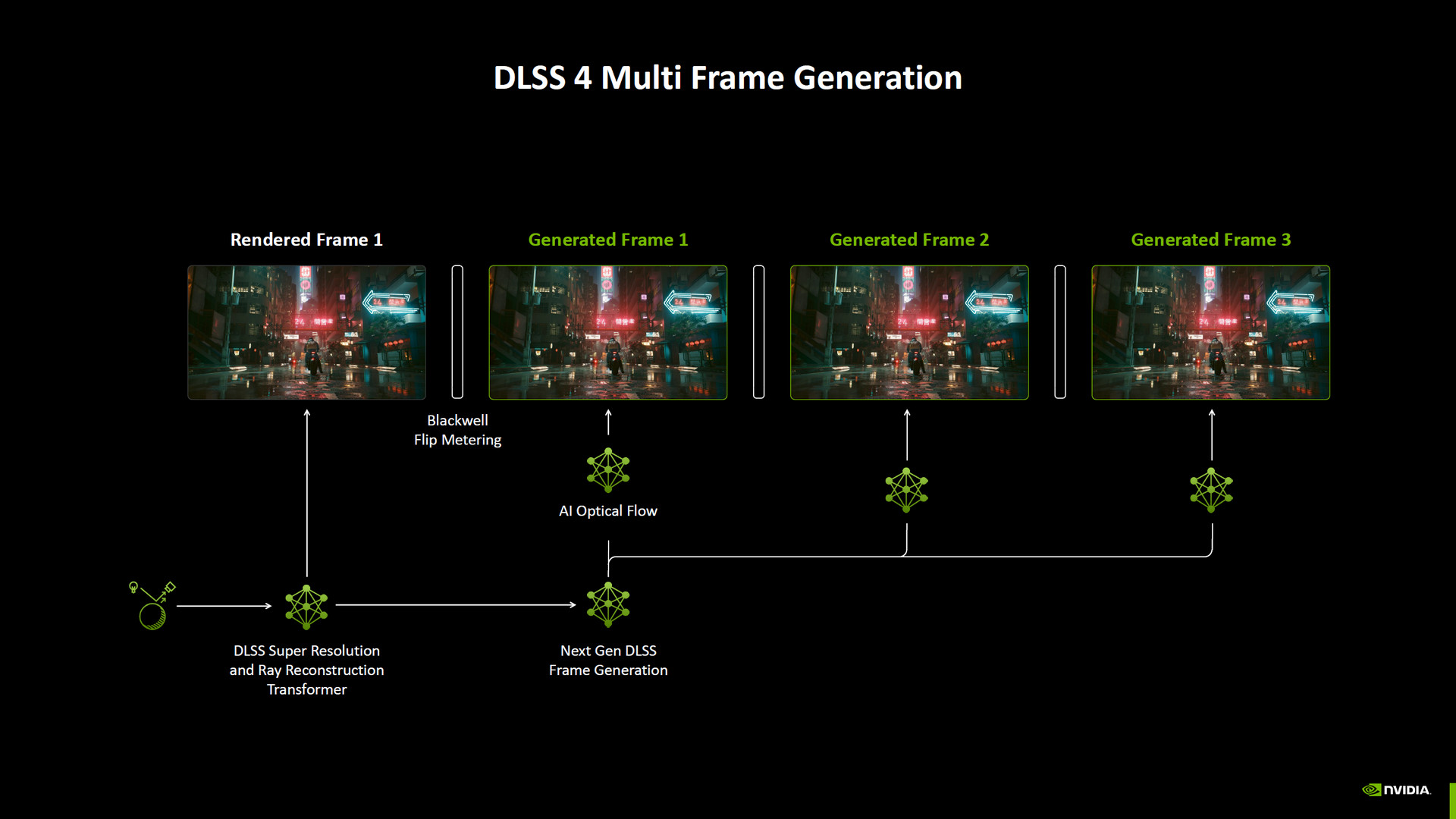
↑ DLSS 4 多畫格生成。
如此一來 DLSS 4 多畫格生成,只需渲染 1/16 的影像,就可以靠著 AI 進行 DLSS Super Resolution 與 Ray Reconstruction 生成 3/16 的影像,而這張 4/16 的影像可生成出未來的三格畫面,達到 15/16 的畫格全透過 AI 生成。(簡單說,就是 4 格畫面分成 4 份,相當於 DLSS 性能模式。)
讓遊戲效能可達到 8x 倍的效能提升,只不過 DLSS 4 則是 RTX 50 系列 GPU 獨佔的功能。

↑ 4 格畫面分成 4 份,相當於 DLSS 性能模式。

↑ DLSS 歷代加速提升。
DLSS 加速 Transformer 的 AI 模型與 NVIDIA App Override 設定
DLSS 通過 6 年的不斷學習,在遊戲、渲染運算等應用中大放異彩,而在 RTX 50 推出之際 NDIIA 也著手將 DLSS 使用的 CNN 模型升級成 Transformers 模型,而這升級是所有 RTX 用戶都能啟用,只要 NVIDIA App 應用開放就能手動 Override 調整 AI 模型設定。

↑ DLSS 升級 Transformers 模型。
DLSS 將採用 Transformers 模型,能夠帶來更高的參數與運算量,並且在 Super Resolution 超解析度與 Ray Reconstruction 的畫面生成時有著更細緻的影像呈現,而且實際測試下遊戲效能也會因為 Transformers 模型而有些許的提升。
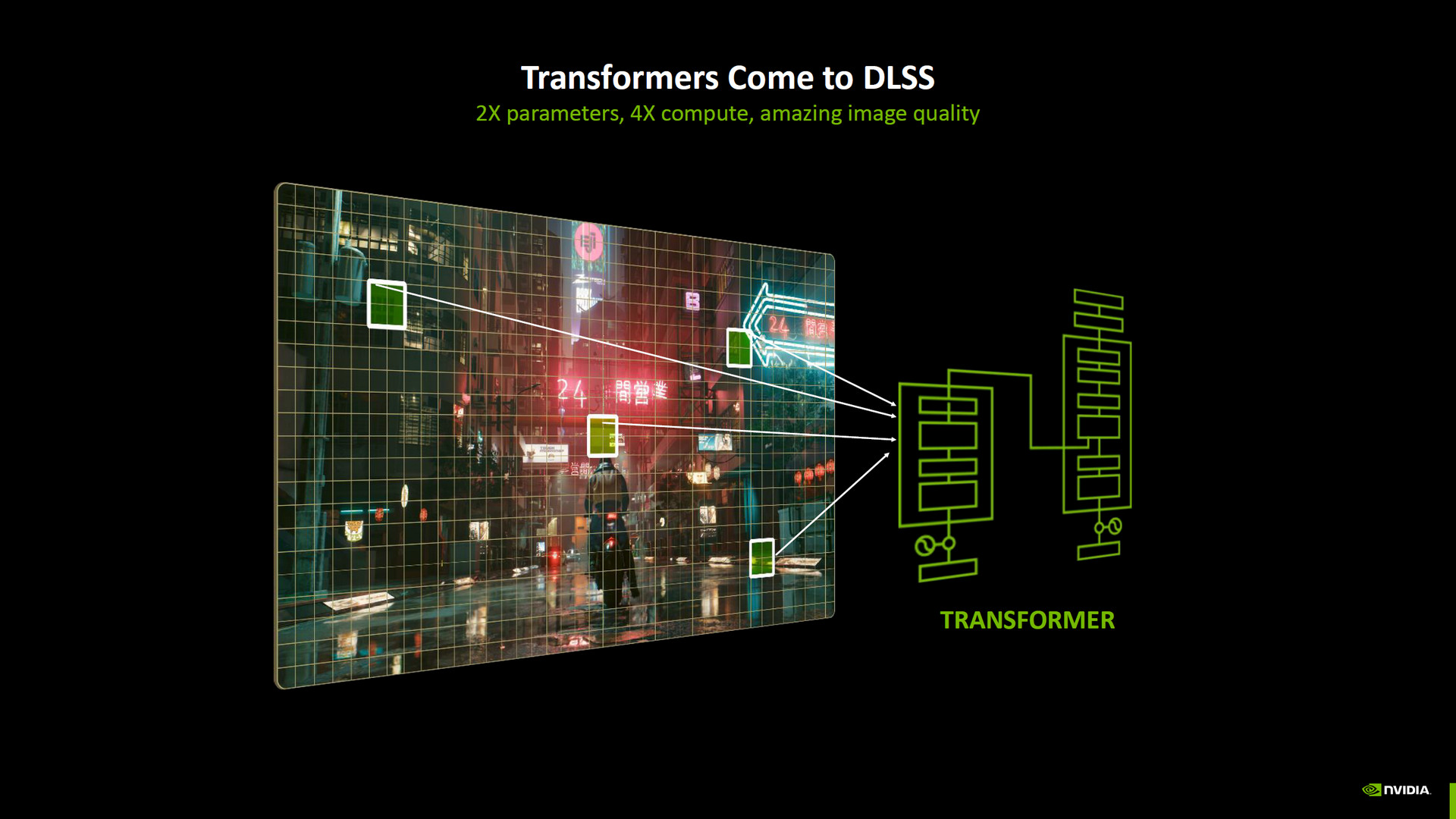
↑ Transformers 模型帶來更高的參數與運算量。

