
看我怎麼贏!AMD 新一代 “Zen 5″、”XDNA 2” 與 “RDNA 3.5” 架構更新重點

AMD Tech Day 活動帶來更詳細的 Ryzen 9000 系列 Granite Ridge 桌上型處理器,以及 Ryzen AI 300 系列 Strix Point 筆電處理器的架構更新重點,兩款全新產品都將在 7 月與玩家見面。桌上型處理器採用 Zen 5 核心架構,而行動處理器包辦 Zen 5、XDNA 2 與 RDNA 3.5 等架構更新。
首先「Zen 5」架構更新主要提升每週期的指令處理速度、加寬 Dispatch 與執行線程,為了負擔各大的處理速度也隨著加大快取資料的頻寬,並針對 AI 加速改進 FP 運算單元。

這代 Zen 5 的 Front-end 採用雙管齊下增加 Fetch、Decode 的管線,搭配分支預測降低延遲、提升精準度與吞吐量,而指令快取也降低延遲提升頻寬。總之 Front-end 能同時處理更多的指令提高整體效率。

隨著前端的雙管齊下,整數執行單元也加寬 8-wide 的 Dispatch / Retire 管線,有著 6 ALU、3 Multiplies 單元與更多的統一 ALU Scheduler 與更大的 Execution Window。
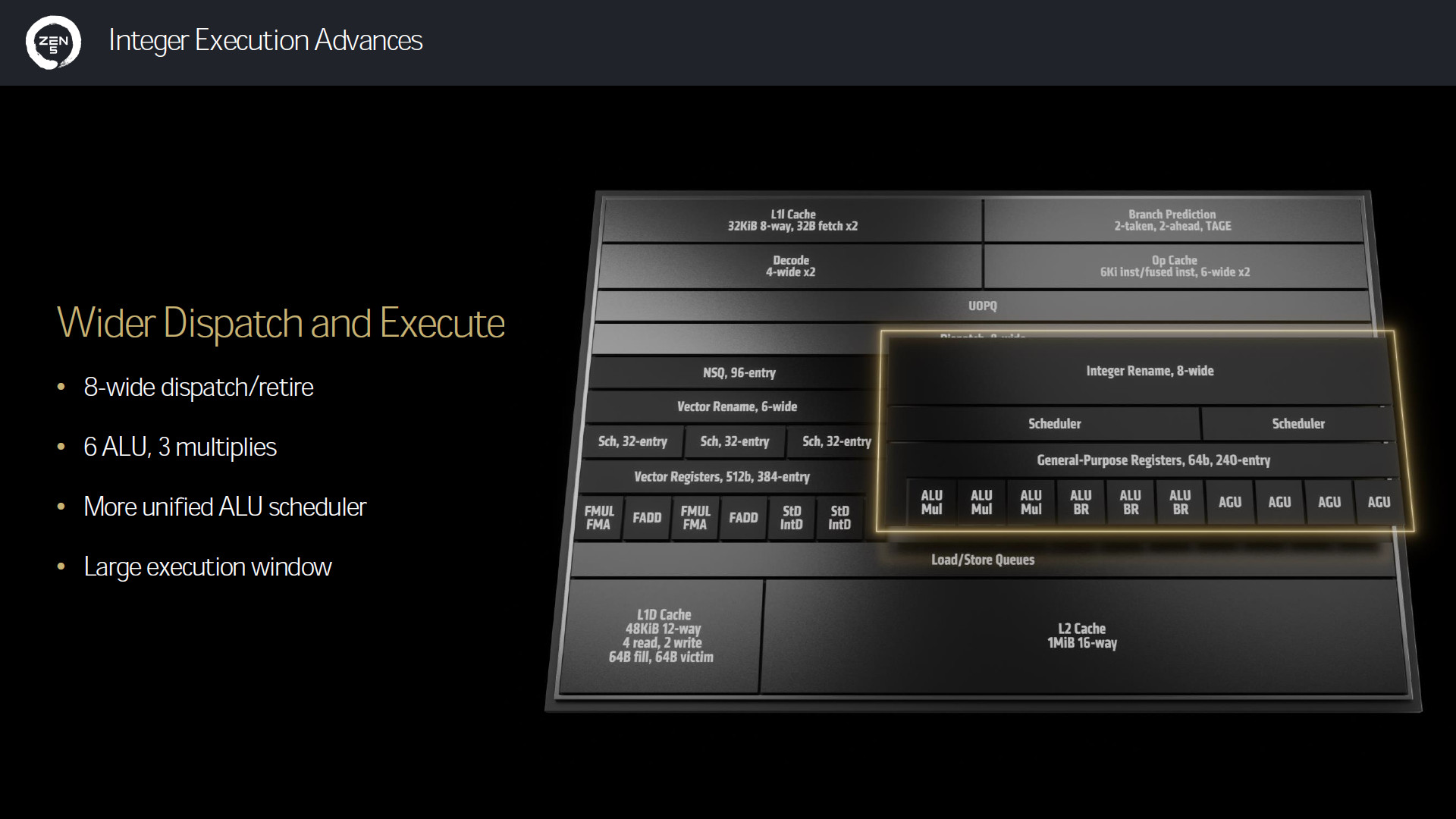
Load/Store 單元也跟著加大,有著 48KB 12-way L1 Data 快取 4 read, 2 write,並加倍最高頻寬至 L1 快取與浮點數 FP 單元,提升資料預取的效率。

