
96GB 滿足大型 LLM 本地推論!NVIDIA RTX PRO™ 6000 Blackwell 工作站 GPU 開箱

AI 為各產業帶來前所未有的變革,不論是先進的 AI 模型訓練與微調、AI 代理、生成式 AI、資料科學等領域,需要更高運算能力的 GPU 以及更大容量的 VRAM,才能解決真實世界的難題。NVIDIA 新一代 RTX PRO™ 6000 Blackwell 工作站 GPU,擁有當代滿血 NVIDIA Blackwell 架構 核心與 96GB ECC GDDR7 記憶體,可大幅加速新一代 AI 運算、光線追蹤和神經渲染等技術,重新定義 AI、技術、創意、工程和設計專業人士的工作流程。
NVIDIA Blackwell 架構 滿血核心 NVIDIA RTX PRO™ 6000 Blackwell 工作站 GPU
NVIDIA RTX PRO™ 6000 Blackwell 工作站 GPU,採用完整的 NVIDIA Blackwell 架構 核心,高達 24064 個 CUDA 核心、752 個 Tensor 核心與 188 個 RT 核心,其搭載的第五代 Tensor 核心加速了神經網路訓練與推論所需的深度學習矩陣運算,運算吞吐量提升達 3 倍,並新增 FP4 精度同時支援 TF32、BF16、FP16、FP8 及 FP6 等數據類型。
並採用 PCIe 5.0 x16 連接,可達到每秒 64GB 的頻寬,大幅提升 CPU 與 GPU 間的資料流通效率,並具備優異的擴充彈性。以及驚人的單卡 96GB 大容量記憶體並支援錯誤校正碼(ECC),可應對大規模 3D 模型、AI 專案所需的記憶體容量。

↑ NVIDIA RTX PRO™ 6000 Blackwell 工作站 GPU 外盒。

↑ 由合作夥伴麗臺販售,由購買發票日起三年保固,註冊 QR-Code。
RTX PRO™ 6000 Blackwell 工作站 GPU 的規格可是高於 GeForce RTX 5090,原因在於目前備受關注的 AI 開發、資料科學、HPC、AI 渲染與繪圖技術、影片內容與串流,以及遊戲開發等專業應用,都可利用 AI 神經渲染帶來突破性的效能成長與更好的結果,這類工作流程相對高度複雜,涉及多種 AI 技術的整合與協作,更凸顯高效能 GPU 及大容量記憶體在現代 AI 開發中的關鍵角色。