↑ 讓光線重構有著更好的細節。

↑ 超解析度的細節也有著提升。
DLSS 4 更新了整個 DLSS 的 5 大技術,像是 DLSS Multi Frame Generation 多畫格生成、DLSS Frame Generation 單畫格生成、DLSS Ray Reconstruction 光線重構、DLSS Super Resolution 超解析度與 Deep Learning Anti-Aliasing(DLAA)等功能。
主要的 DLSS Multi Frame Generation 多畫格生成是 RTX 50 系列獨享的功能;而 DLSS Frame Generation 單畫格生成則有著強化升級,能夠提生效能與降低記憶體使用率,這功能 RTX 50 與 RTX 40 都支援;至於 DLSS Super Resolution 超解析度強化版與 DLAA 強化版,都是針對動態影像的穩定度與細節有提升,並支援所有 RTX GPU 系列(改用 Transformers 模型)。
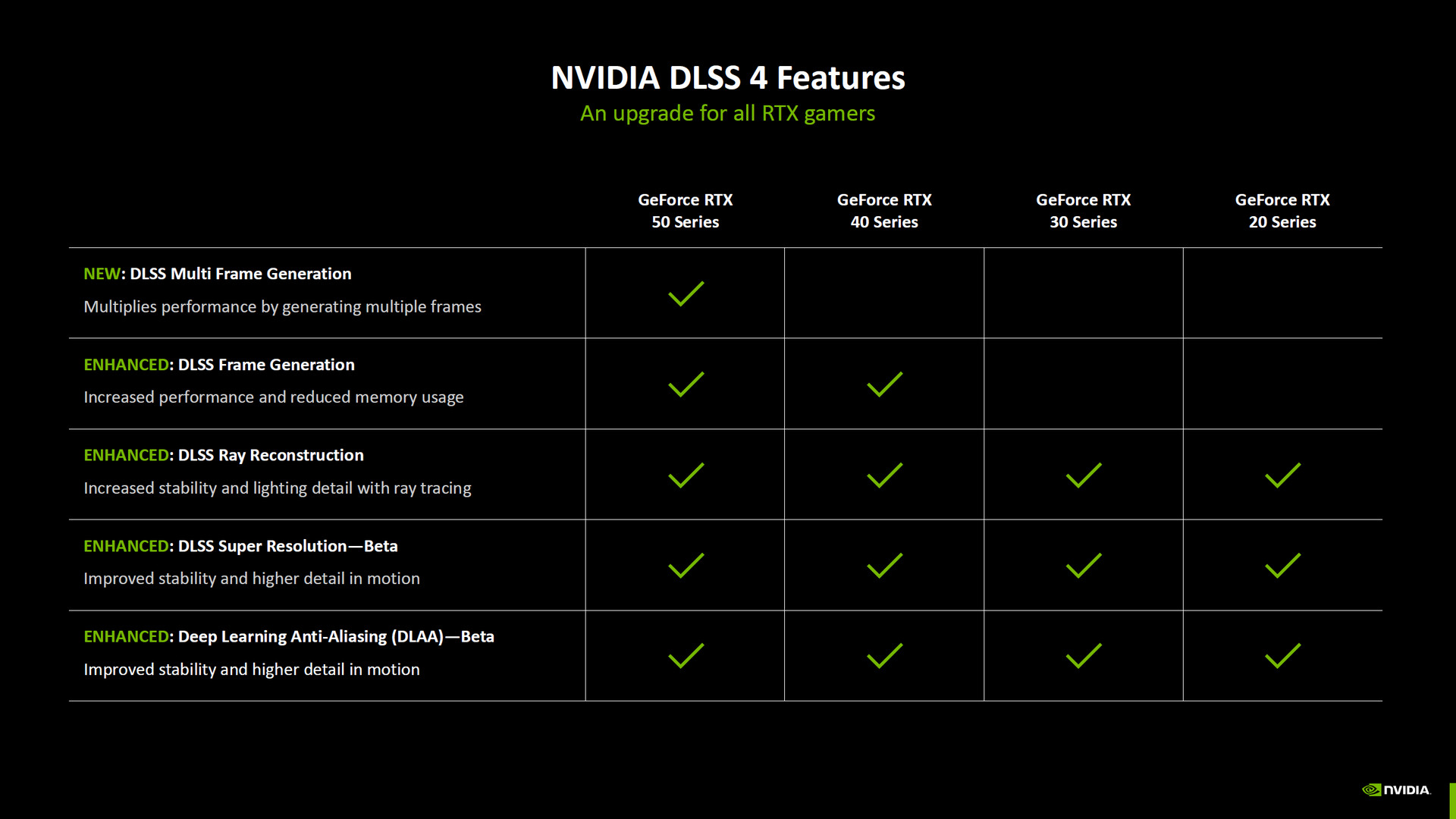
↑ DLSS 4 功能對應 RTX 世代。
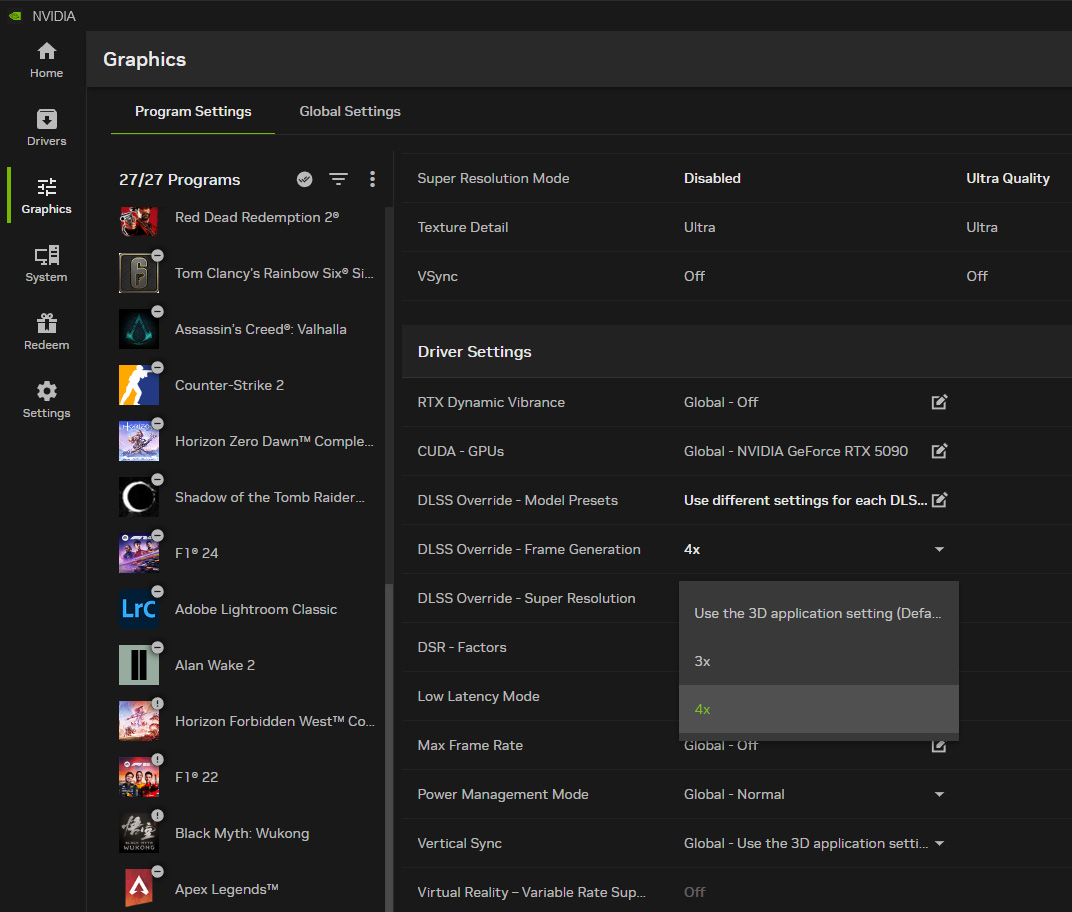
↑ 支援 Override 的程式,在 NVIDIA App 中可找到 FG 與 SR 設定。FG 2x 等於 DLSS 3,設定成 4x 才是 DLSS 4。
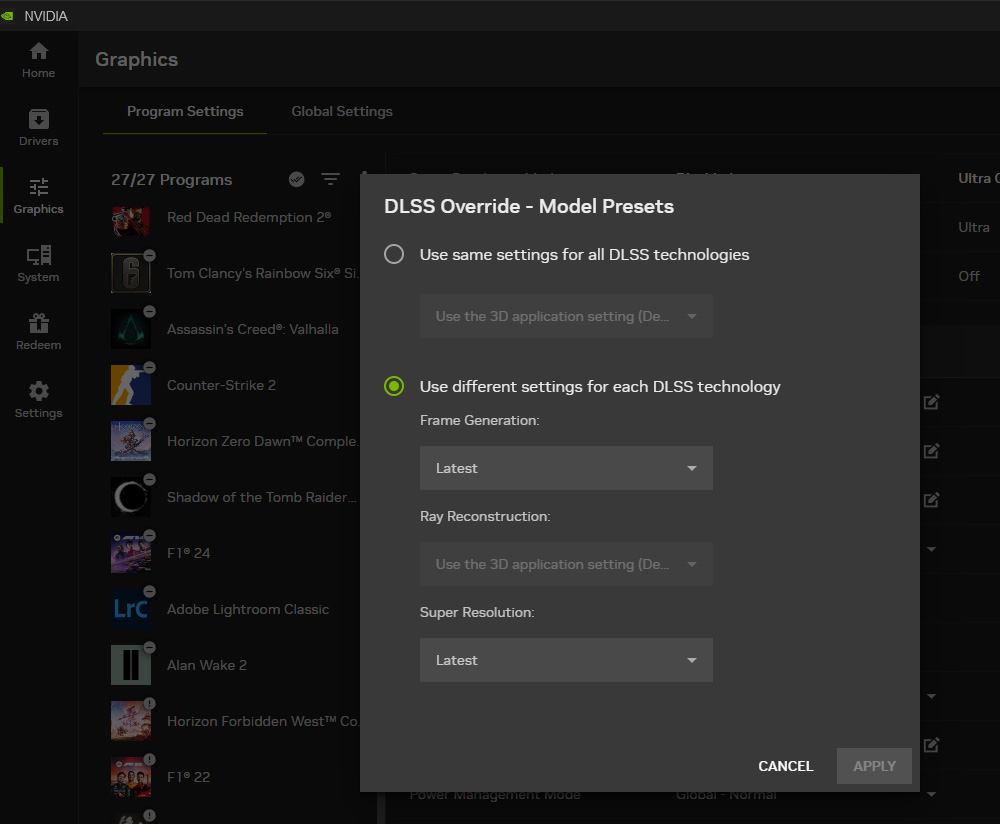
↑ 而 DLSS Override 設定為 Latest 即是最新的 Transformers 模型。
NVIDIA Reflex 2 與 Frame Warp
NVIDIA 低延遲技術 Reflex 2 採用「Frame Warp」新技術,這功能主要是演算法的改變,因此所有 RTX GPU 都能啟用這功能,但是 RTX 50 系列會優先支援。
簡單來說,NVIDIA Reflex 2 的 Frame Warp 功能,是指當 GPU 已經渲染好影像後隨著滑鼠移動,需要重新渲染整個畫面的空間,但套用「Frame Warp」技術則是直接移動原本渲染好的畫面,並通過前一幀的影像、顏色資料與深度資料,將空白的畫面 InPainting 填滿。
如此一來,啟用 Reflex 2 可帶來 75% 的延遲降低,而且當玩家使用 DLSS 4 多畫格生成時會強制啟動 Reflex 2 的功能。
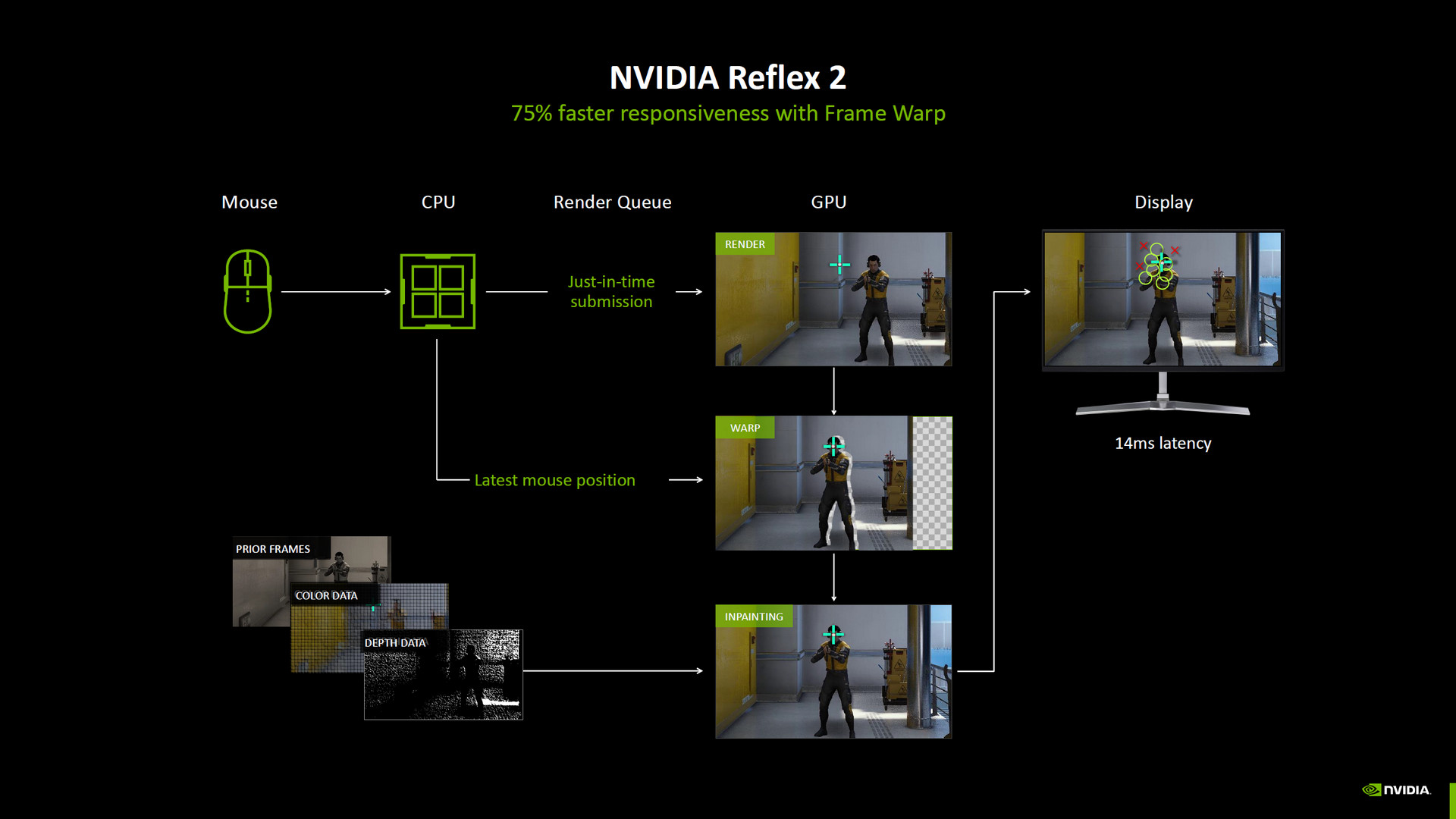
↑ Reflex 2。

↑ InPainting 補齊畫面。
NVIDIA GeForce RTX 5090 創始版顯示卡開箱
這代 RTX 50 系列創始版開創「雙穿透氣流」的獨特設計,採用均溫板、熱導管、散熱鰭片與雙風扇,讓創始版僅 304 x 137 mm 與 2-Slot 兩槽厚度,即可替 RTX 5090 最高 TGP 575W 進行散熱,這頂級的散熱設計難道不是購買創始版的最佳理由嗎?
首先外箱紙盒則相當低調,手撕的封條拆開後就會看到「Inspired by Gamers. Enhanced by AI. Built by NVIDIA.」這句話,這也反映出現在的行業現況,遊戲與玩家密不可分相互啟發與影響,而現代即時光線追蹤或實做全景光線的遊戲,則都需要透過 AI 超解析度、畫格生成等方式強化影像,最後則使用 NVIDIA 打造的 GPU 執行遊戲。

↑ Inspired by Gamers. Enhanced by AI. Built by NVIDIA.。

↑ 更環保的包裝,內盒則是象牙白的瓦楞紙板盒。
GeForce RTX 5090 FE 創始版,開創獨特的「雙穿透氣流」的設計,外觀與上一代 RTX 4090 創始版有點像,維持著獨特的 X 框架與全金屬材料打造,但整體線條更佳圓潤有細節,兩組大面積的散熱鰭片縝密排列。
顯卡正面,則有著兩顆 11.5cm、軸向式風扇,藉由縮短置中的電路板,讓兩顆風扇的氣流可穿透顯示卡。但也多增加底部 PCIe 電路板與後方顯示輸出電路板,通過強化的結構設計滿足高頻寬的連接需求,並確保顯卡水平安裝時的強度。

↑ RTX 5090 創始版背面。

↑ RTX 5090 創始版正面。

↑ 縮短的電路板置於顯卡中央,通過均溫板、熱導管、散熱鰭片與雙風扇解熱,讓顯卡有著雙穿透氣流。
顯卡側面,則有著 90° 斜開的 PCIe 12V-2×6 供電接頭,會這樣設計主要是可以節省電路板佔用空間,搭配原生線材連接時也可比較容易走線,但相對的比較容易遮住側面的 GEFORCE RTX 字樣燈效。

↑ PCIe 12V-2×6 供電接頭。

↑ RTX 5090 使用 PCIe 5.0 x16 介面。
顯示輸出,則提供 3 個 DisplayPort 2.1b UHBR20 支援 4K 480Hz 或 8K 165Hz DSC,以及 1 個 HDMI 2.1b 支援 4K 480Hz 或 8K 120Hz DSC 和 Gaming VRR、HDR 等功能。
不過在同時使用 4 個螢幕輸出時,最高解析度為 4 個 4K 165Hz(DP 或 HDMI),若是 2 個螢幕輸出時最高可提升到 4K 360Hz 或 8K 100Hz DSC(DP 或 HDMI)等規格。

↑ 顯示輸出。
RTX 50 系列創始版提供的是新版「PCIe 12V-2×6 柔軟編織 PCIe 8pin 轉接線」,RTX 5090 需要使用 4 個 PCIe 8pin 轉 PCIe 12V-2×6。而新版接頭的編織線柔軟度相當高,且在接頭處還多了一層保護,確保玩家裝機理線時不會影響接頭的密合度。