Zen 5 核心另一大重點更新 512-bit AI Datapath 的 FP/Vector 單元,可支援 512-bit 資料的 AVX-512 指令、6 管線與 2 個週期延遲的 FADD,可處理更多的 FP 指令。擴大 FP/Vector 數學處理執行單元,其目的是為了讓 CPU 在處理一些 AI 模型時,能有著更快速的反應與效能,面對未來各種 AI 應用。

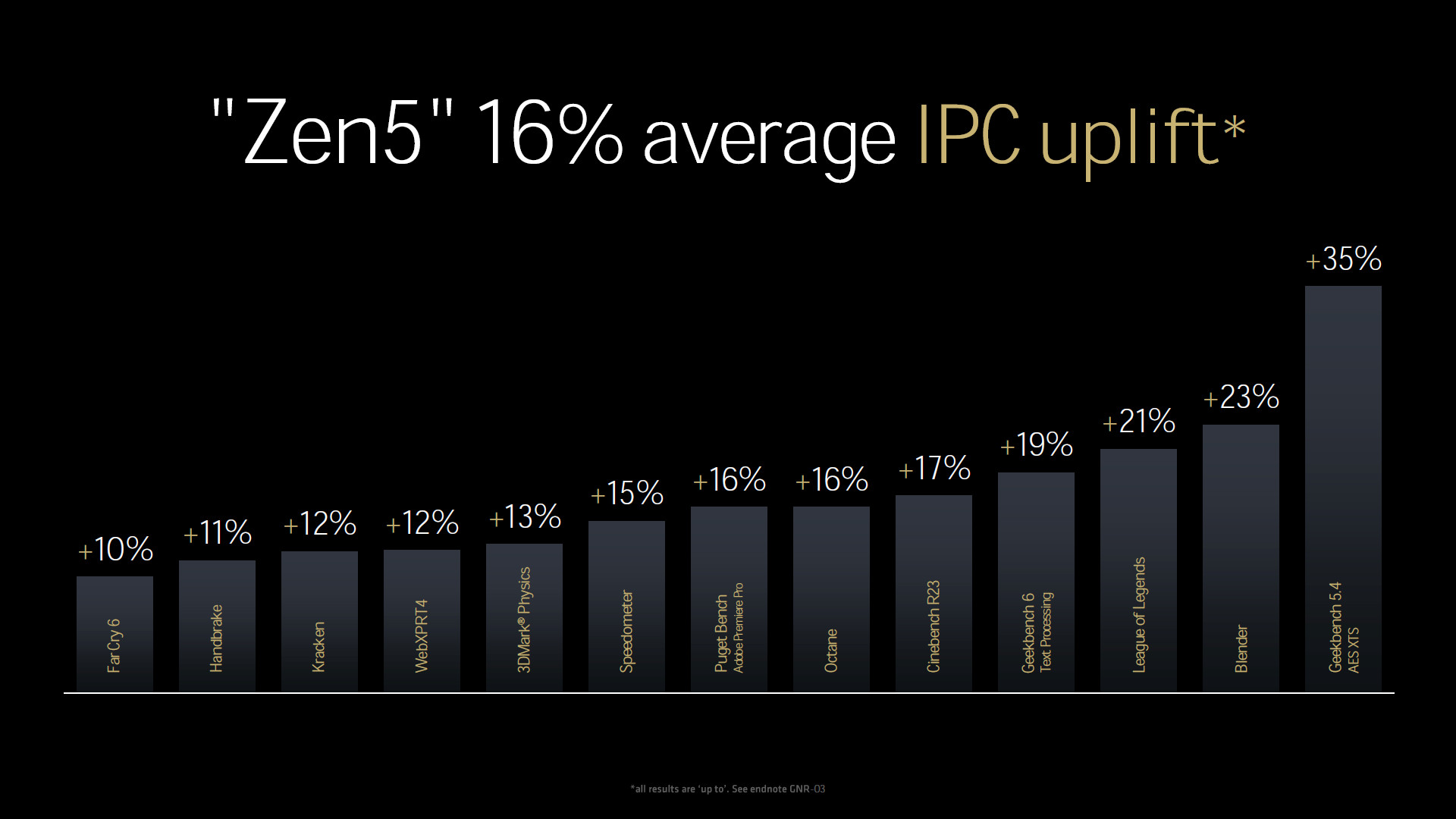
Zen 5 核心架構在各項成績與 Zen 4 架構相比可達到 16% 的 IPC 提升,並且在單核心機器學習運算有著 32% 提升、單核心 AES-XTS 加密有著 35% 的提升。