↑ RTX PRO™ 6000 Blackwell 工作站 GPU 有著創始版的散熱器,但改為高質感的黑鏡面外殼,以及金屬邊框、滿板散熱鰭片。

↑ RTX PRO™ 6000 Blackwell 工作站 GPU 正面外觀,則有著 2 顆散熱風扇與穿透氣流設計。

↑ 顯卡供電一樣使用 PCIe 12V-2×6。

↑ RTX PRO 6000。
顯示輸出,則提供 4 個 DisplayPort 2.1b,最多 4 個 4K 165Hz 或最多 2 個 8K 100Hz DSC 影像輸出。並且也提供完整的 NVIDIA RTX 桌面管理軟體、NVIDIA RTX PRO Sync 與 NVIDIA Mosaic 等專業功能。

↑ 顯示輸出。

↑ 顯卡配件則提供 PCIe Gen5 外接電源轉接線與固定支架含螺絲。
RTX PRO™ 6000 Blackwell 工作站 GPU – 大型 LLM gpt-oss-120b 推論效能
最近 NVIDIA 宣布與 OpenAI 宣布策略合作,而此前 OpenAI 最新的 gpt-oss 開源模型,原本僅限於雲端資料中心的尖端 AI 技術,如今也能以驚人的速度在搭載 RTX 技術的 PC 及工作站上運行。經過最佳化的「gpt-oss-20b」模型可在搭配至少 16GB VRAM 的 NVIDIA RTX AI PC 上,以最大效能極速運行,在 RTX 5090 GPU 上可達每秒 250 個 token 的運算速度。
至於更高階的「gpt-oss-120b」模型則支援搭載 NVIDIA RTX PRO GPU 的專業工作站,而這也是本次 AI 大型 LLM 的測試重點,使用 Ollama 應用程式來部署 gpt-oss-120b 模型,並已針對 RTX GPU 最佳化。通過執行 gpt-oss-120b 模型需要佔用約 62.1 GB 的 GPU 記憶體,這遠超一般桌上型 GPU 記憶體容量的範疇。
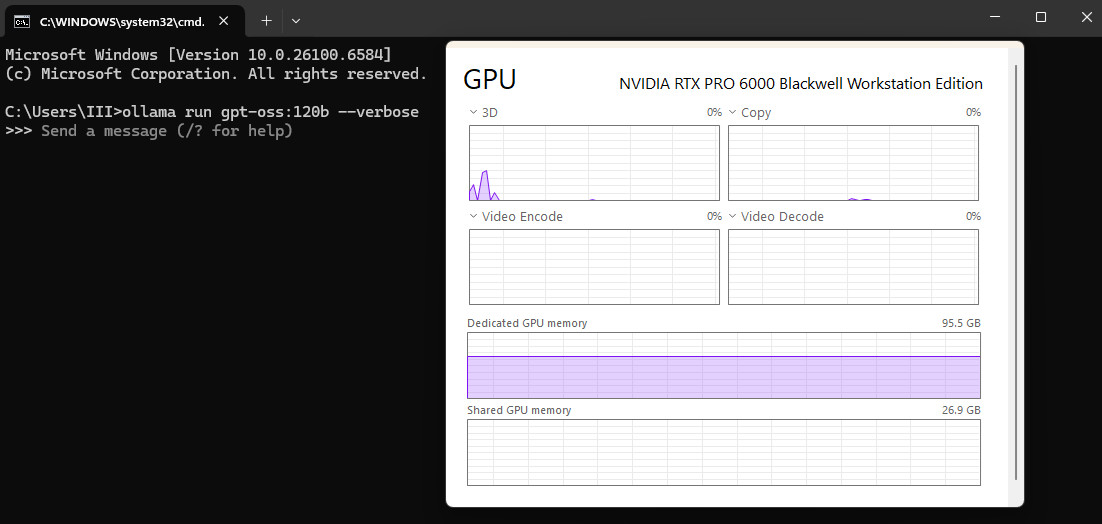