↑ PCIe 12V-2×6 柔軟編織 PCIe 8pin 轉接線。

↑ 新接頭。

↑ 接頭出現處保護。
NVIDIA GeForce RTX 5090 創作影音輸出、GPU 渲染效能測試
此次測試包含創作 DaVinci Resolve 19、Procyon AI 生成、Blender 與 V-Ray 等創作測試,遊戲則以 2160p、1440p 解析度、特效全開測試電競、AAA 遊戲與光追遊戲的效能,並將 DLSS 4 單獨測試,讓玩家更能瞭解 RTX 5090 相比前一代 RTX 4090 的效能提升。

↑ 測試使用 Seasonic VERTEX 限量青龍 PX 1200W 電源供應器。
測試平台
處理器:AMD Ryzen 7 9800X3D
主機板:ROG CROSSHAIR X870E HERO
記憶體:G.Skill DDR5-6000 16GBx2
顯示卡:NVIDIA GeForce RTX 5090 創始版、NVIDIA GeForce RTX 4090 創始版
系統碟:Solidigm P44 Pro 1TB PCIe 4.0 SSD
散熱器:ROG RYUJIN II 360
電源供應器:Seasonic VERTEX 限量青龍 PX 1200W
作業系統:Windows 11 Pro 24H2 64bit、Resizable BAR On
驅動版本:NVIDIA 571.86
GPU-Z 還未能檢視 NVIDIA GeForce RTX 5090 資訊,採用 4nm 製程的 GB202 GPU,有著 21760個渲染 CUDA 核心,以及 32607 MB GDDR7(Micron)記憶體,而 GPU 預設時脈 2017 MHz、Boost 2407 MHz。
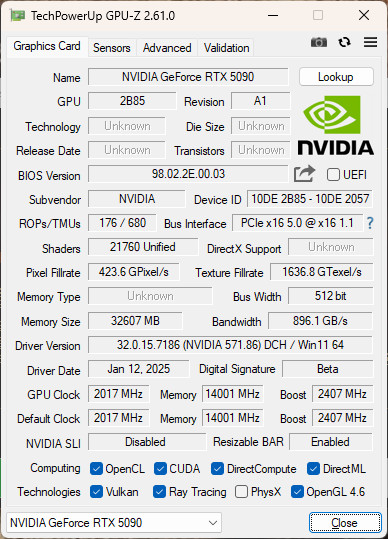
↑ GPU-Z。
DaVinci Resolve 19 純粹通過 GPU 加速的影片剪輯程式,更包含強大的色彩校正與特效功能,並且直接使用 CUDA 核心運算,讓影片剪輯的回放與輸出都有著相當好的性能。測試版本已支援 RTX 50 的 4:2:2 編碼比率。
測試專案是一段 44 秒的小短片,來至於 Blender Open Movie Project《Tears of Steel》,並有著 8k Prores442HQ 30FPS 與 4K Prores422HQ 30FPS 的影片,可用來測試輸出 HEVC 4:4:4 與 4:2:2 的編碼效能差異。
RTX 5090 有著 3 組 NVENC 編碼引擎,在處理 8K30 H.265 4:4:4 編碼輸出時,僅需 1 分 57 秒的時間即可完成影片輸出,相比上一代 RTX 4090 則需要 2 分 17 秒的時間,輸出時間降低 20 秒左右。此外,上一代 RTX 4090 不支援 4:2:2 原生輸出,因此若影音工作主力是 4:2:2 的編碼比,那新一代 RTX 50 確實有著更多優勢。
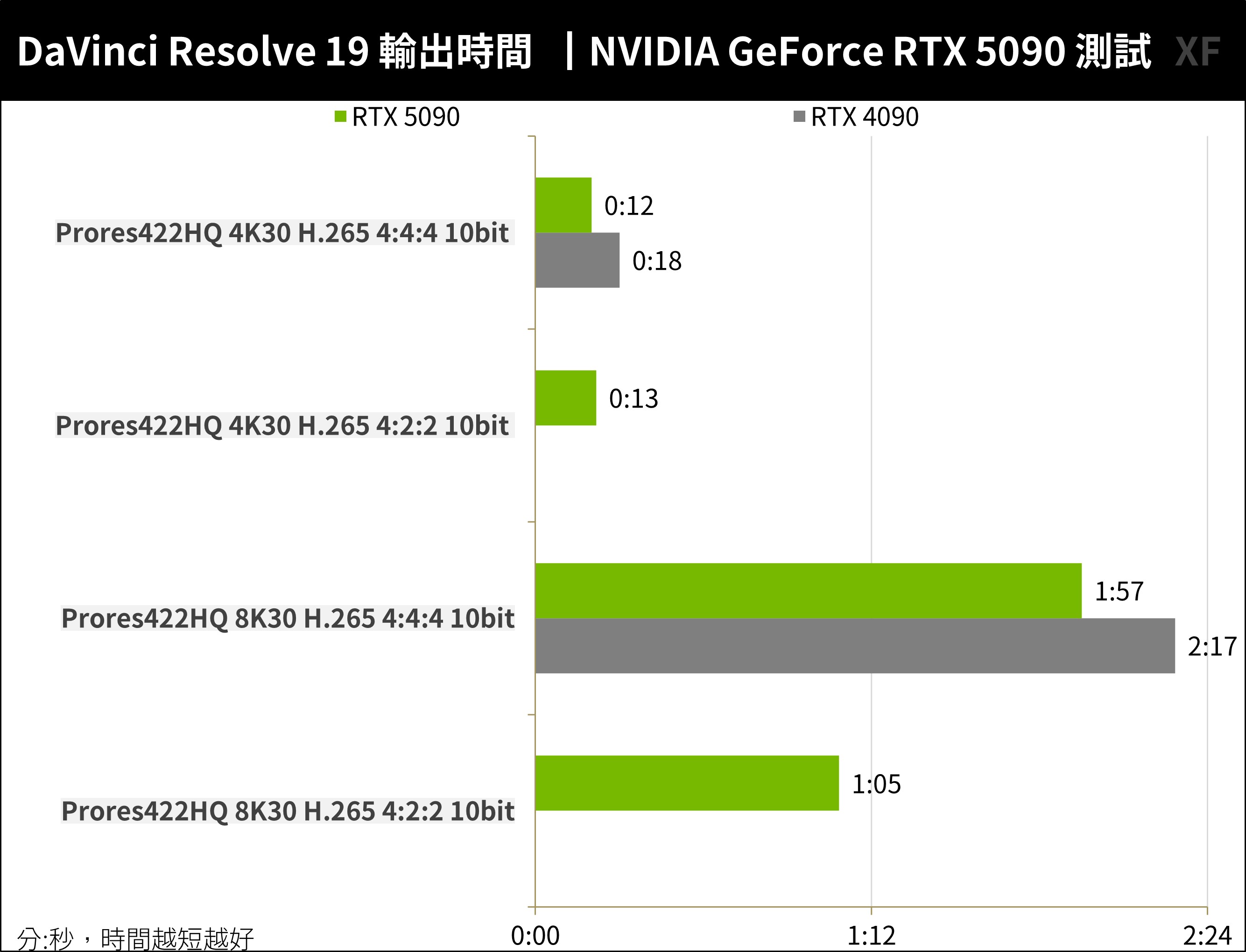