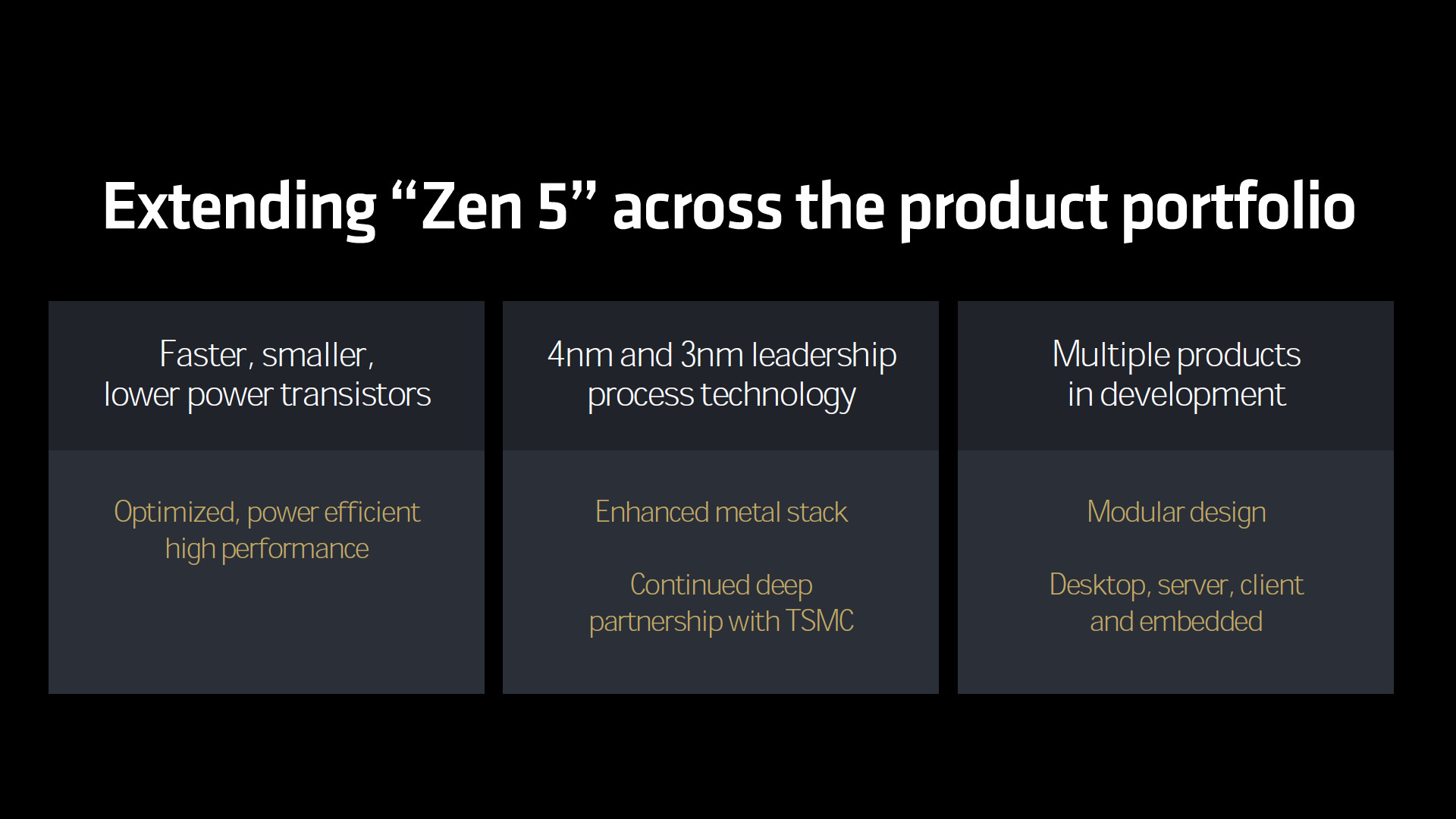
Zen 5 架構可帶來更高的效能與電源效率,並深度與 TSMC 合作採用 4nm 與 3nm 製程,同時包含桌上型、伺服器與行動處理器等產品。像是桌上型的 Granite Ridge、筆電處理器 Strix Point 與伺服器 EPYC “Turin” 都會採用 Zen 5 架構。