↑ 執行 gpt-oss-120b 模型,就需要佔用 62.1 GB 的 GPU 記憶體。
嘗試輸入 Prompt:說說 NVIDIA RTX PRO 在 AI 領域的重要性。通過 RTX PRO™ 6000 Blackwell 工作站 GPU 加速,LLM 模型通過提字、思考後花費 23.4s 秒完成輸出,這組 Prompt 約 79 token(s),推論輸出 3392 token(s)、花費 22.7s 秒的時間,推論速率約在每秒 149.09 tokens/s。
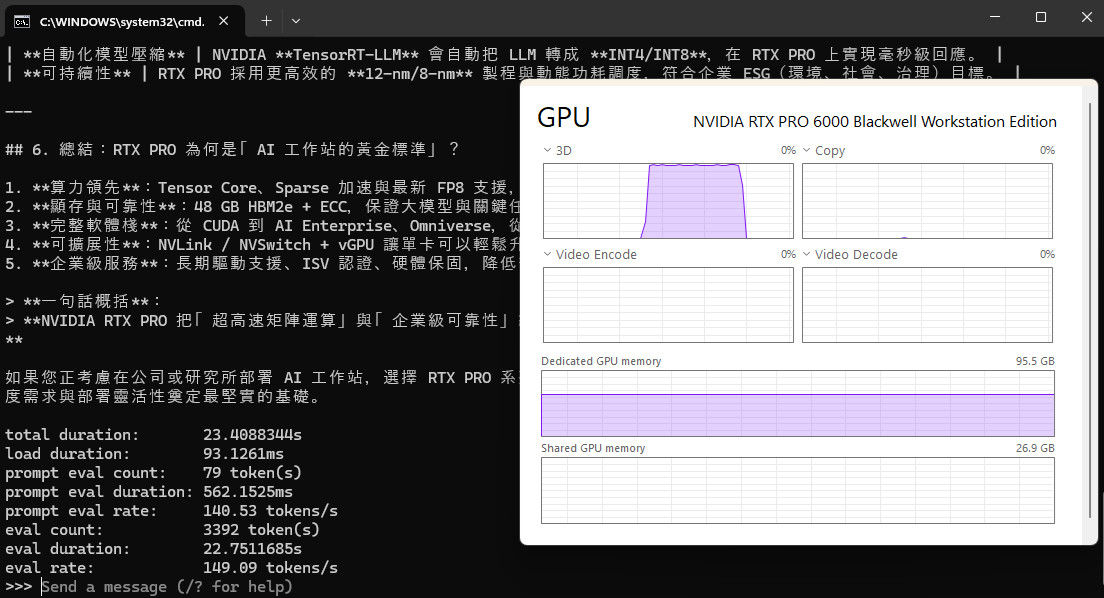
↑ gpt-oss-120b 模型,RTX PRO™ 6000 Blackwell 工作站 GPU 輸出結果。
倘若想建立本地端的大型 LLM 推論系統,不外乎需要 NVIDIA RTX PRO™ 6000 Blackwell 工作站 GPU,藉由單卡 96GB VRAM 滿載 AI 模型的眾多資料,滿足資料科學和 AI 訓練用的桌上型工作站效能。
RTX PRO™ 6000 Blackwell 工作站 GPU – 生成式 AI 測試
GPU-Z 檢視 NVIDIA RTX PRO™ 6000 Blackwell 工作站 GPU 資訊,採用 5nm 製程、NVIDIA Blackwell 架構 核心,使用 PCIe 5.0 x16 介面,有著 24064 個 CUDA 核心、98304 MB GDDR7 記憶體支援 ECC 功能,GPU 預設時脈 1590 MHz、Boost 時脈 2617 MHz;GPU 功耗限制最高 600W 上限。
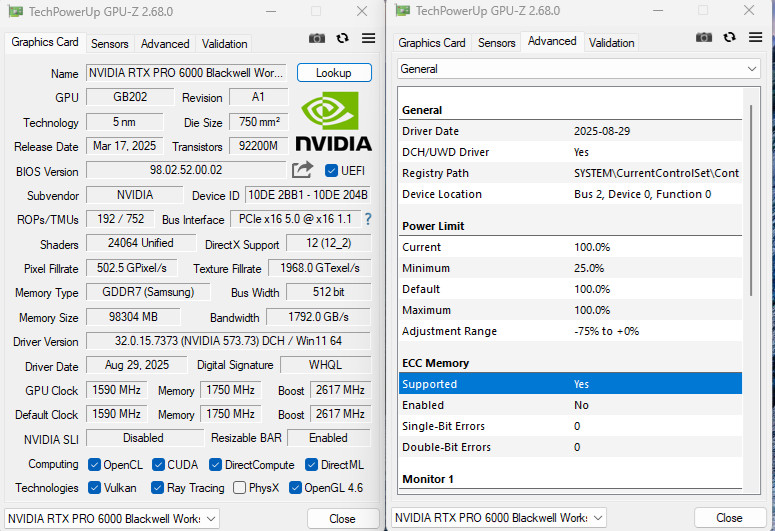
↑ GPU-Z。
UL Procyon AI Image Generation Benchmark 提供 Stable Diffusion XL (FP16) 與 Stable Diffusion 1.5 (FP16) 的兩種測試情境,並支援 ONNX runtime with DirectML、NVIDIA TensorRT 與 Intel OpenVINO 的推論引擎。