↑ DaVinci Resolve 19 輸出測試。
Blender 是跨平台、開放源碼的 3D 創作工具,支援著各種 3D 作業:Modeling、Rigging、Animation、Simulation、Rendering、Compositing 與 Motion Tracking 等。而測試,則以 Blender Benchmark 3.3.0 進行 Demo 專案的渲染工作測試。
Blender Benchmark 4.3.0 測試,RTX 5090 在三個場景的測試中,每分鐘 Sample 數量約是上一代的 35% 提升。
以同樣的半導體製程單靠 Blackwell 架構更新,能有著樣的實力已相當厲害。
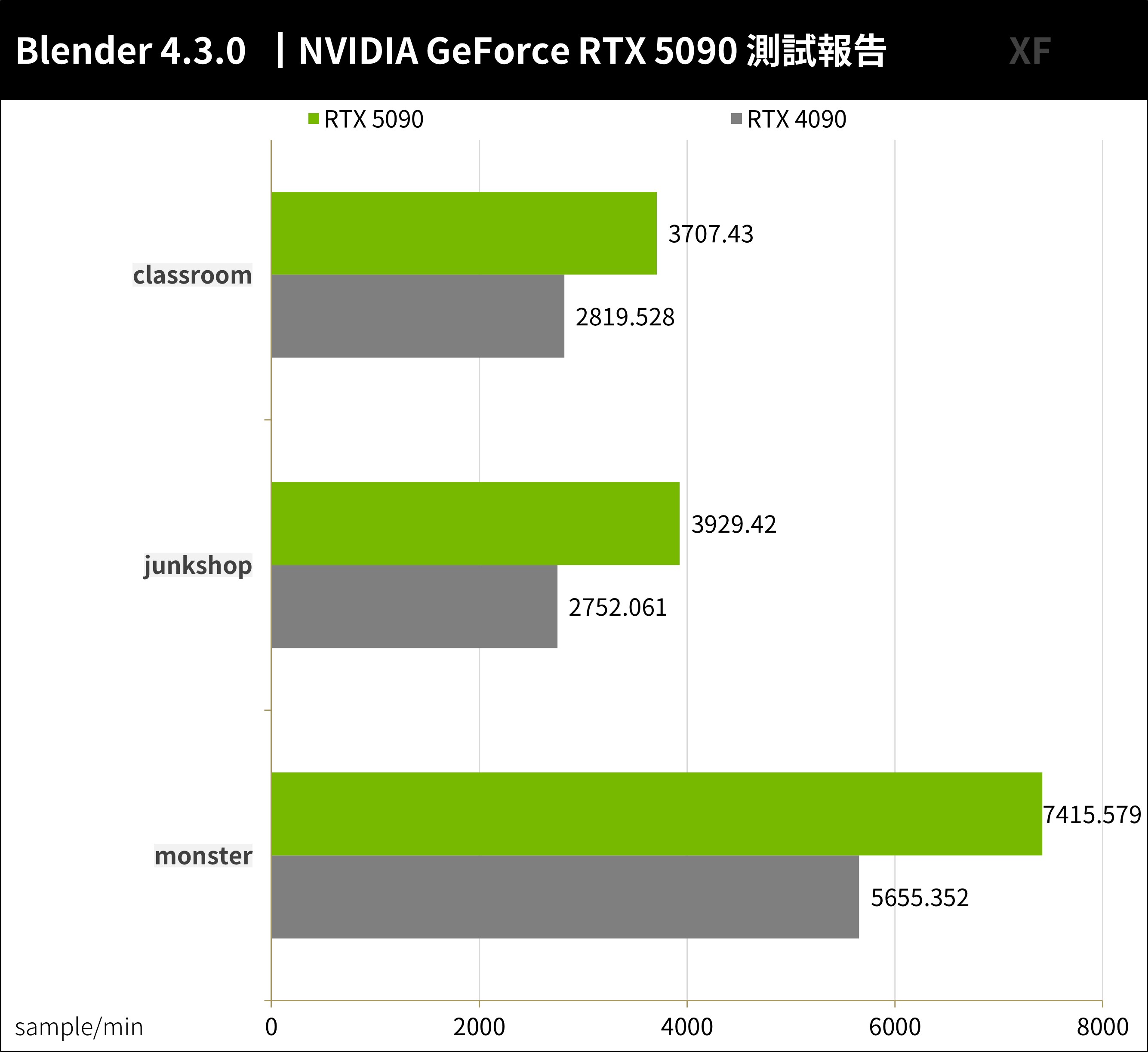
↑ Blender 渲染測試。
V-RAY 6 Benchmark 是由 Chaos Group 所開發,V-Ray 是基於物理法則所設計的光線渲染軟體,而此工具可分別針對 CPU 與 GPU 進行光線追蹤的渲染圖像的運算測試。
通過 RTX 運算,RTX 5090 達到 15206 vpaths 的光線運算量,相比上一代 RTX 4090 有著 38% 的效能提升。
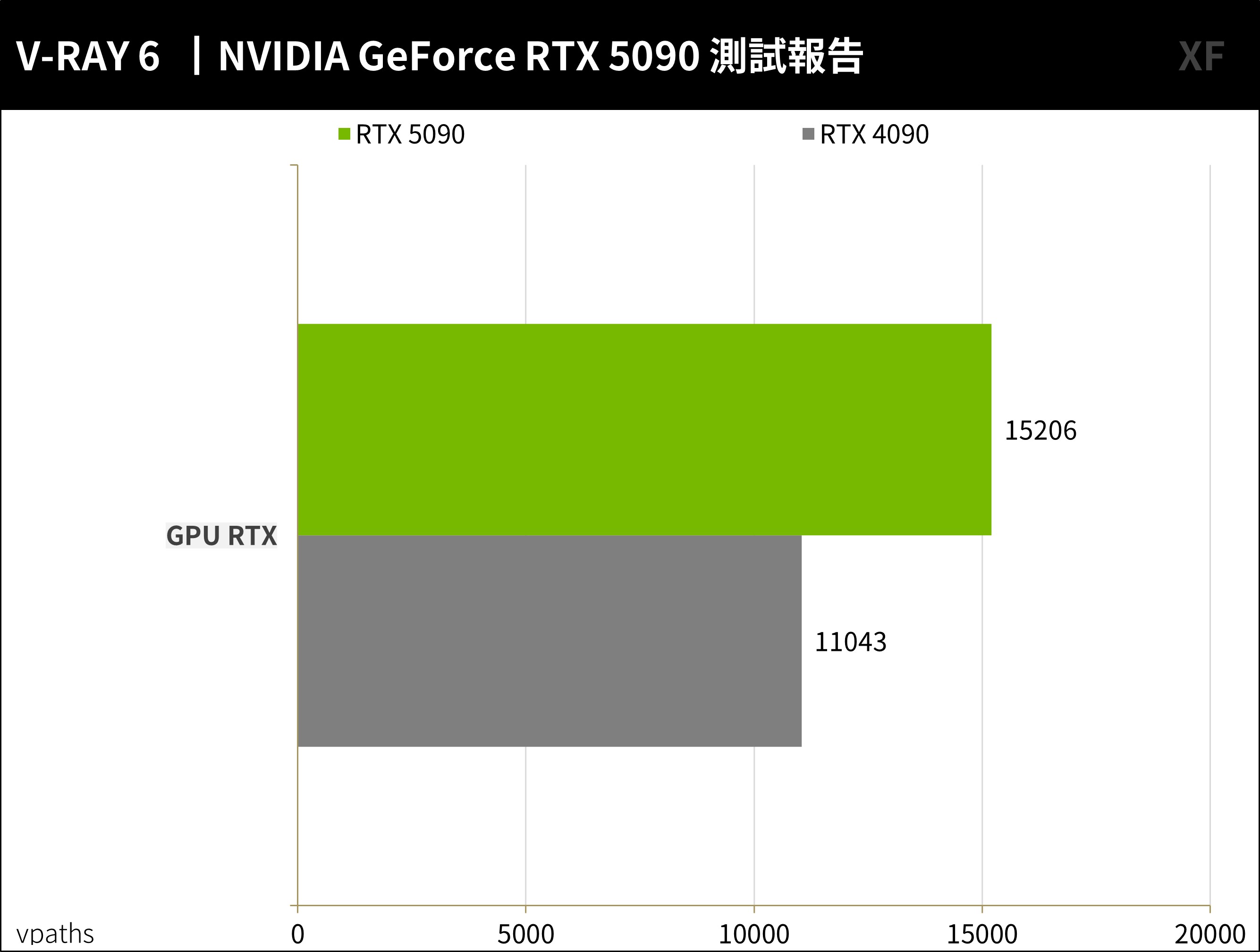
↑ V-RAY 6 Benchmark 渲染測試。
NVIDIA GeForce RTX 5090 – 生成式 AI 測試 IMG、LLM
UL Procyon AI Image Generation Benchmark 提供 Stable Diffusion XL (FP16) 與 Stable Diffusion 1.5 (FP16) 的兩種測試情境,並支援 ONNX runtime with DirectML、NVIDIA TensorRT 與 Intel OpenVINO 的推論引擎。
測試版本目前 Stable Diffusion 還未支援 TensorRT 引擎,並提供新的 FLUX.1 模型支援 FP8 與 FP4 精度與 TensorRT 引擎,可以用來測試新一代 RTX 50 支援原生 FP4 精度的運算效能。上一代或其餘 RTX GPU,一樣可運算 FP4 精度但相對更耗費硬體效能。
RTX 5090 在主流的 Stable Diffusion XL (FP16) 測試中,生成一張圖片僅需 7.278s 秒,而 RTX 4090 則是 9.403s 秒;改用 FLUX.1 FP8 精度,RTX 5090 則需要 6.6s 秒生成影像,而 RTX 4090 則需要 9.3s 秒。
NVIDIA 在 RTX 50 系列加入原生 FP4 精度運算,因此在 FLUX.1 FP4 運算下,RTX 5090 只需 3.9s 秒即可完成,但 RTX 4090 則需要 17.3s 秒的時間。
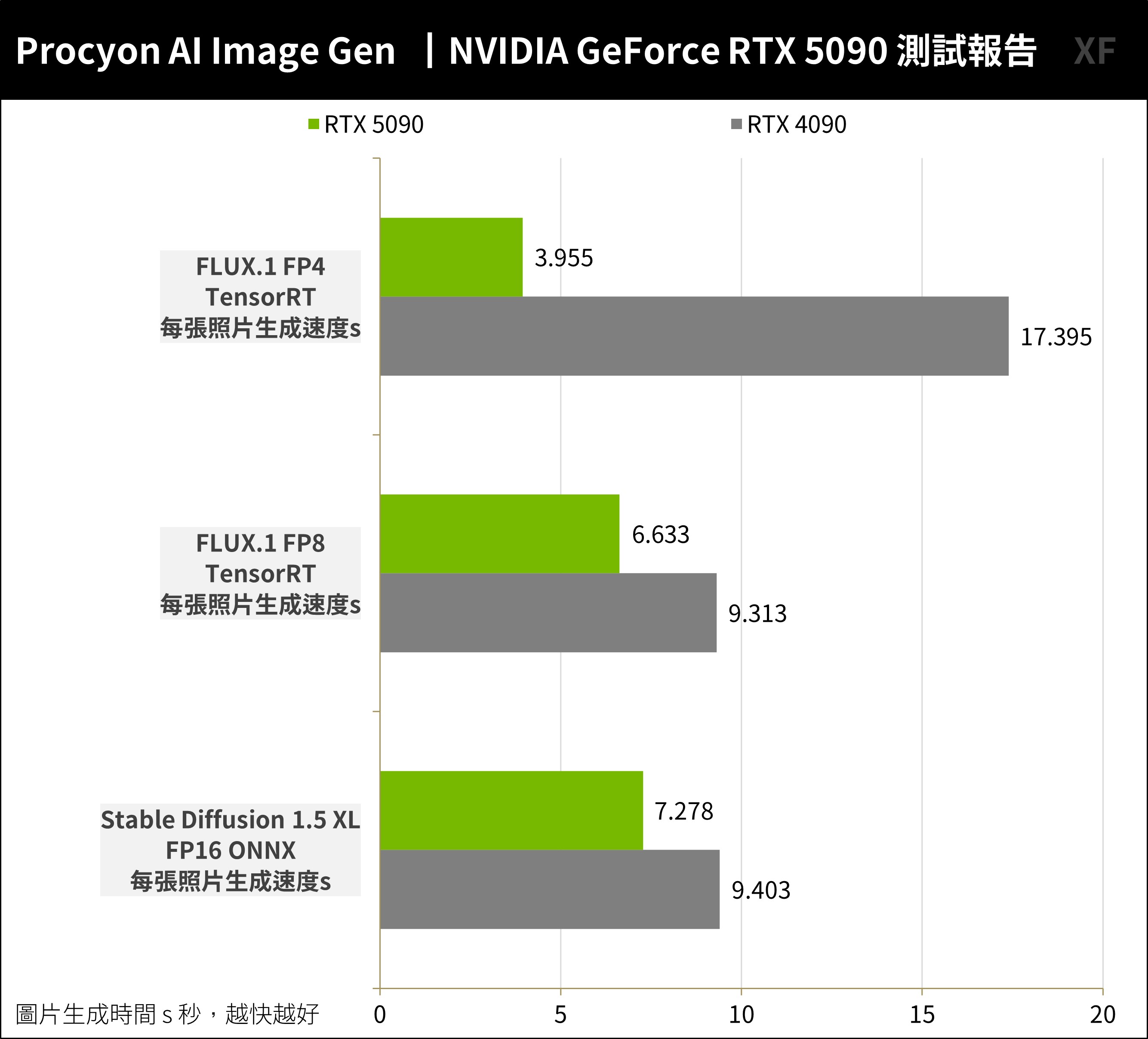
↑ UL Procyon AI Image Generation Benchmark。