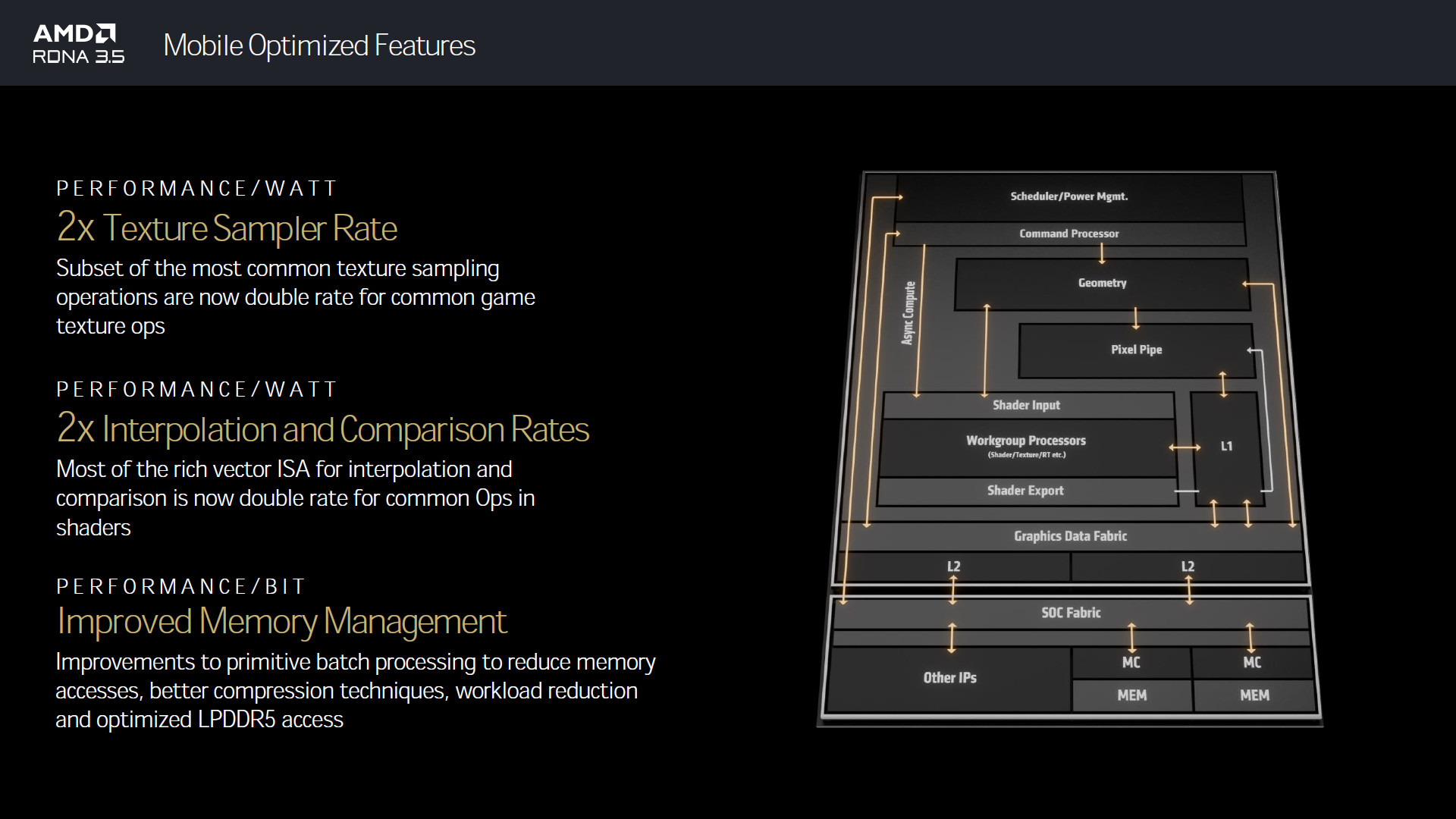
緊接著「RDNA 3.5」架構更新,今年規劃上似乎沒有新一代 GPU 的規劃,而這個 RDNA 3.5 是針對筆電處理器 Strix Point 的內顯晶片的優化架構,針對每瓦效能、記憶體每 bit 效能與更長的電池續航進行架構優化。

RDNA 3.5 針對每瓦效能優化帶來 2 倍 Texture Sampler Rate 與 Interpolation / Comparison Rate,這是針對繪圖最常見的兩項操作加倍處理速度,並針對 LPDDR5 進行批次處理降低記體存取次數與更好的壓縮技術,提升記憶體每 bit 操作的效能。
Strix Point 的 RDNA 3.5 內顯效能相比 Hawk Point(Ryzen 8000 / 8040)在同樣 15W 功耗下,Strix Point 在 DX12 測試的 Timespy 可有著 32% 的提升,而針對內顯 DX12 測試的 Night Raid 則有著 19% 的每瓦效能提升。

