
Google 發布 Gemini Embedding 2 模型,支援多模態交錯輸入
近日,Google 正式推出 Gemini Embedding 2 模型,並開啟公開預覽;作為首款基於 Gemini 架構打造的原生多模態嵌入模型,可提供文字、圖像、視訊、音訊與文件的統一嵌入處理。

透過簡化複雜的跨媒體處理流程,該模型能顯著增強 RAG(檢索增強生成)與語意搜尋應用的處理能力。
在多模態處理上,Gemini Embedding 2 也提供具體的規格支援:
- 文本輸入:上下文長度可達 8,192 個 Token。
- 影像處理:單次請求可處理 6 張 PNG/JPEG 圖片。
- 視訊支援:支援長達 120 秒的 MP4/MOV 視訊輸入。
- 原生音訊:無需事先轉錄,即可直接處理音訊資料。
- 文件嵌入:支援直接嵌入 6 頁以內的 PDF 文件。
此外,也支援多模態交錯輸入(如圖文混合),進而精準捕捉不同媒體間的複雜關聯,完美貼合現實世界中複雜的資料場景。
並且採用俄羅斯套娃的表徵學習技術(Matryoshka Representation Learning, MRL);其輸出維度可從預設的 3,072 維度進行動態縮放;Google 也推薦使用 3,072、1,536 或 768 維度,讓開發者能在保障處理品質的前提下,可依據儲存需求靈活調整。

而性能表現,Gemini Embedding 2 樹立了多模態嵌入的新標桿,尤其在語音處理方面;而文字、圖像、視訊等跨媒介檢索任務,也優於同類主流模型。

目前 Google 表示到,已有 Everlaw 與 Sparkonomy 等企業已作為早期合作夥伴,在法律檢索及創作者經濟等領域實現顯著的效率提升;並宣布即日起,開發者也可透過 Gemini API 與 Vertex AI 存取此模型。
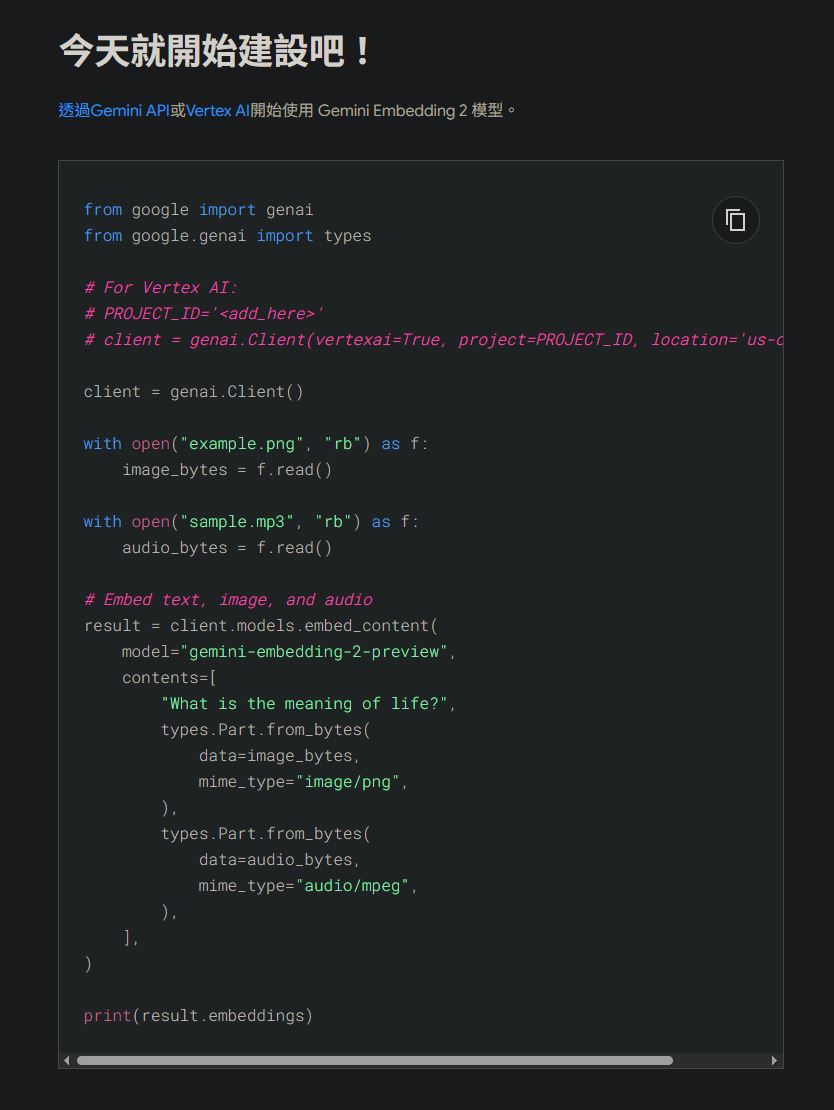
Google 更同步提供式碼範例與互動式筆記,協助開發者快速建構新一代多模態 AI 應用。
-
 【原價屋預購】頂級豪宅送 1000W 白金電源只此一檔!微星 MEG MAESTRO 900R 旗艦機殼。on 2026-07-09
【原價屋預購】頂級豪宅送 1000W 白金電源只此一檔!微星 MEG MAESTRO 900R 旗艦機殼。on 2026-07-09 -
 是大暑不是大薯,第二件照樣六折!MSI 電競周邊暑假補給餐開賣啦!on 2026-07-09
是大暑不是大薯,第二件照樣六折!MSI 電競周邊暑假補給餐開賣啦!on 2026-07-09 -
 【即刻預購】天龍特攻,飛向宇宙無敵手!MSI 40周年史詩天龍座&玩具總動員特仕版筆電!on 2026-07-09
【即刻預購】天龍特攻,飛向宇宙無敵手!MSI 40周年史詩天龍座&玩具總動員特仕版筆電!on 2026-07-09 -
 鮫鯊狂鱗,戰鬥陀螺。on 2026-07-08
鮫鯊狂鱗,戰鬥陀螺。on 2026-07-08






{kind=link}