UL Procyon AI Text Generation Benchmark 提供 ONNX 模型包含 Phi-3.5-mini、Llama-3.1-8B、Mistral-7B 與 Llama-2-13B 測試,每個模型測試 7 個 Prompts 包含 RAG 與非 RAG 的查詢,通過權重後的總分與平均 Time To First Token(TTFT)、平均 Output Token Speed(OTS)提供專業用戶橫量電腦的 AI LLM 推論效能。
RTX 5090 在 4 個 LLM 測試下比起 RTX 4090 有著平均 32% 的效能提升。
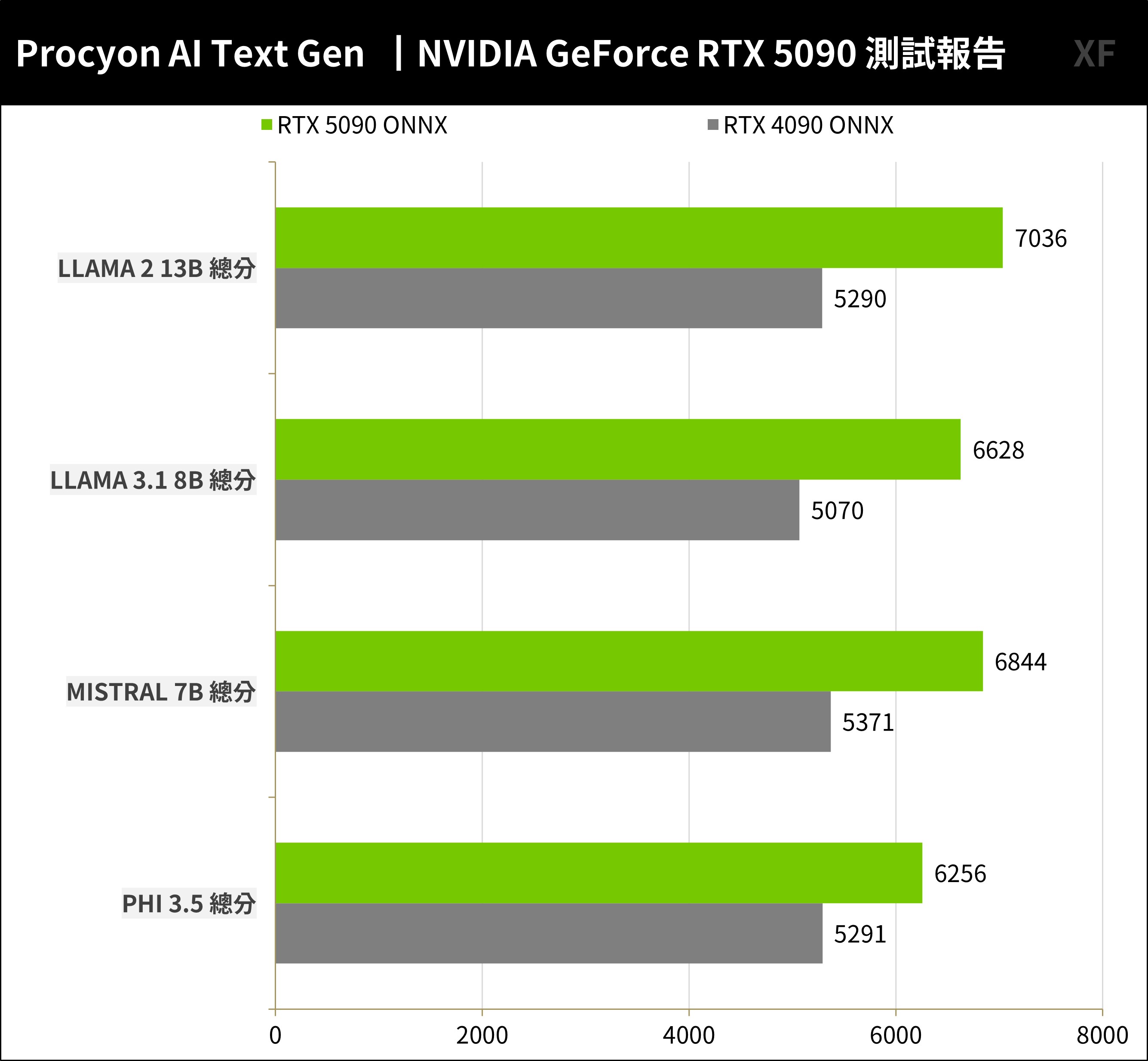
↑ UL Procyon AI Text Generation Benchmark。
NVIDIA GeForce RTX 5090 – 3DMark 跑分效能測試
3DMark Fire Strike 繪圖效能測試,為主流的 DirectX 11 API 的測試情境,分別測試 1080p、Extreme 1440p 與 Ultra 2160p 的效能。3DMark Time Spy 則是採用 DirectX 12 API 所設計的測試情境,同樣是鎖定在 AAA 遊戲等級,分別測試 1440p 與 Extreme 2160p 的效能。
RTX 5090 在 Fire Strike 繪圖達到 105627 分、Extreme 61096 分、Ultra 33068 分的成績,相比 RTX 4090 有著平均 30% 的效能提升。至於 Time Spy 繪圖成績,RTX 5090 獲得 48552 與 Extreme 25336 分,同樣相比 RTX 4090 有著平均 32% 的效能提升。
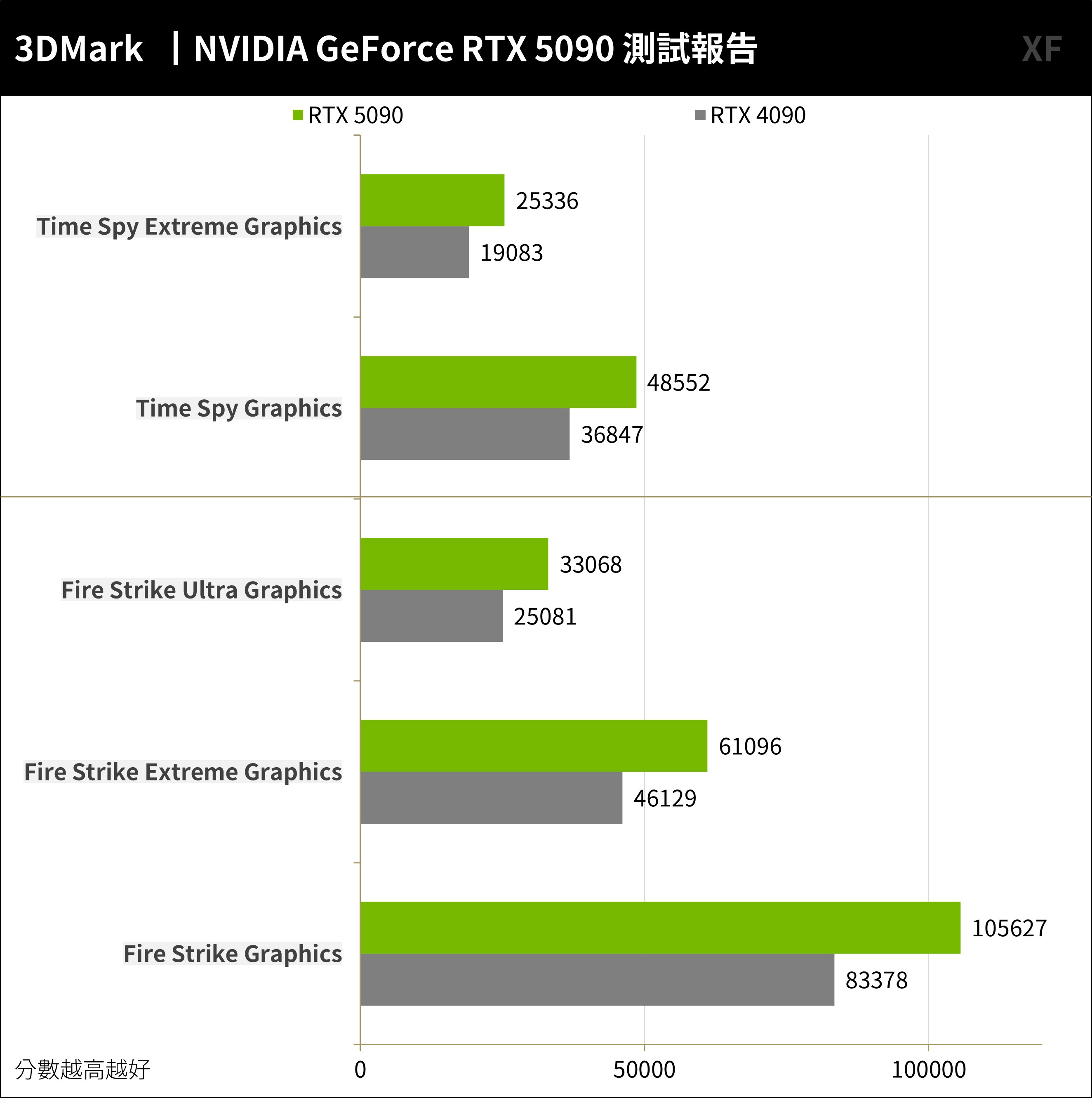
↑ 3DMark。
3DMark 光線追蹤場景測試,像是最早推出的 Port Royal 在 AAA 遊戲中的場景中加入光線追蹤功能,考驗著新一代 GPU 對於硬體光線追蹤加速的能力;以及單獨測試 DirectX Raytracing API 的 DXR 功能測試;最後 Speed Way 則是使用全光線追蹤所開發的測試情境。
RTX 5090 在 Speed Way 與 Port Royal 有著高達 39% 的性能提升;但目前確定 RTX 5090 在 DXR 測試情境效能較低,這之後可透過驅動更新解決。
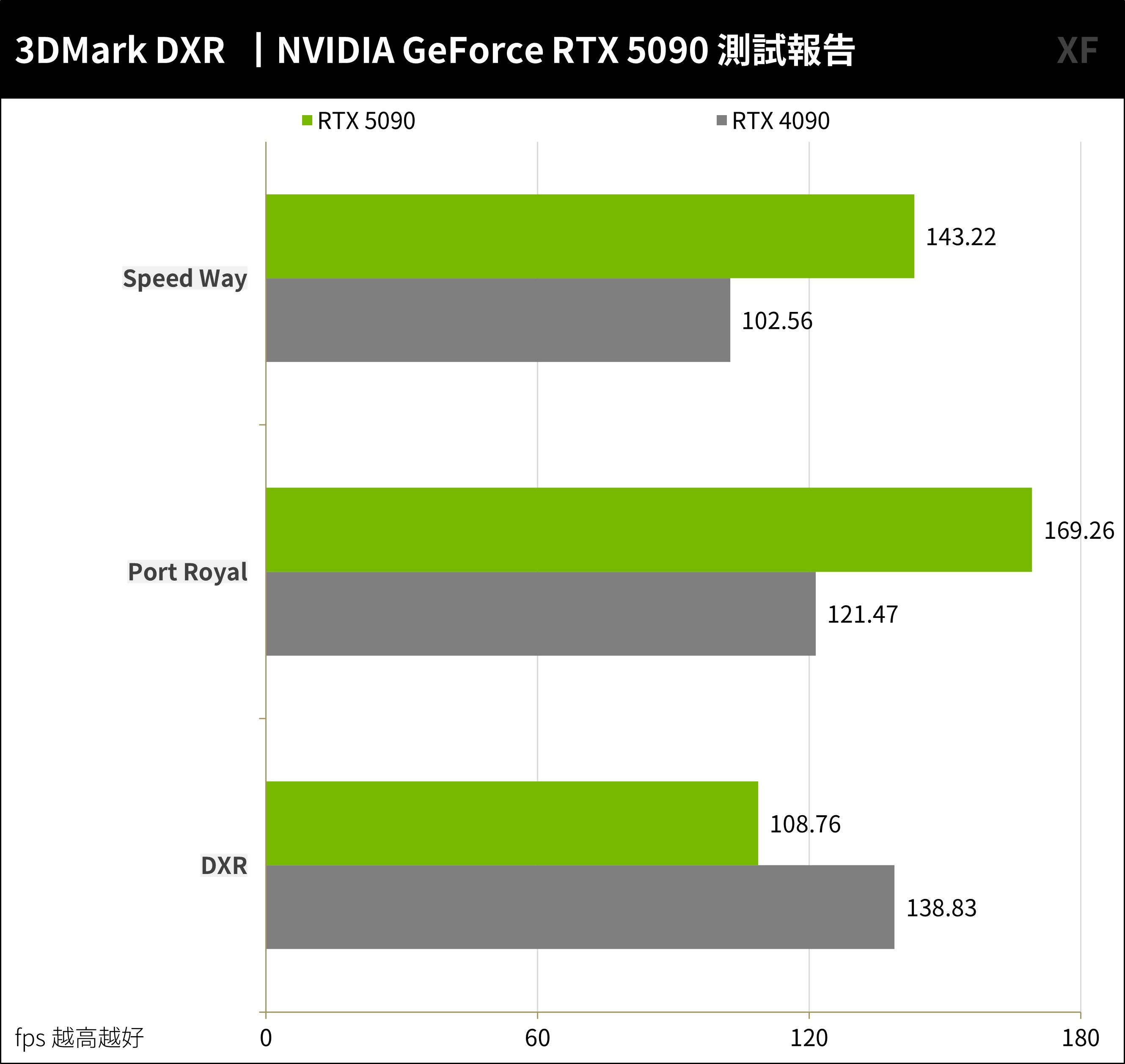
↑ 3DMark 光線追蹤。
3DMark DLSS Feature Test 可針對 DLSS 4、DLSS 3 與 DLSS 2 進行效能測試,設定為 3840 x 2160、Performance 加速。
RTX 5090 原生 82.41 FPS,通過 DLSS 4 多畫格生成可達到 437 FPS,足足 5x 倍的效能提升;但比較有趣的是 RTX 4090 在 DLSS 4 測試下,效能相比 DLSS 3 有些為的提升,這點有可能要歸功於 Transformer 模型。