Strix Point 除了 Zen 5、RDNA 3.5 外另一個大重點 XDNA 2,可提供 50 TOPS 的 NPU AI 運算效能。
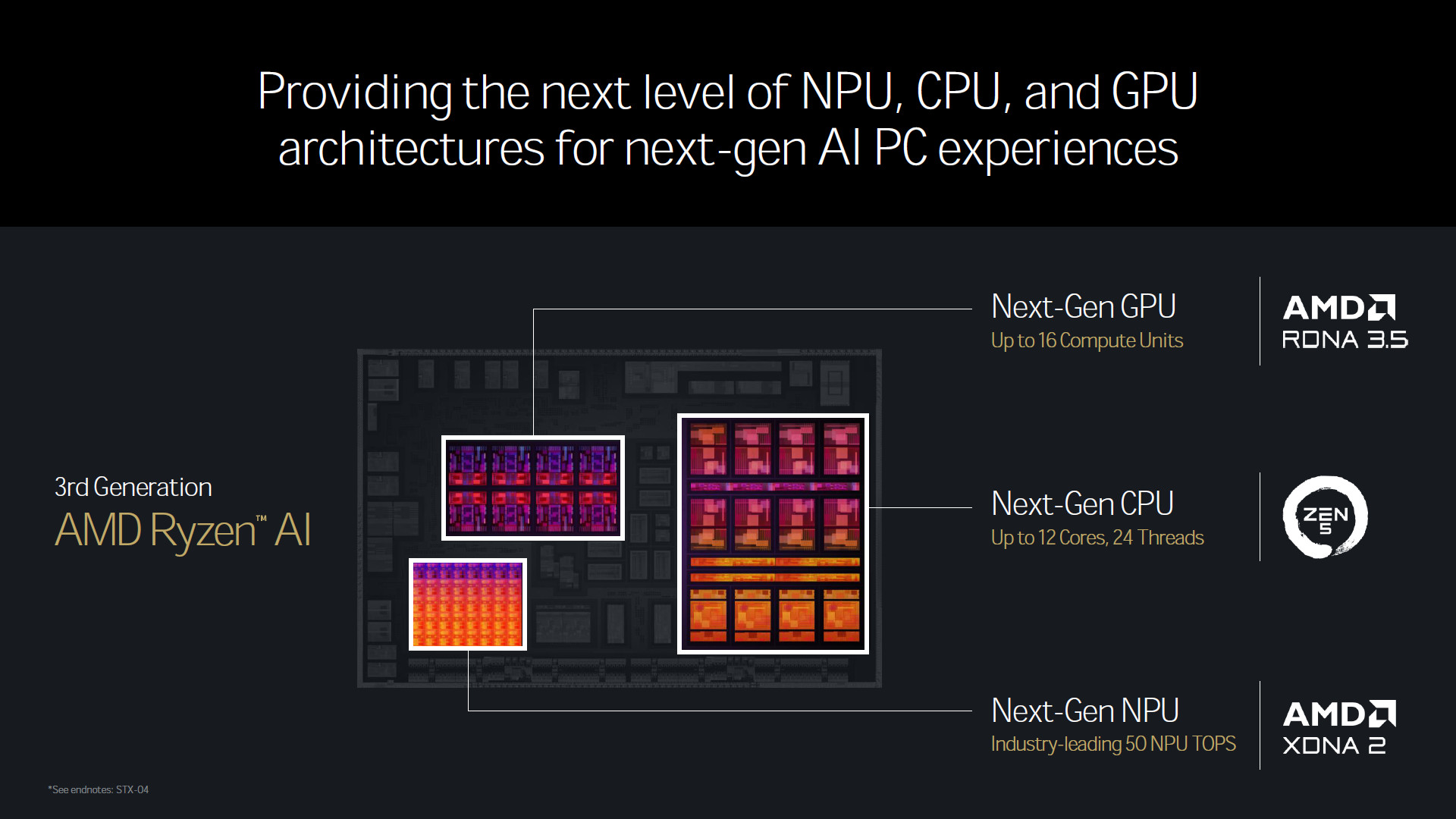
AMD XDNA 架構設計上非一般傳統的多核心處理器設計,XDNA 反而更像是 GPU 這種平行處理器,有著彈性的運算單元與記憶體制度。