RTX PRO™ 6000 Blackwell 工作站 GPU 採用 TensorRT 推論引擎,在 Stable Diffusion 1.5 標準模型,總花費 11.5 秒完成 16 張照片生成、生成一張照片則需要 0.723 秒。換成 Stable Diffusion 1.5 XL 模型,總花費來到 89.1 秒、生成一張照片 5.57 秒。
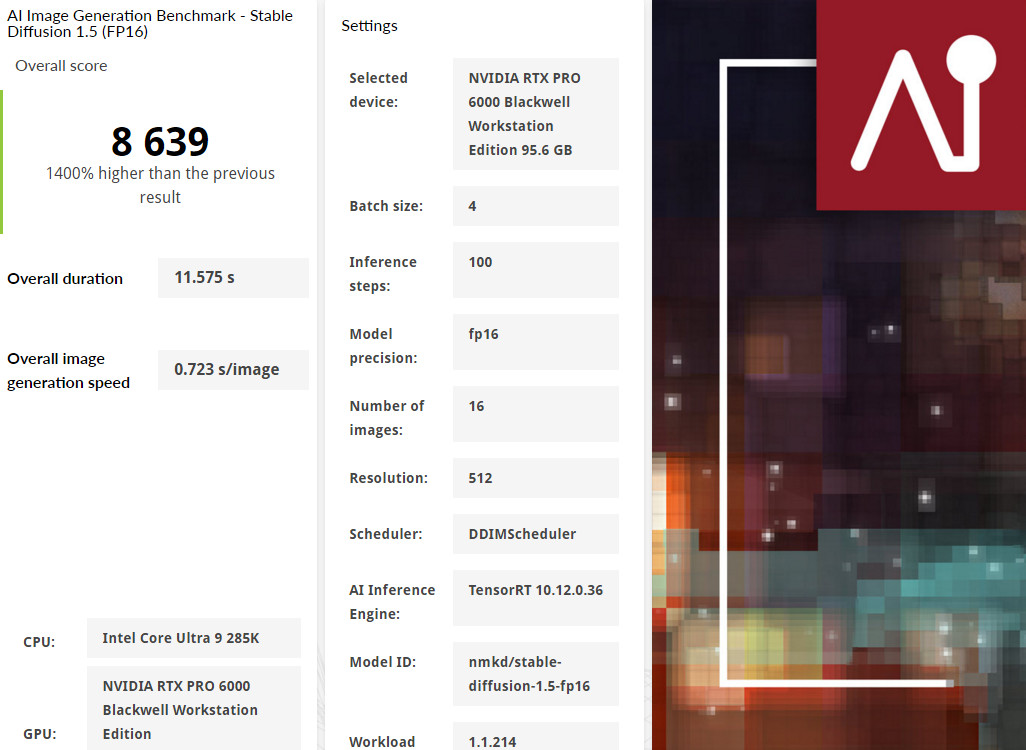
↑ UL Procyon AI Image Generation,Stable Diffusion (FP16)。
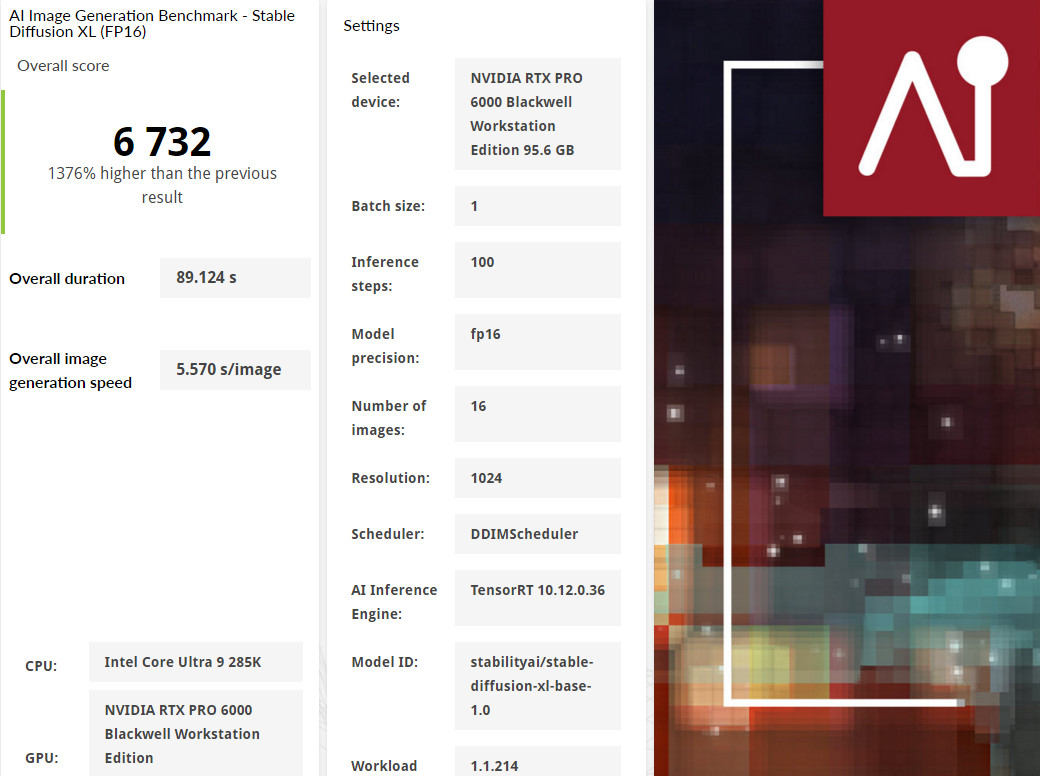
↑ UL Procyon AI Image Generation,Stable Diffusion XL (FP16)。
UL Procyon AI Text Generation Benchmark 提供 ONNX Runtime DirectML 或 OpenVINO 推論引擎,使用 Phi-3.5-mini、Llama-3.1-8B、Mistral-7B 與 Llama-2-13B 等四個模式,每個模型測試 7 個 Prompts 包含 RAG 與非 RAG 的查詢,通過權重後的總分與平均 Time To First Token(TTFT)、平均 Output Token Speed(OTS)提供專業用戶橫量電腦的 AI LLM 推論效能。
RTX PRO™ 6000 Blackwell 工作站 GPU 採用 ONNX DirectML 推論引擎,在 PHI 3.5 模型達到 7137分、TTFT 0.16s、OTS 316.67 tokens/s;MISTRAL 7B 模型 7772 分、TTFT 0.2s、OTS 264.09 tokens/s;LLAMA 3.1 獲得 6690 分、TTFT 0.19s、OTS 214.81 tokens/s;LLAMA 2 獲得 7722 分、TTFT 0.3s、OTS 133.6 tokens/s。
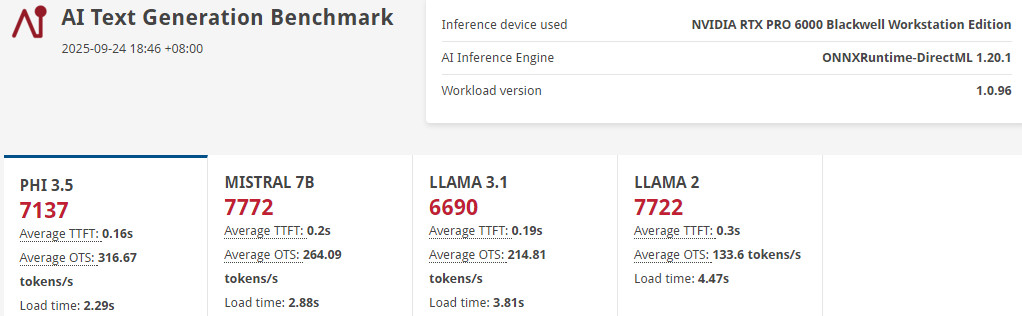
↑ UL Procyon AI Text Generation Benchmark。