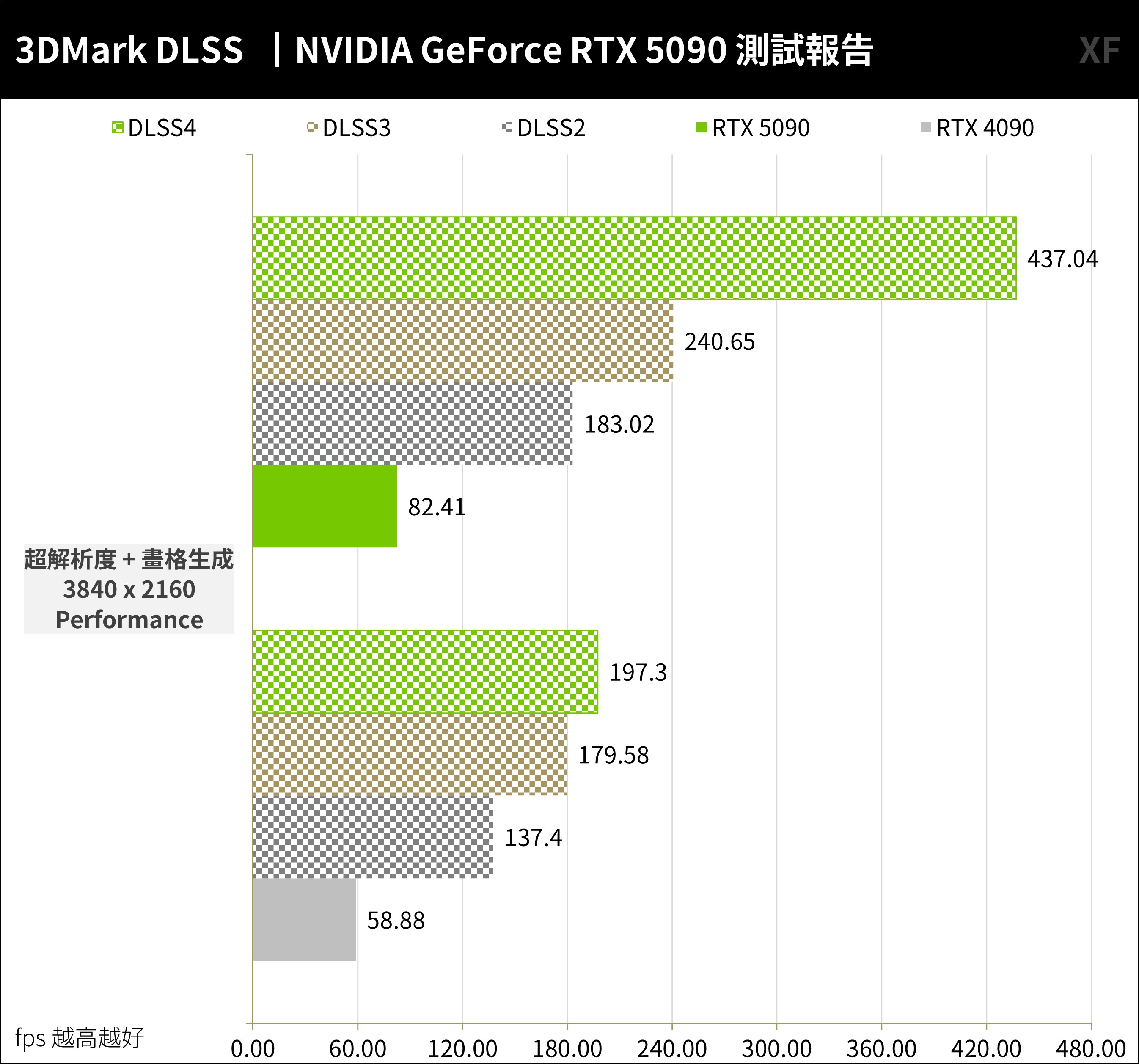
↑ 3DMark DLSS Feature Test。
NVIDIA GeForce RTX 5090 – 4 款電競遊戲效能測試
4 款電競遊戲《虹彩六號:圍攻行動》、《英雄聯盟》、《APEX 英雄》與《Counter-Strike 2》等,都是重技巧、團隊的戰術競技射擊、DOTA 類型的遊戲,因此遊戲畫質、細節不高的狀況下,遊戲 FPS 也都是平均百幀以上的表現。測試以 2160p / 1440p、特效最高設定進行。
RTX 5090 在 2160p 解析度下,CS2 平均 331.4 FPS、APEX 平均 299 FPS、英雄聯盟平均 507 FPS、R6 平均 474 FPS。這效能絕對能滿足電競玩家的 4K 240 FPS 的高效能需求。至於 1440p 狀況相同,對於 RTX 5090 或 RTX 4090 這效能絕對過剩。
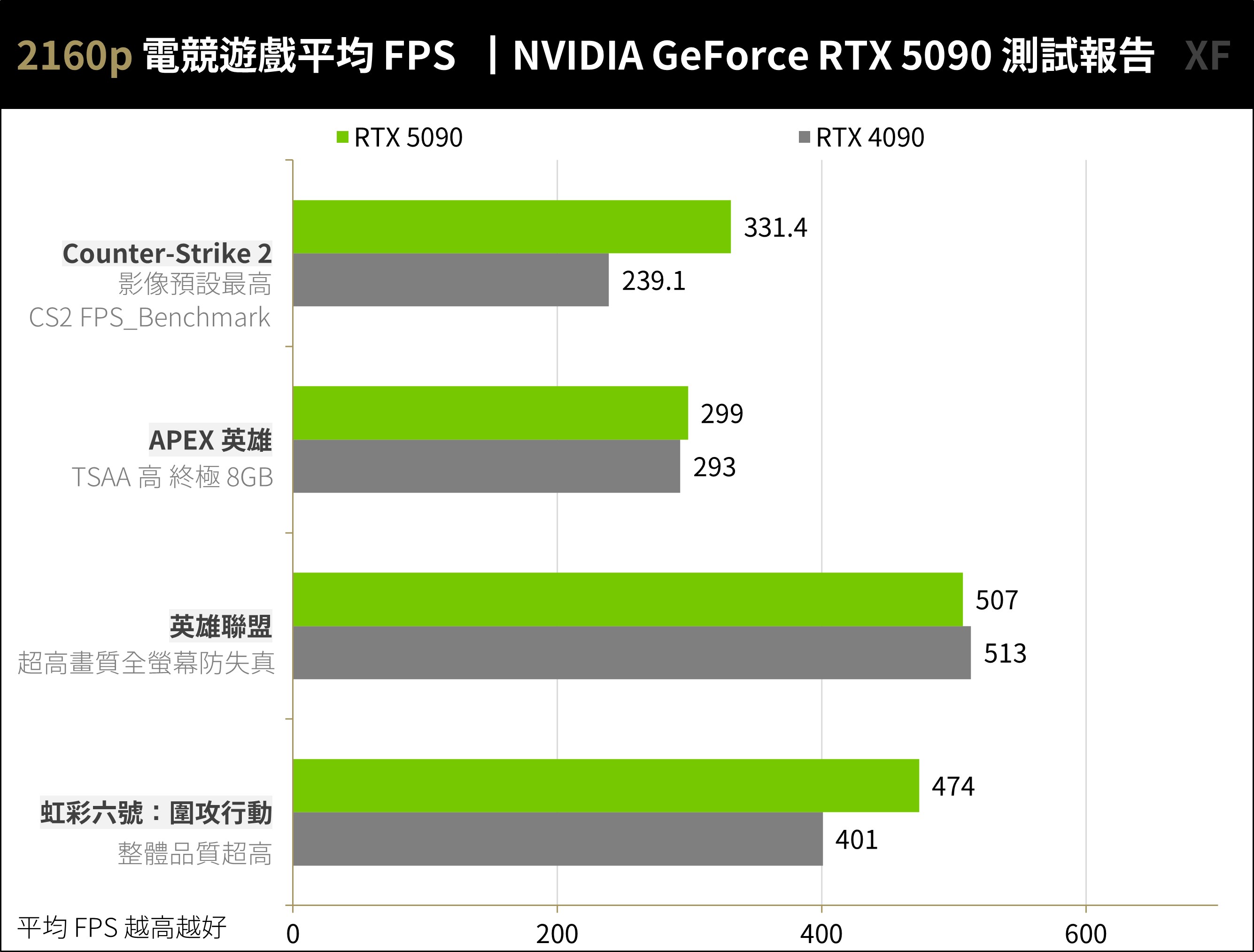
↑ 電競遊戲 2160p 測試。
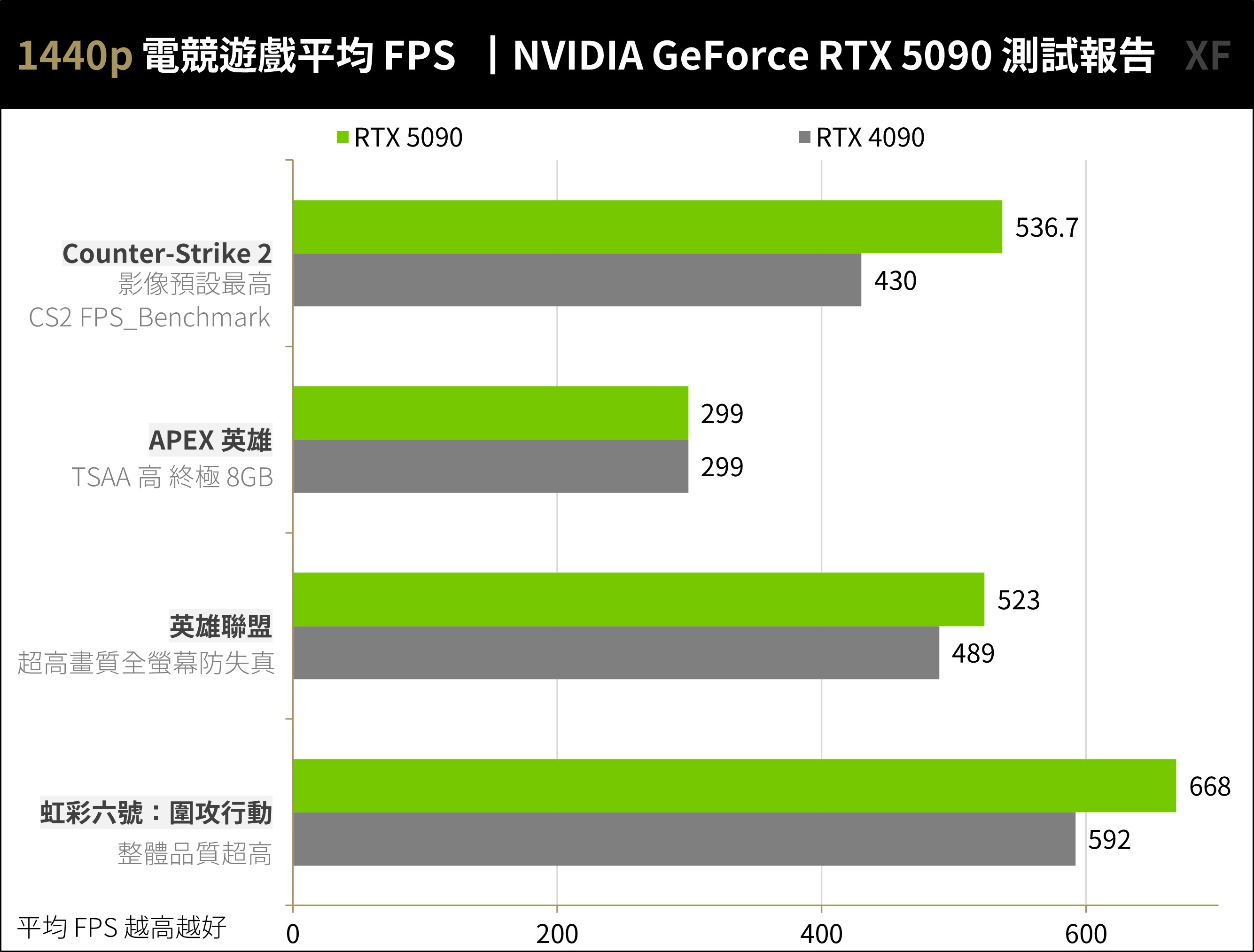
↑ 電競遊戲 1440p 測試。
NVIDIA GeForce RTX 5090 – 8 款遊戲效能測試
8 款 AAA 遊戲平均效能,同樣測試 2160p / 1440p 特效全開進行測試,這段測試不開啟光追功能與任何超解析度加速,主要測試 GPU 的實際傳統渲染遊戲效能。
遊戲測試名單有《F1® 24》、《古墓奇兵:暗影》、《地平線:期待黎明》,以及吃重效能的《邊緣禁地 3》、《碧血狂殺 2》、《刺客教條:維京紀元》、《戰神》與新加入的《流亡黯道 2》等測試。
RTX 5090 在 2160p、不追光不加速的 AAA 遊戲中達到平均 197.2 FPS,相比 RTX 4090 平均 154.1 FPS 有著 28% 的效能提升。即便不使用超解析度、畫格生成,一樣能滿足主流非光追遊戲所需的效能。
至於 1440p 解析度下,RTX 5090 平均 265.5 FPS、RTX 4090 平均 238.5 FPS,效能提升則降低至 11%,這也符合預期。
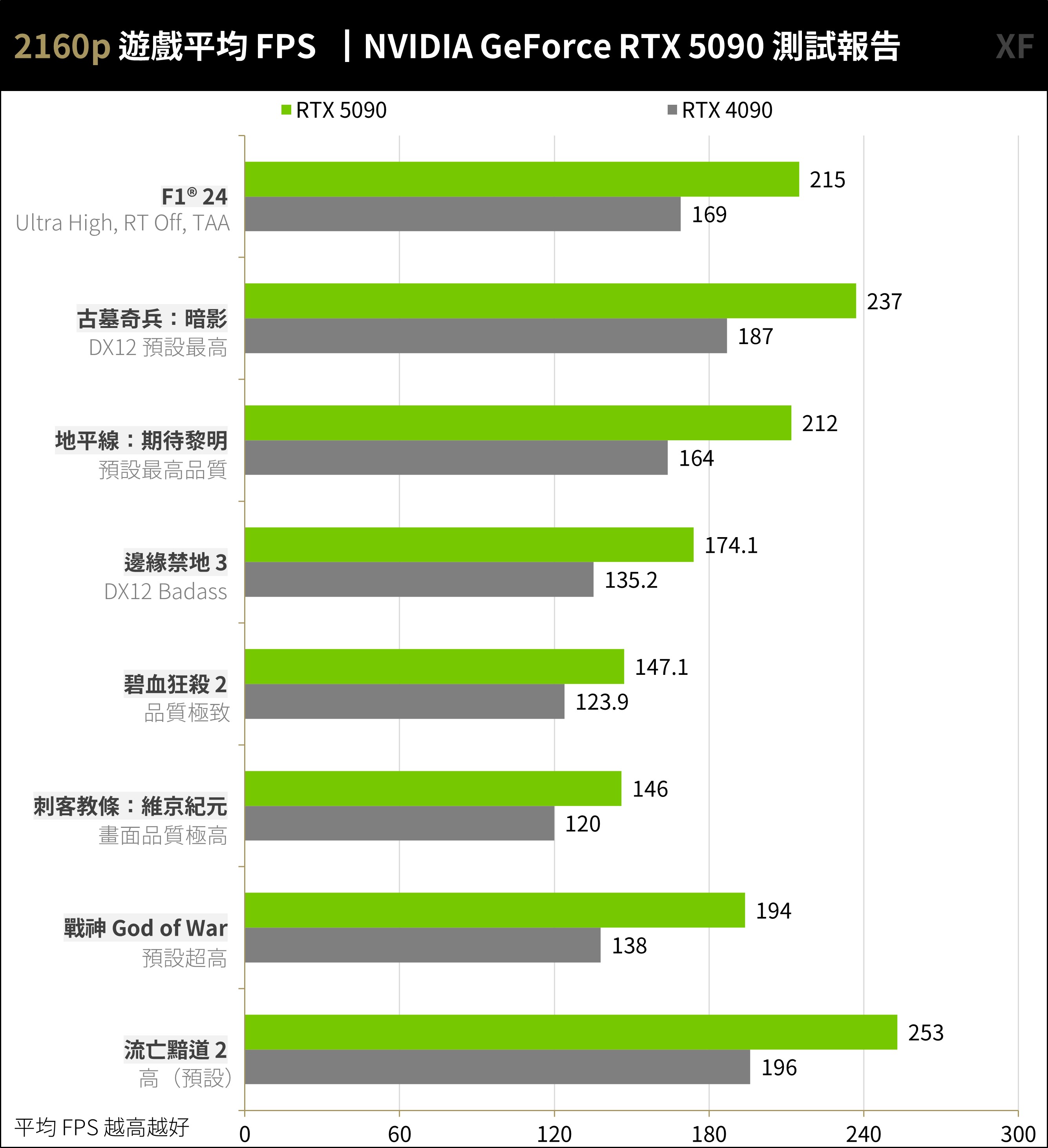
↑ AAA 遊戲 2160p,不開光追、不開超解析度、不開畫格生成測試。
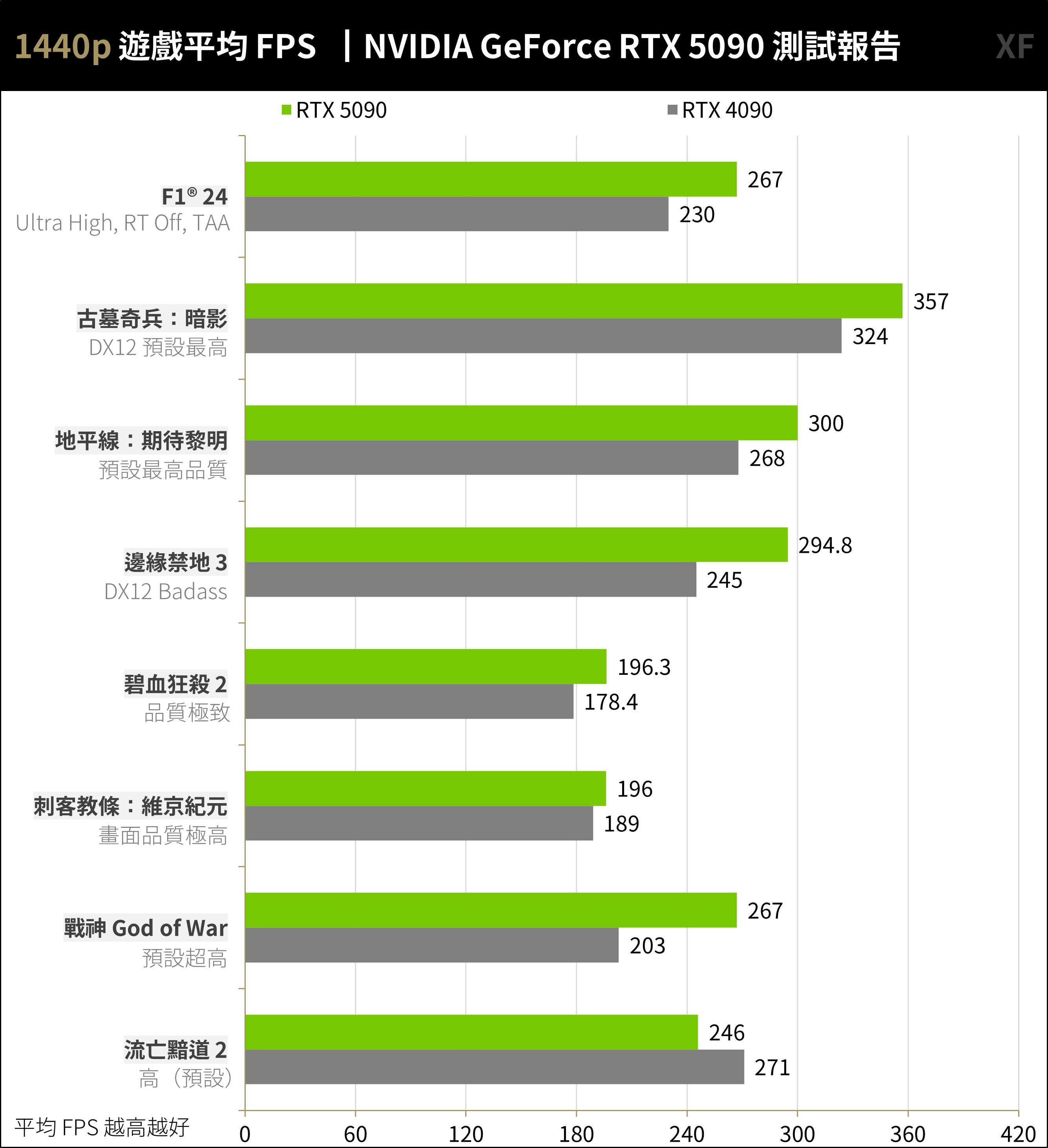
↑ AAA 遊戲 1440p,不開光追、不開超解析度、不開畫格生成測試。
NVIDIA GeForce RTX 5090 – 8 款光追遊戲測試
8 款光追 DXR 遊戲測試,使用 2160p / 1440p 解析度,特效 / 光追最高設定外,也會啟用 DLSS 3 加速、畫格生成等設定,但為了更好單獨比較 RTX 5090 與 RTX 4090 的升級效能,因此將 DLSS 4 畫格生成獨立測試,詳細設定請參考圖表說明。