XDNA 的每個 AIE Tile 可通過軟體控制的 Interconnect 來進行分區,XDNA 2 的 32 個 AIE Tile 可以透過分區同時提供即時的 AI 影像、AI 音效的處理,以及 AI 創作內容的運算使用。
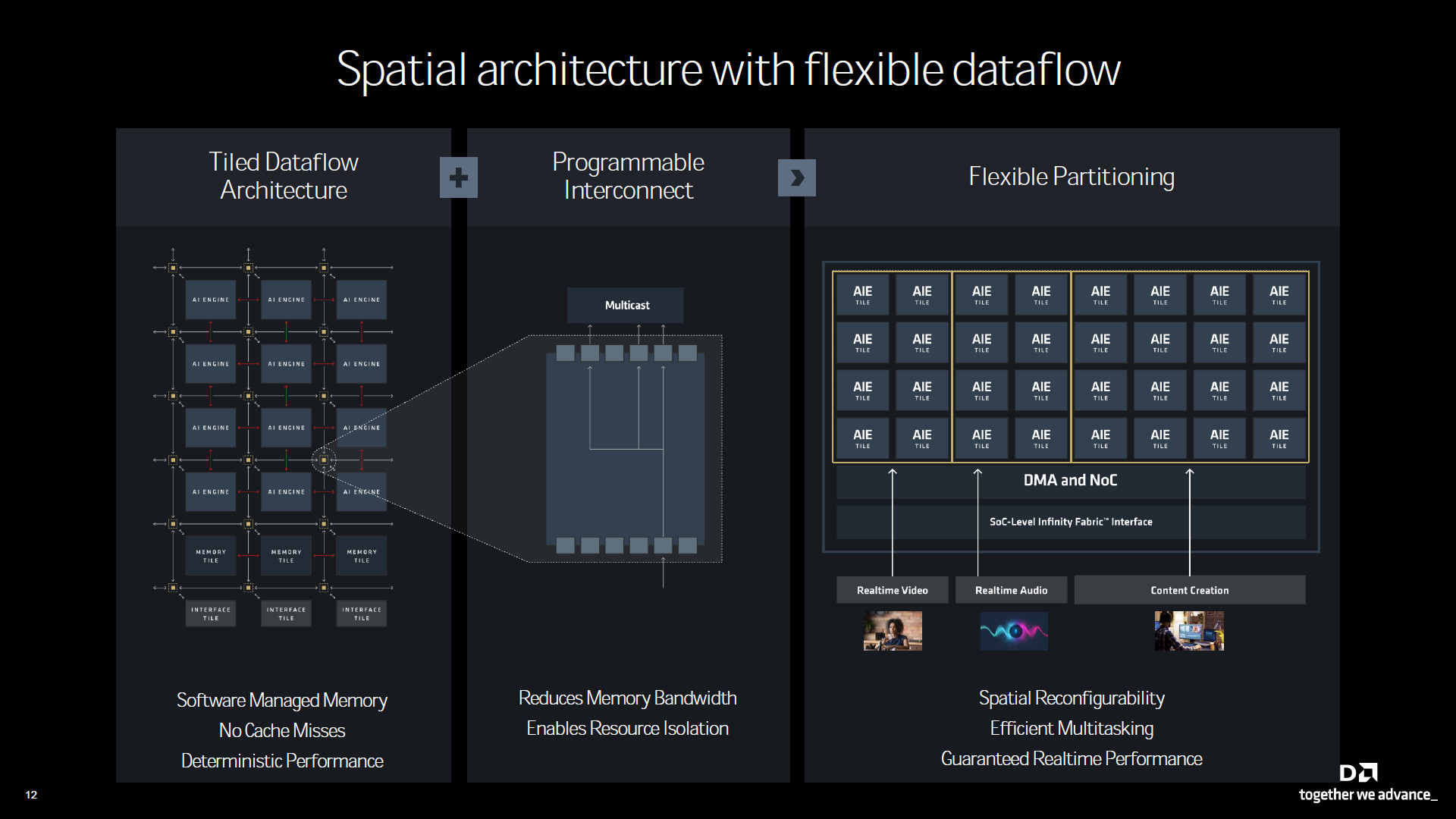
XDNA 2 擁有 32 個 AIE Tile、50 TOPS 的 NPU 運算能力,強化非線性的處理、Block 浮點數運算,同樣加大 1.6x 的晶片記憶體與 2x Macs per tile。相比上一代能具備 5x 倍的運算能力、2x 倍的電源效率的提升。


對於 AI 運算來說資料類型至關重要, Int 8 的資料可帶來高速效能但運算準確性相對低,而 FP16 則可有著高準確性但必須犧牲效能,因此 AMD 採用 Block FP16 的資料類型,這是基於 fixed-point 定點數的算法逼近浮點數,藉此獲得接近 Int 8 的效能與 FP16 的準確性。