RTX PRO™ 6000 Blackwell 工作站 GPU–創作影音輸出、GPU 渲染測試
PugetBench for DaVinci Resolve 測試,分別針對影片的編碼輸出效能、處理不同片源的效能、Fusion 運用 VFX 繪圖效果測試,以及利用 GPU 加速的 OpenFX 特效等測試。測試影像包含 4K、8K 的影像,以及各種常見的媒體格式,4K H.264 150mbps 8-bit、4K ProRes 422、4K RED、8K H.265 100mbps、8K RED 等媒體。
RTX PRO™ 6000 Blackwell 工作站 GPU 獲得基本 13954、標準 14813 分的總成績,這性能在 PugetBench 資料庫中搖搖領先,相差第一名在於 CPU 等級而非 GPU。
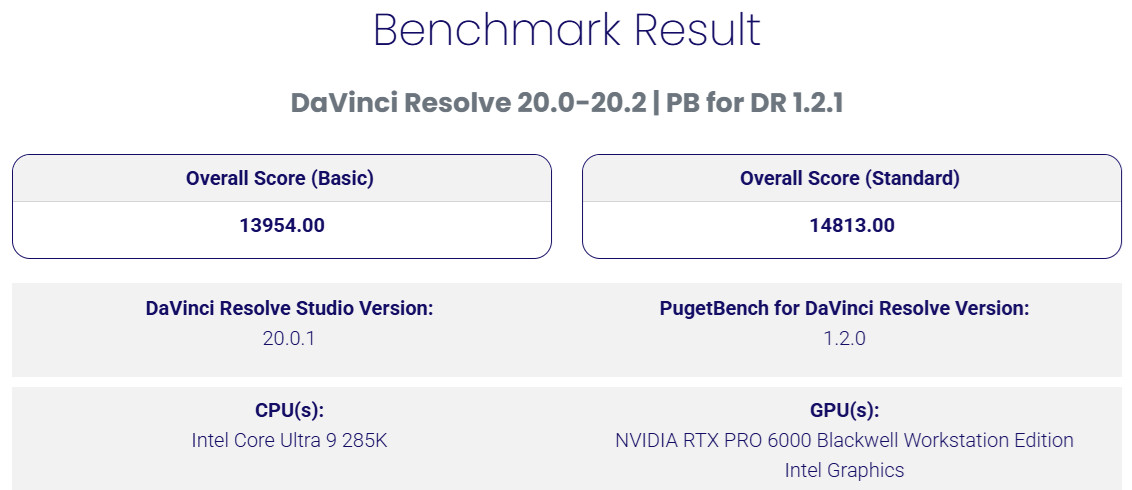
↑ PugetBench for DaVinci Resolve。
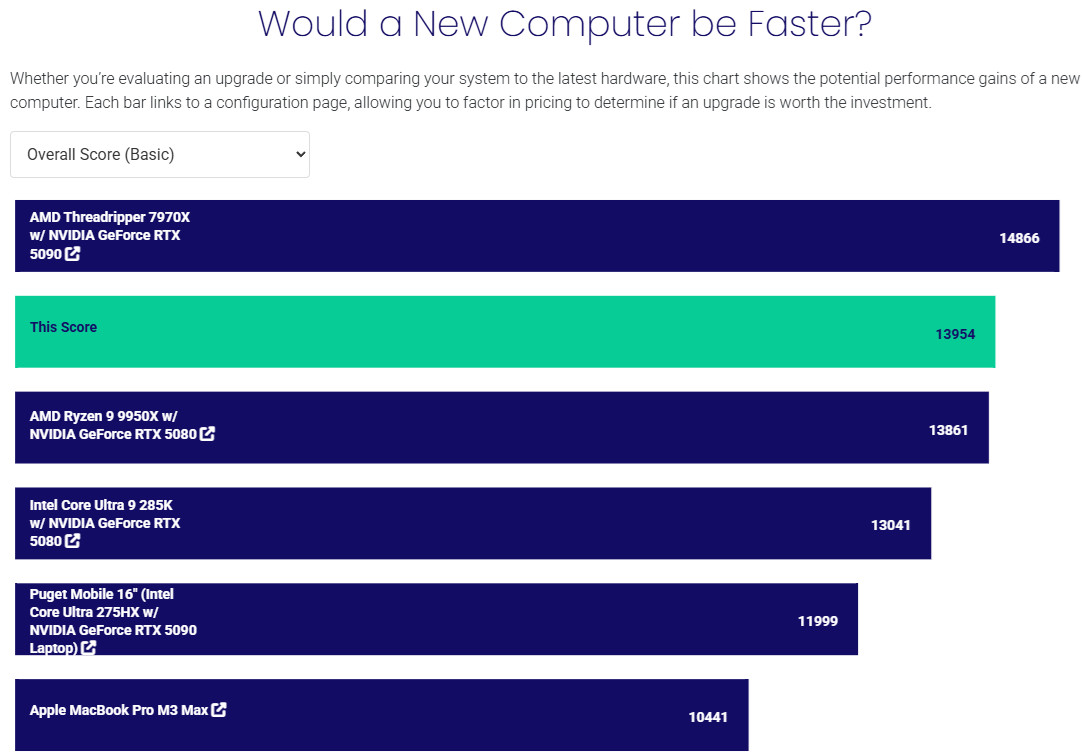
↑ 成績比較。
SPECviewperf 15 基準測試,則是更符合現代的專業應用程式圖形效能的工具,保有 OpenGL、DirectX 與 Vulkan 等 API 支援,新加入 blender、unreal_engine、Enscape 等應用測試,以及更新既有的應用測試情境。
RTX PRO™ 6000 Blackwell 工作站 GPU 在 4K 解析度,每項測試都有著相當高的 FPS 表現。

↑ SPECviewperf 15 基準測試。
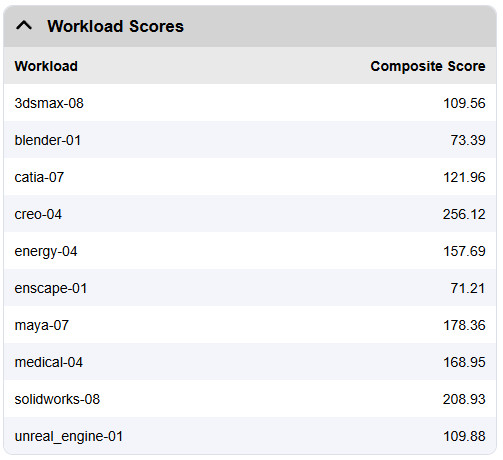
↑ 工作負載成績,FPS。
KeyShot 是由 Luxion 所開發的 3D 渲染軟體,能夠快速的建立逼真的 3D 模型影像,並以直覺的介面與即時渲染而出名。KeyShot 預設使用 CPU 進行渲染並支援 GPU 加速渲染等功能,在 KeyShot Viewer 當中提供 Benchmark 功能。KeyShot Benchmark 基準分為 1,測試分數越高代表性能越好。