測試遊戲有《暗黑破壞神 IV》、《阿凡達:潘朵拉邊境》、《極地戰嚎 6》、《漫威星際異攻隊》、《電馭叛客 2077》、《巫師 3:狂獵》、《印第安納瓊斯:古老之圈》與《黑神話:悟空》等遊戲。
RTX 5090 在 2160p 面對全光追的《黑神話:悟空》以 DLSS 3 加速也可有著 133 FPS 的效能, 8 款光追遊戲平均可達 183.5 FPS,相比 RTX 4090 平均 145.6 FPS 有著 26% 的效能提升。
至於 1440p 解析度,RTX 5090 平均 236.7 FPS、RTX 4090 平均 207.7 FPS 性能提升約 14%。
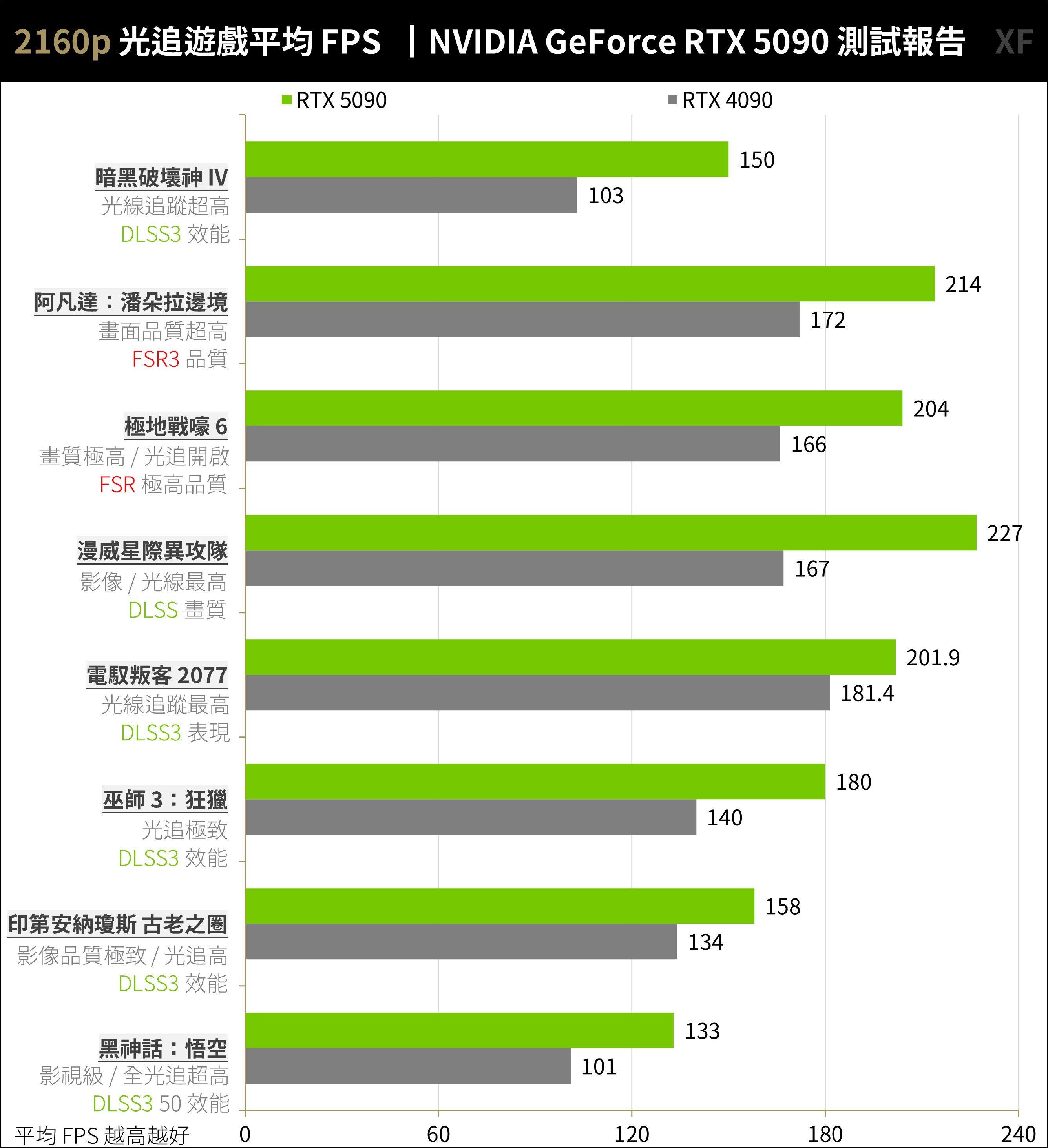
↑ 光追遊戲 2160p,開起光追、超解析度與畫格生成測試。
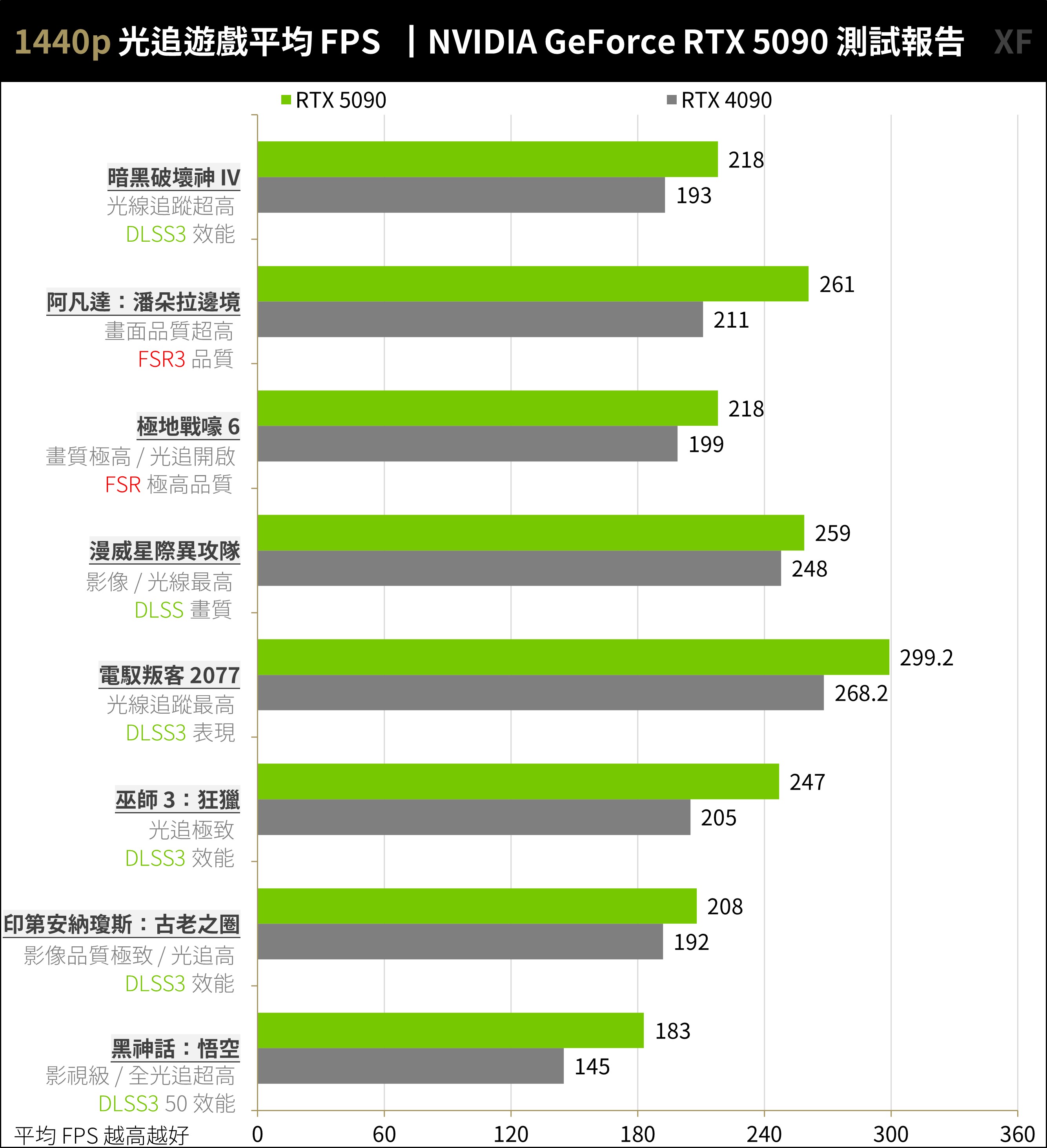
↑ 光追遊戲 1440p,開起光追、超解析度與畫格生成測試。
NVIDIA GeForce RTX 5090 – DLSS 4 多畫格生成效能實測
目前效能解禁時能測試的遊戲與應用不多,但 NVIDIA 承諾 Day-0 會有 75 款遊戲支援。這段測試主要以 2160p 解析度、特效最高、全開光追的設定,並分別比較原生效能與 DLSS 4 加速後的效能表現,使用 D5 Render、《漫威爭鋒》、《霍格華茲的傳承》、《Alan Wake 2》與《電馭叛客 2077》進行測試。
RTX 5090 在 D5 Render 原生僅 29 FPS,通過 SR、RR 與 DLSS 4 提升至 109 FPS 約 3.7x 倍提升;《漫威爭鋒》則是原生 100 FPS、DLSS 4 加速 427 FPS 約 4.27x 倍提升;《霍格華茲的傳承》原生 83 FPS、DLSS 4 加速 390 FPS 約 4.7x 倍提升。
其中提升最多的莫過於使用全光追的遊戲,《Alan Wake 2》原生 29 FPS、DLSS 4 加速至 254 FPS 約 8.7x 倍提升;《電馭叛客 2077》原生 34.6 FPS、DLSS 4 加速 292.4 FPS 約 8.45x 倍效能提升。
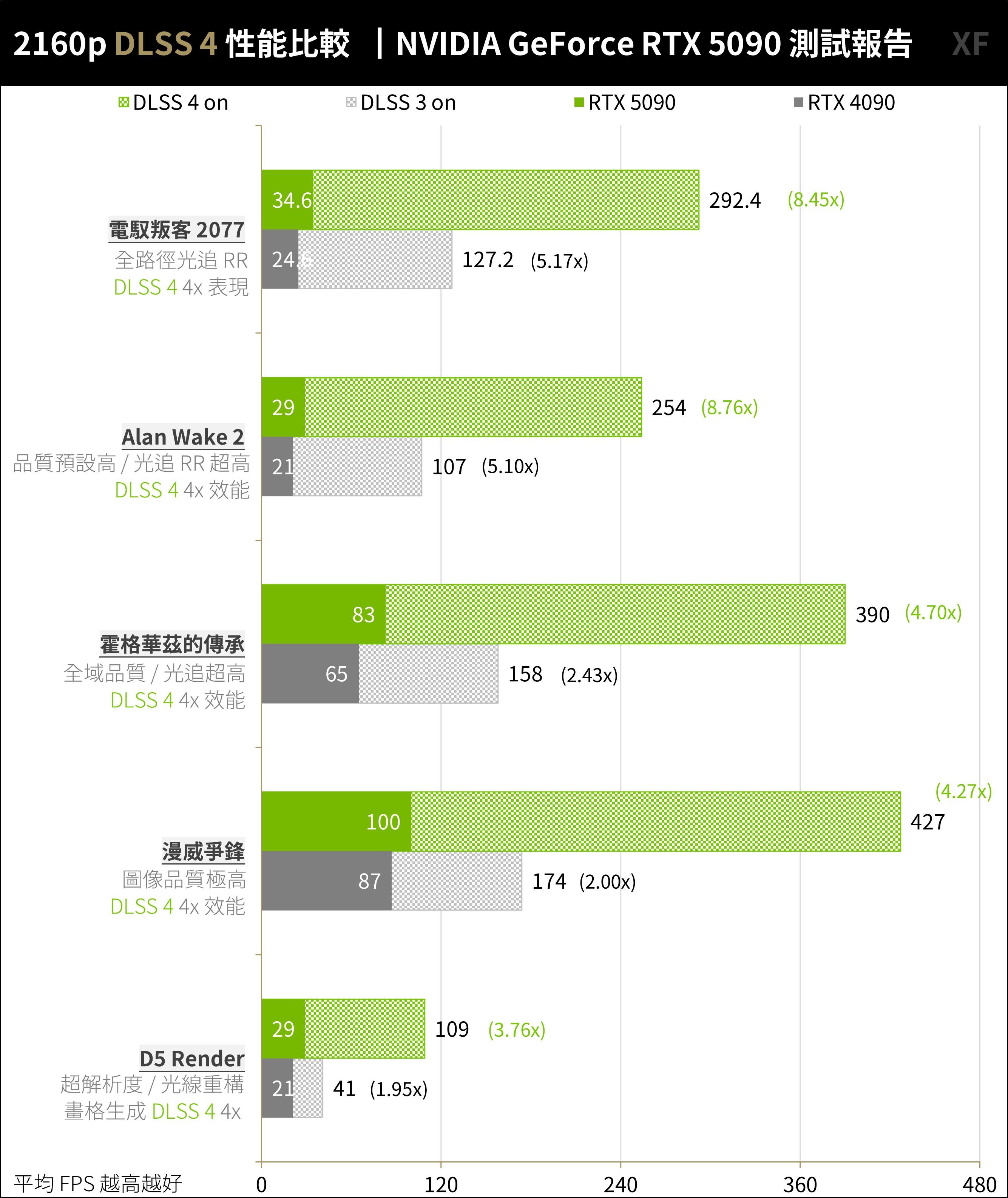
↑ DLSS 4 多畫格生成效能實測。
NVIDIA GeForce RTX 5090 功耗與溫度測量
顯卡的功耗與溫度測試,使用 Speed Way Stress test、Furmark2 與《電馭叛客 2077》進行測試。功耗測量時使用 NVIDIA 提供的 PACT 工具,可監控 PCIe 插槽與電源 12V 提供的瓦數。
顯卡溫度方面,RTX 5090 創始版在壓力測試最高溫維持在 78.9°C,而 GDDR7 記憶體溫度最高則在 92°C,至於 2077 遊戲時溫度則會稍微降低 72°C。相比 RTX 4090,在功耗效能提升的同時,以及散熱器體積降為 2-Slot 的狀況下,這溫度控制已相當不錯。
GDDR7 記憶體溫度,也比當時 GDDR6X 還要好控制。