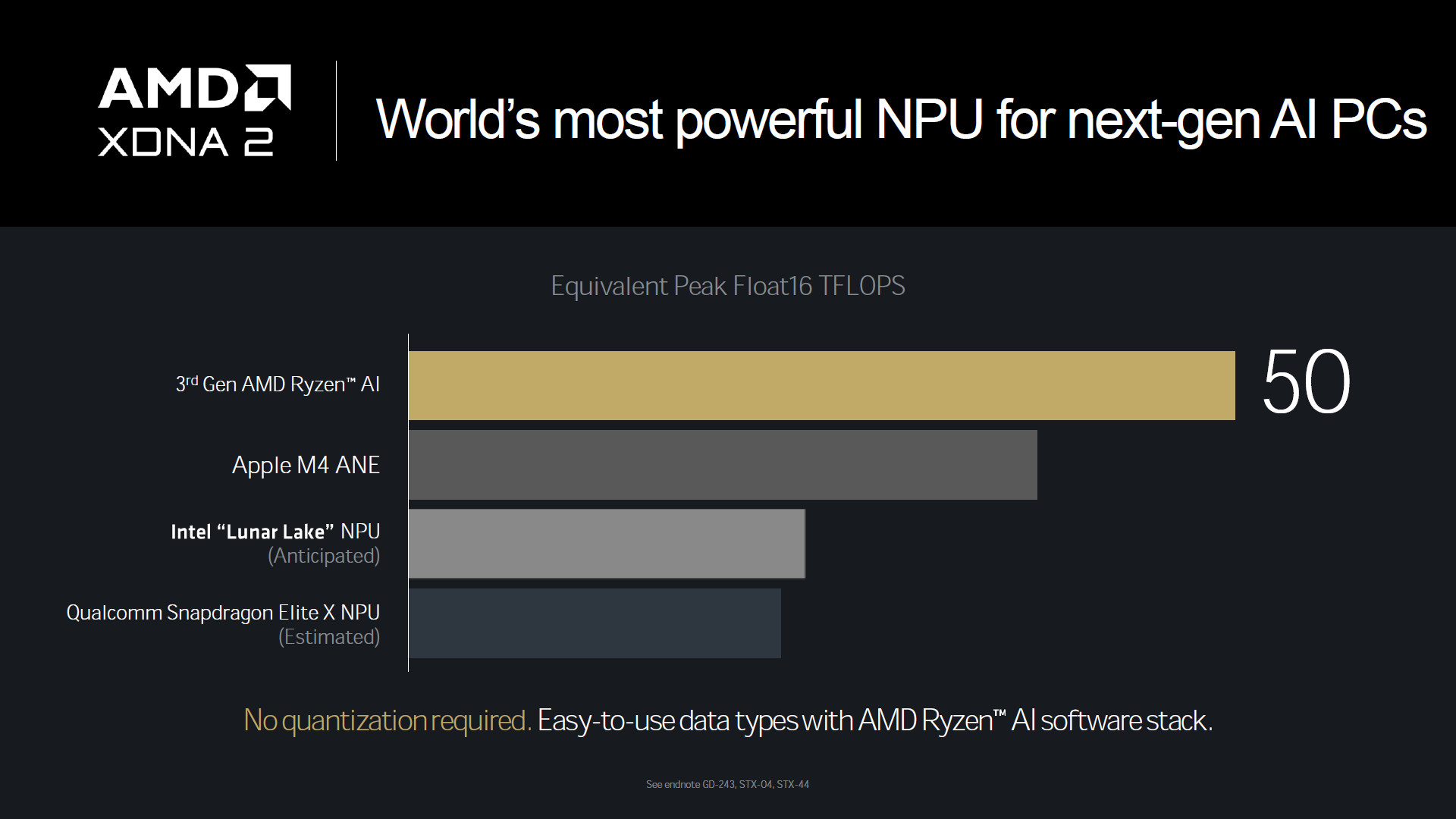
在個平台比較 Float16 的峰值效能時,XDNA 2 可具備 50 TFLOPS 的效能,遠超 Apple、Intel 與 Qualcomm 等處理器的處理效能。
Block FP16 的資料類型其精準度僅微微的低於 FP32 的基準線,而且這資料類型對於 ISV 軟體開發商,可相當容易的將模型轉成 FP16、FP32 或 BF16 等資料類型。

在大型語言模型 Llama v2 7B 的 time to first token 測試中,第三代 Ryzen AI NPU 有著 5x 倍快的反應速度相比 Intel 155H NPU 的效能。