KeyShot CPU 測試獲得 5.5 分,而 、RTX PRO™ 6000 Blackwell 工作站 GPU 獲得 253.93 分的成績,大幅加速影像渲染的速度。
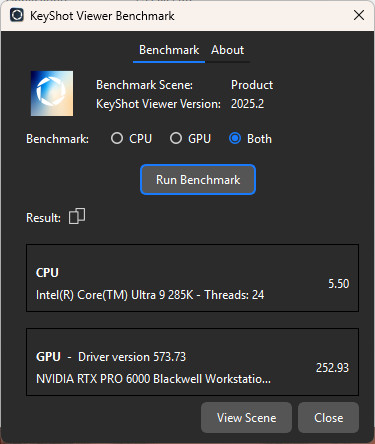
↑ KeyShot。
V-Ray Benchmark 是由 Chaos Group 所開發,V-Ray 是基於物理法則所設計的光線渲染軟體,而此工具可針對 CPU 進行光線追蹤的渲染圖像的運算效能測試,CPU 評分以 vsamples 每秒計算數為單位。
RTX PRO™ 6000 Blackwell 工作站 GPU 在 V-Ray RTX 測試中,在 1 分鐘的時間能有著 11507 vpaths 的光線運算量。
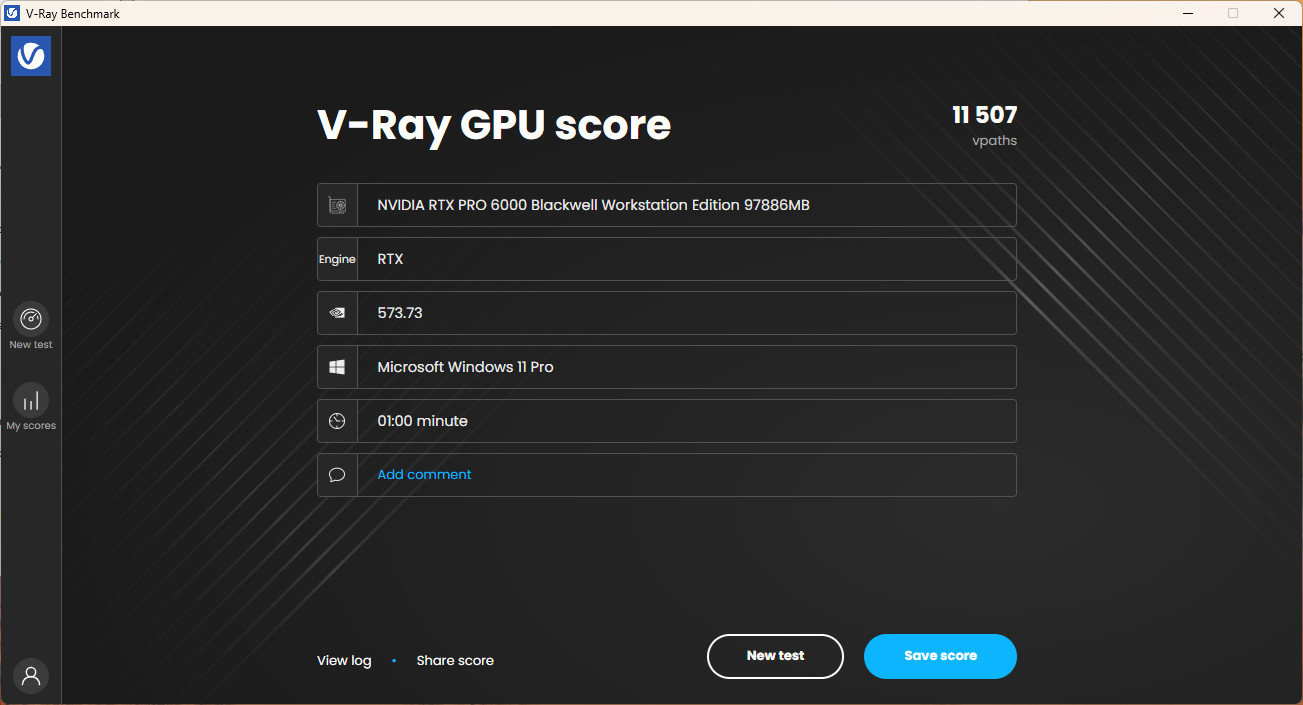
↑ V-Ray Benchmark。
3DMark Speed Way 測試,採用新一代 DirectX 12 Ultimate API 所開發,包含著 DirectX Raytracing tier 1.1 的即時光追全域照明、光線追蹤反射、Mesh Shader 等新一代繪圖技術。測試以 2K 解析度、無使用 SR 或 FG 加速技術,純粹展現 GPU 在光線追蹤渲染下的效能。
RTX PRO™ 6000 Blackwell 工作站 GPU,可達到 15029 分的成績,也就是平均 150.3 FPS 的影像順暢度。
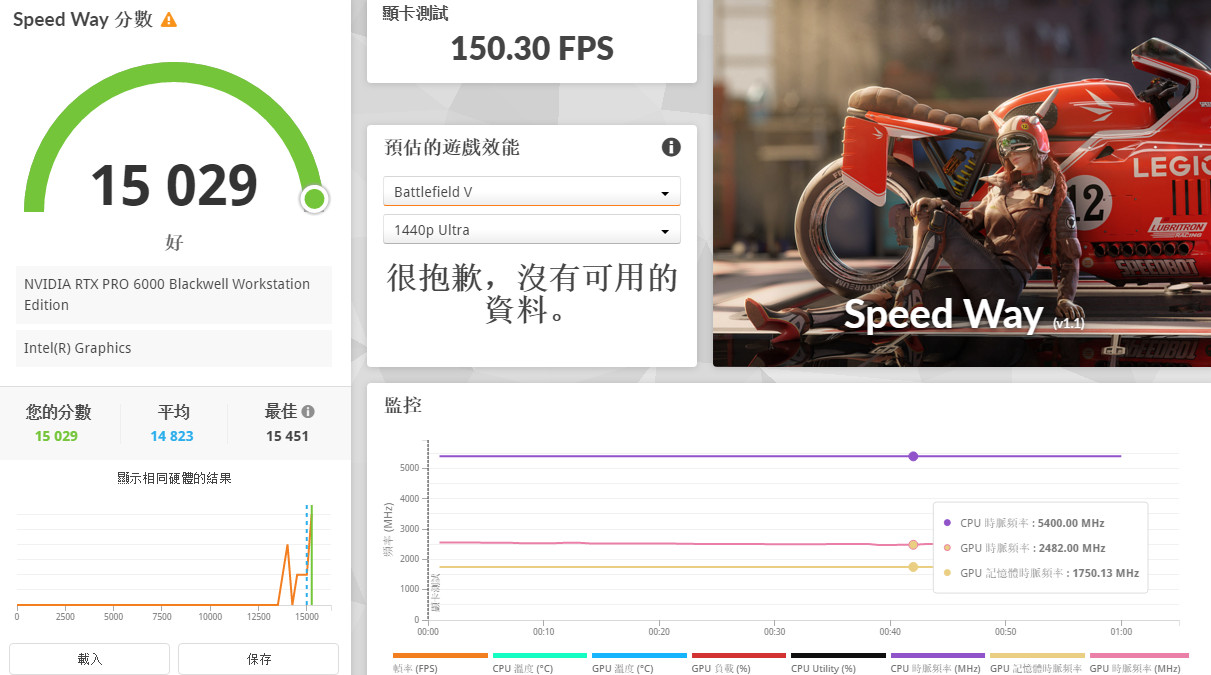
↑ 3DMark Speed Way。
3DMark DLSS 4 功能測試,採用光線追蹤的 Port Royal 場景測試,分別比較 DLSS 4 開啟前後的效能差距。新版本支援 DLSS 4 SR 超解析度,以及 DLSS 4 多畫格生成功能,最高支援 FG 4x 的畫格生成。
RTX PRO™ 6000 Blackwell 工作站 GPU,未開啟 DLSS 時原生渲染 79.64 FPS,開啟 DLSS 4 加速後可達到 506.38 FPS 的效能提升,約達到 6.3x 倍的效能升級。
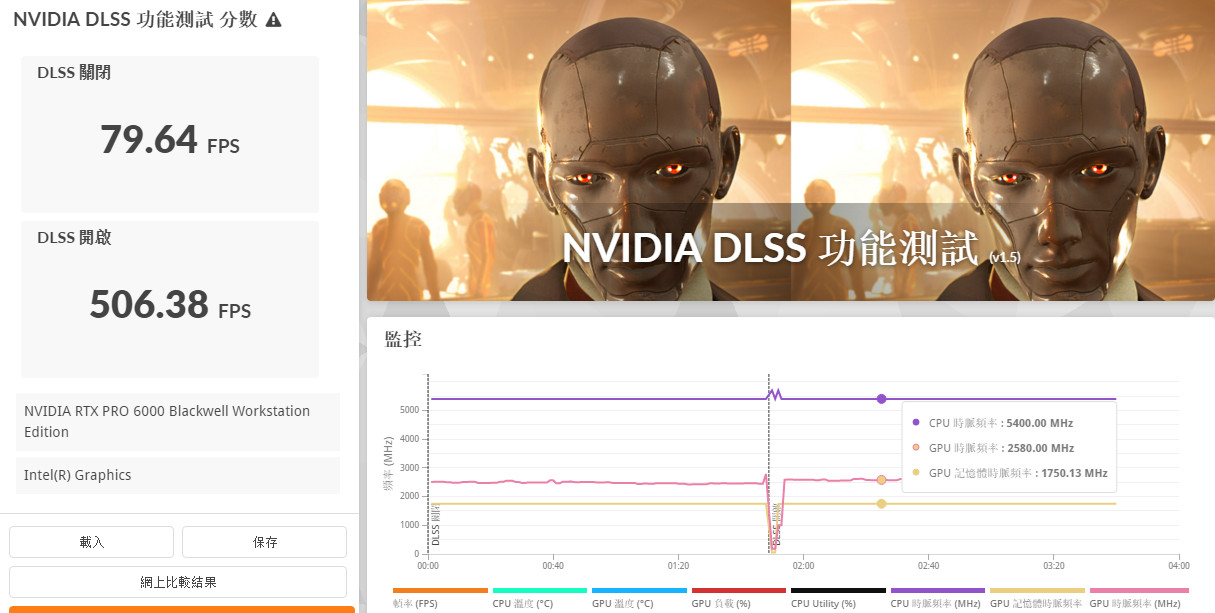
↑ 3DMark DLSS 4 功能測試。