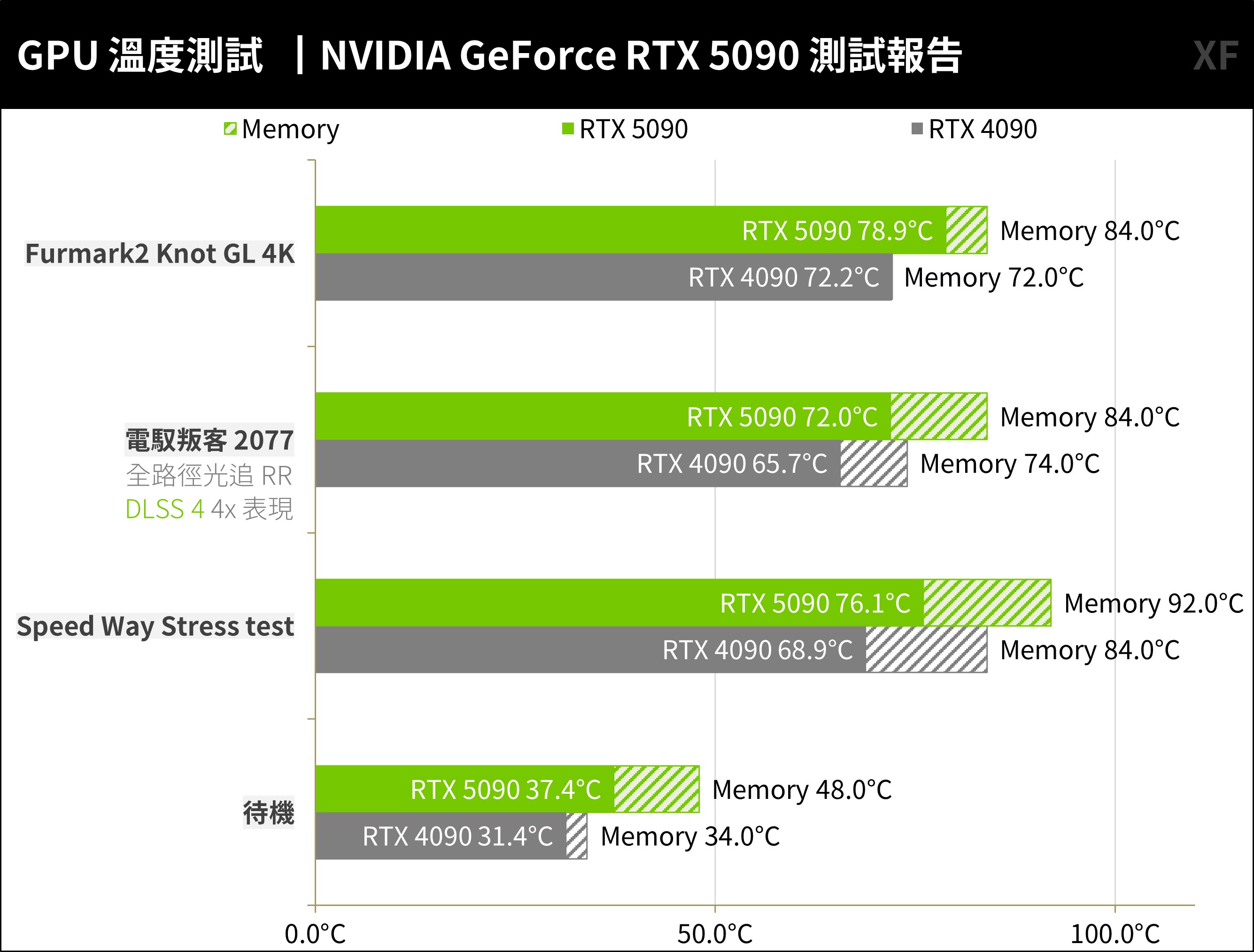
↑ RTX 5090 溫度測試。
功耗方面,RTX 5090 與 RTX 4090 採用相同的製程,但 RTX 5090 足足多了 30% 的效能,因此功耗也提升至 570W 之高,相比上代 RTX 4090 提升約 120W 左右。
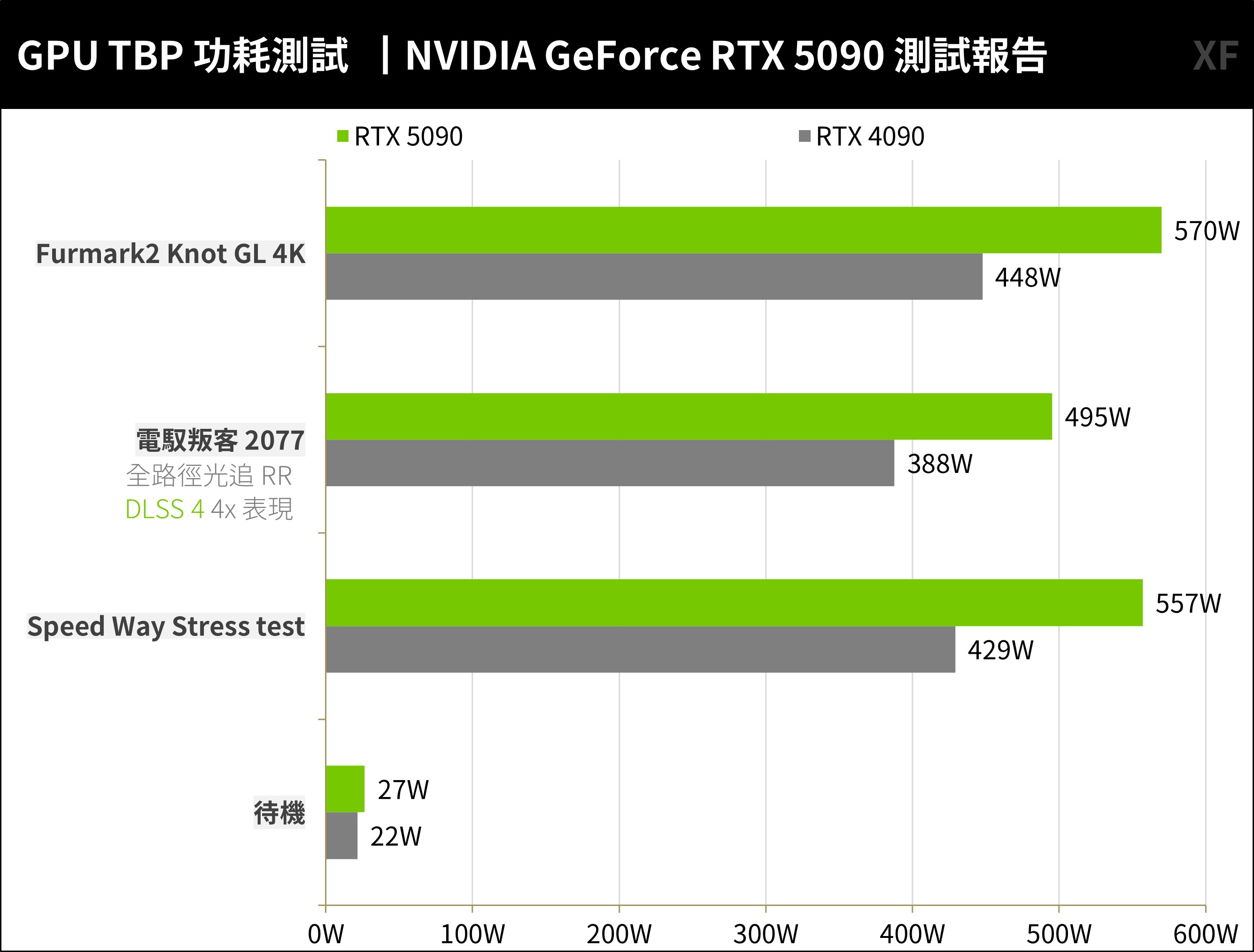
↑ RTX 5090 TGP 功耗測試。
總結
NVIDIA 紮實的交出新一代 RTX Blackwell 亮麗的成績,GeForce RTX 5090 能夠滿足旗艦 4K 遊戲玩家的超狂效能,在 8 款 AAA 遊戲平均 197.3 FPS、8 款光追 DLSS 3 加速遊戲平均 183.5 FPS,更在 DLSS 4 多畫格生成加速下達到平均 340.8 FPS 的超高性能。
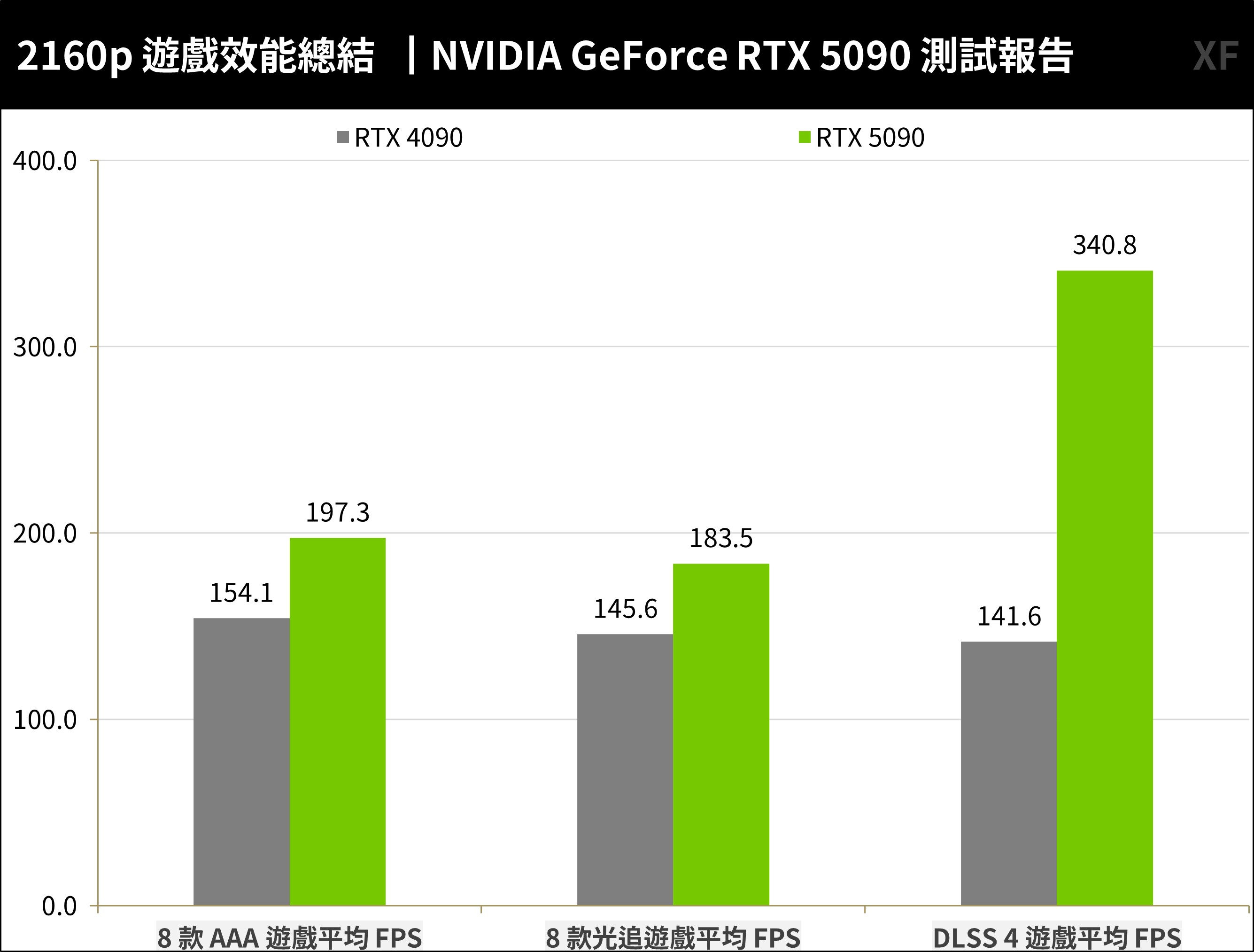
↑ RTX 5090 測試報告。
RTX 5090 相比上一代有著紮實的 30% 效能提升,而跨入 4K 240fps 也只需 DLSS 4 多畫格生成即可達成,搭配多畫格生成的 Flip Metering 與 Reflex 2 Frame Warp 等技術也一併推出,讓喜愛全光追、路徑追蹤的旗艦玩家,有著更光影更逼真、細節更細膩、畫面更順暢的遊戲體驗。
當然 RTX 5090 在影音創作、3D 渲染、生成式 AI 等應用上也有著出色的效能,能夠輕鬆滿足專業玩家所需的效能。相對的,RTX 5090 在功耗與溫度上也有所提升,這也相當合理畢竟還是使用與上代相同的 TSMC 4nm 4N NVIDIA 客制化製程,效能提升的同時功耗與溫度也跟著提高。
只不過目前據悉首波 RTX 5090 與 RTX 5080 的 GPU 數量相當不足。對於還是使用 RTX 30 以下的玩家,升級至 RTX 50 系列肯定會非常有感,但若已經是 RTX 40 的玩家升級後的效能差異就必須靠 DLSS 4 來補。
對於遊戲玩家來說 RTX 5090 效能確實足夠,但是價格、功耗相對比其餘 GPU 高出許多,但不妨稍等觀察下 RTX 5080 的效能再來決斷。
-

-
 神裝不是用掉的… 是整套帶走的!華碩 ROG 鍵鼠耳麥三件套限量 100 組只要 5555!on 2026-07-22
神裝不是用掉的… 是整套帶走的!華碩 ROG 鍵鼠耳麥三件套限量 100 組只要 5555!on 2026-07-22 -
 一咖三變!MONTECH TEN 十週年機殼,買就送同色 NX400 ARGB!on 2026-07-21
一咖三變!MONTECH TEN 十週年機殼,買就送同色 NX400 ARGB!on 2026-07-21 -
 【開箱】不必顯卡,老電腦也能跑本地 AI!華碩 UGen300 M2/USB AI 加速器。on 2026-07-21
【開箱】不必顯卡,老電腦也能跑本地 AI!華碩 UGen300 M2/USB AI 加速器。on 2026-07-21





{kind=link}