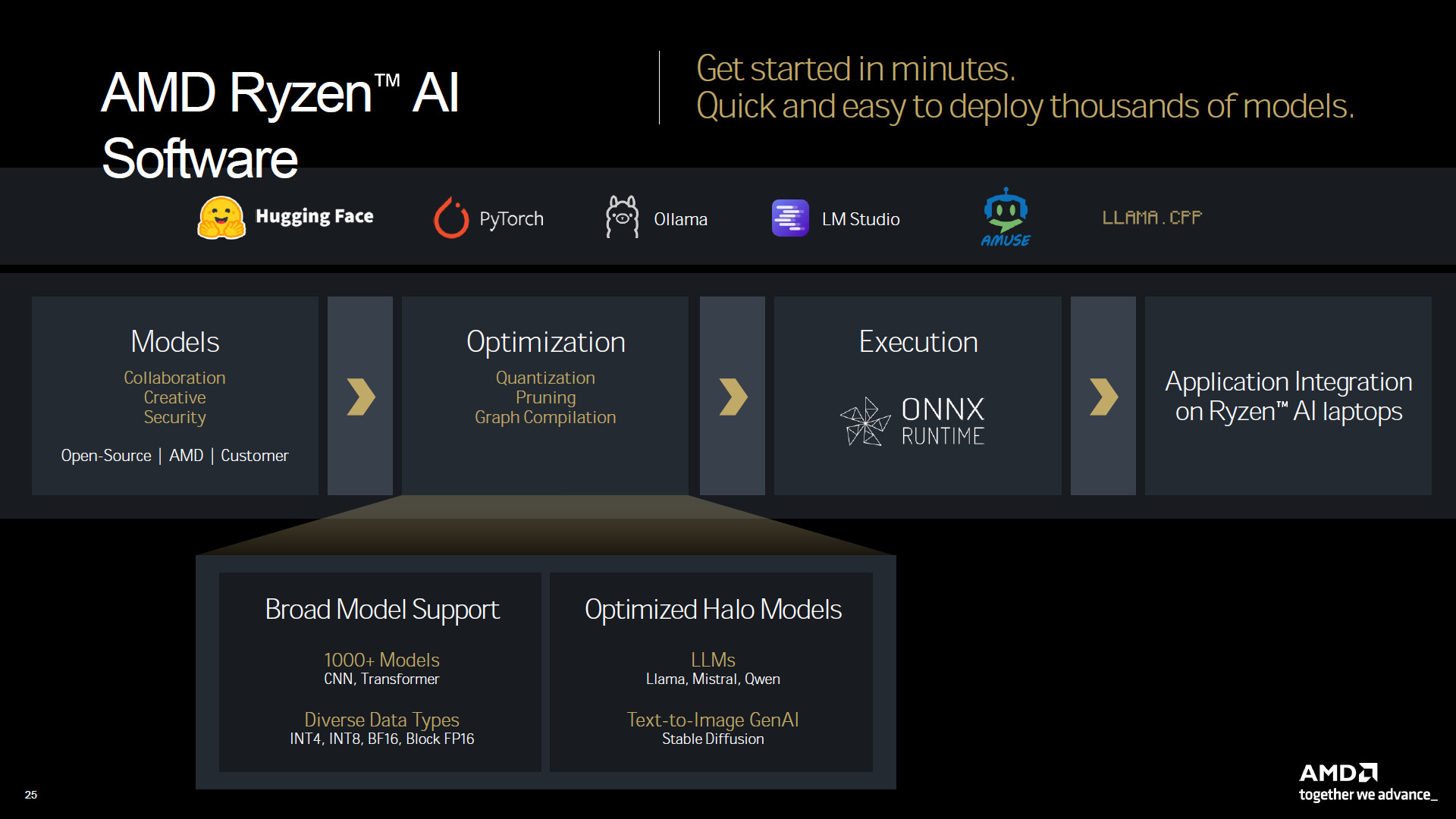
AMD 也計畫推出 Ryzen AI Software 可支援各種模型、優化,並藉由 ONNX Runtime 執行,讓未來 Ryzen AI 筆電能夠具備更多的 AI 應用功能。
AMD 預計在 7/31 日推出 Ryzen 9000 系列處理器,而 Ryzen AI 300 系列筆電處理器,則是由筆電製造商在 7 月推出。想要組裝新電腦的玩家,不妨等等 7 月底的效能解禁。
-
 【門市限定】視覺戰力全進化!ACER指定系列螢幕送mycard 300點數卡!on 2026-03-18
【門市限定】視覺戰力全進化!ACER指定系列螢幕送mycard 300點數卡!on 2026-03-18 -
 極致輕薄,AI 致勝效能!NVIDIA GeForce RTX 50 系列筆電。on 2026-03-18
極致輕薄,AI 致勝效能!NVIDIA GeForce RTX 50 系列筆電。on 2026-03-18 -

-
 【原價屋搶購】MSI x TGS 2026電玩展體驗機,限量最高送$16000!on 2026-03-17
【原價屋搶購】MSI x TGS 2026電玩展體驗機,限量最高送$16000!on 2026-03-17






{kind=link}