RTX PRO™ 6000 Blackwell 工作站 GPU 功耗與溫度測量
溫度測試,則使用 3DMark Speed Way Stress test(GPU)壓力測試,以及 V-Ray GPU RTX 10min 壓力測試,並利用 HWINFO 軟體紀錄 GPU 溫度與 TBP 功耗。
RTX PRO™ 6000 Blackwell 工作站 GPU,待機時溫度僅 33.1°C,通過 Speed Way 壓力測試時 GPU 溫度 86.7°C、記憶體 90°C;而 V-Ray GPU RTX 10min 測試時 GPU 僅 68°C、記憶體 78°C。
功耗方面 RTX PRO™ 6000 Blackwell 工作站 GPU,在光線追蹤渲染測試下達到最高平均 589W 功耗、記錄最高則是 600W;而 V-Ray 測試時則在 423W 左右。
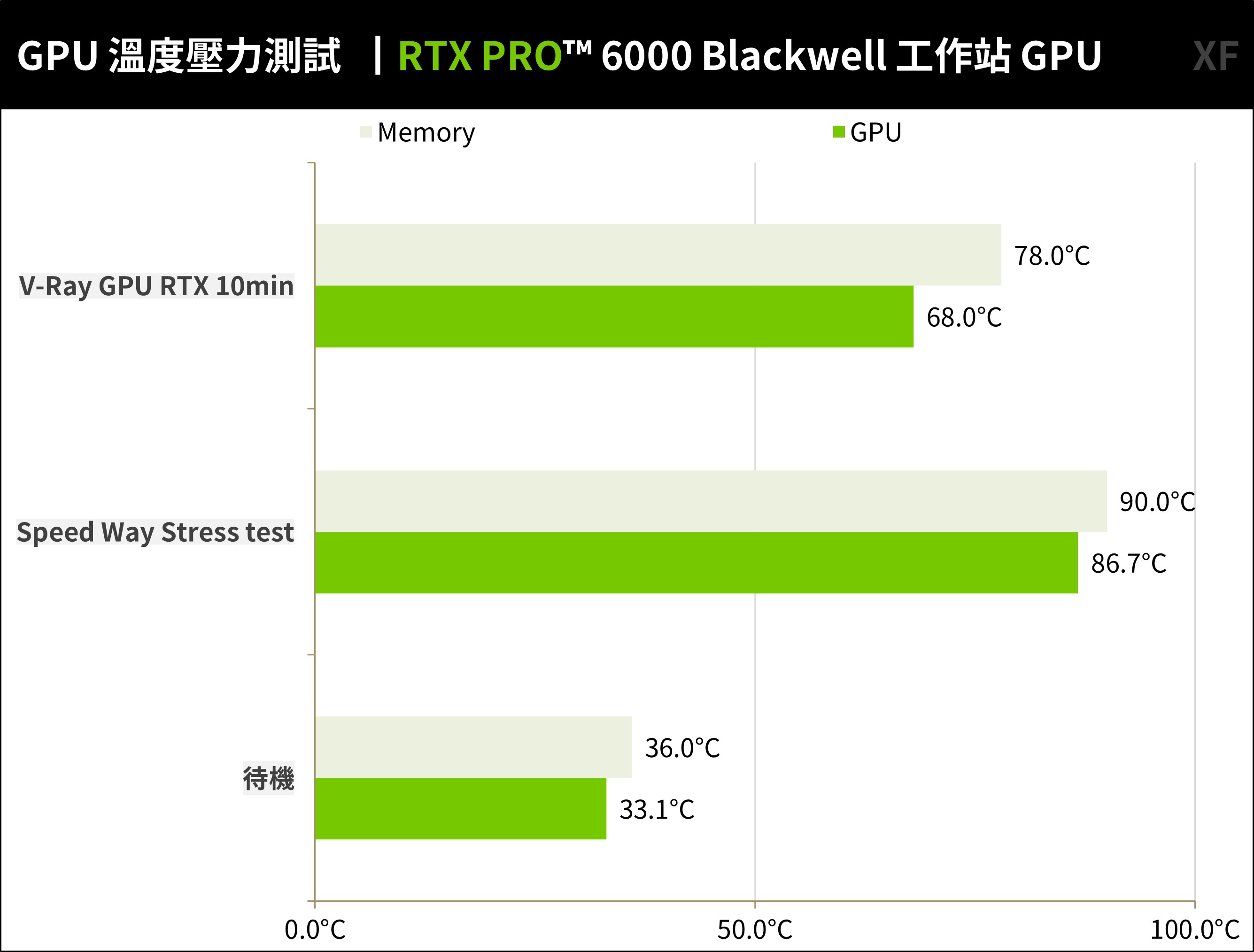
↑ RTX PRO™ 6000 Blackwell 工作站 GPU 溫度測試。
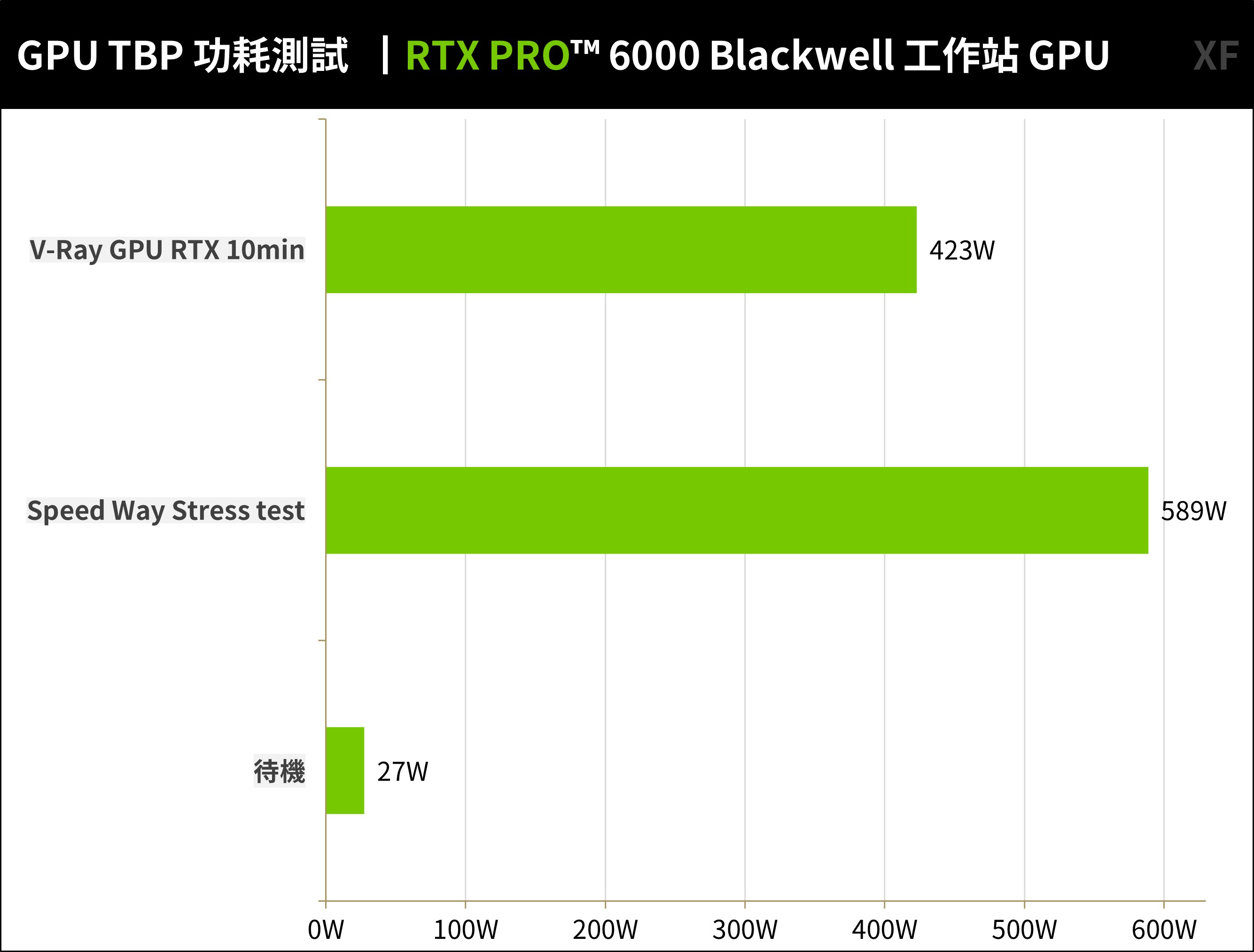
↑ RTX PRO™ 6000 Blackwell 工作站 GPU 功耗測試。
總結
NVIDIA RTX PRO 6000 Blackwell 工作站 GPU,是目前單卡 GPU 中運算效能最高的繪圖卡,亦是目前單 GPU 最大 96GB VRAM 的旗艦繪圖卡,而 NVIDIA 還針對伺服器與 Max-Q 工作站推出不同的選擇,讓專業用戶可依據系統功耗、介面卡尺寸、散熱方式等選擇所需的 GPU,利用絕佳的 AI 處理能力加速最新進的模型,處理複雜的設計、模擬、渲染、影音剪輯特效等創意工作流程。
根據 NVIDIA 建議的「資料科學和 AI 訓練用桌上型工作站」的建議配置表,本次測試的系統屬於良好級別。建議不外乎使用高核心 CPU、大容量系統記憶體、NVMe SSD 做為系統與儲存模型資料碟、高速有線網路,以及使用 NVIDIA RTX PRO 6000 Blackwell 系列 GPU。
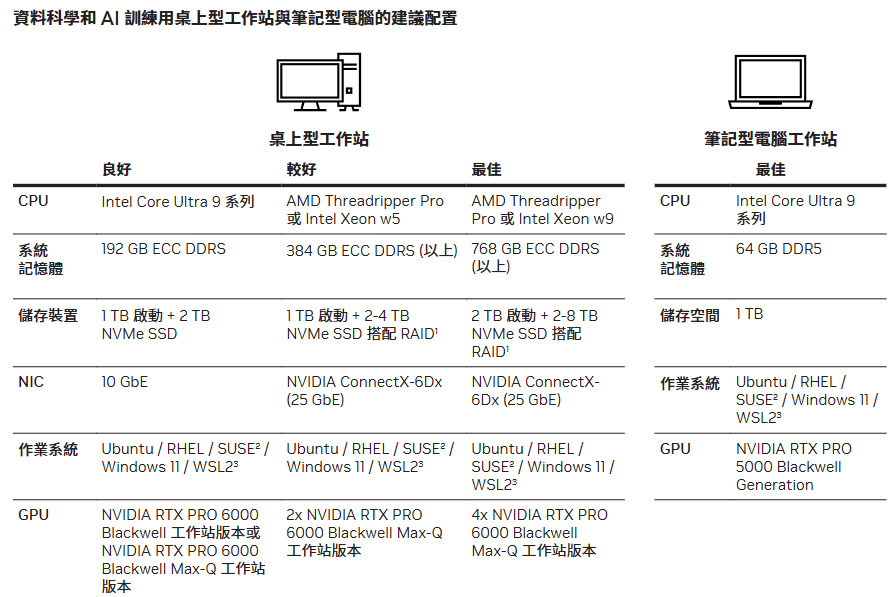
↑ 資料科學和 AI 訓練用桌上型工作站建議配置表。資料來源:NVIDIA 官網。
專業繪圖卡銷售則由 NVIDIA 最具代表性的長期合作夥伴麗臺販售,麗臺長期深耕專業 GPU 領域,不僅具備堅實的技術實力,更擁有完整的技術支援與在地化服務體系,能協助企業快速導入高效能運算解決方案。
最後,NVIDIA 的專業繪圖卡產品,由捷元代理的麗臺科技NVIDIA專業繪圖卡產品提供完善的售後服務,不僅享有 3 年到府收送的保固服務,更有著免付費的客服專線「0800-600-206」,提供各領域的專業用戶最安心、穩定的創作、運算體驗。
關於捷元
捷元股份有限公司成立於 1988 年,是台灣領先的資訊與通信技術通路商,代理超過 60 個國內外知名品牌。作為亞太第一半導體零組件通路商-大聯大集團旗下鑫聯大投控(3709)成員,捷元37年來在全台深耕,佈建了完善的營運網絡,包括三大物流中心、八個營業據點及超過 10,000 家以上服務經銷夥伴。
捷元致力於成為高價值平台服務公司為目標,創造多元服務商機,在多年通路經營的深厚底蘊下,提供即時、多樣及專業技術支援及多元化解決方案,搭配快速物流與顧客導向的服務,透過捷元B2B 採購平台與經銷夥伴緊密連結,建構多元化行銷平台及完整銷售生態圈,協助合作夥伴提升競爭力,同時推動永續經營發展。
邀請您填寫獲取最新 NVIDIA 訊息:https://forms.gle/b8xgTTnUNLkzvunRA
-
 夢幻甜蜜點!酷!PC【薄荷馬卡龍】【香草馬卡龍】雙色特仕機。on 2026-05-11
夢幻甜蜜點!酷!PC【薄荷馬卡龍】【香草馬卡龍】雙色特仕機。on 2026-05-11 -
 【開箱】垂直貫流氣場,性能與藝術的「布」局!TRYX FLOVA F50織感機殼。on 2026-05-10
【開箱】垂直貫流氣場,性能與藝術的「布」局!TRYX FLOVA F50織感機殼。on 2026-05-10 -
 媽媽要你平時省一點,這次你就省給她看!CHERRY 指定機械式鍵盤限量優惠再送7-11禮券!on 2026-05-09
媽媽要你平時省一點,這次你就省給她看!CHERRY 指定機械式鍵盤限量優惠再送7-11禮券!on 2026-05-09 -







{kind=link}