
NVIDIA Hopper 在 MLPerf 的生成式人工智慧領域取得飛躍性進展

NVIDIA 正式宣布在業界標準測試中提供了世界上最快的生成式人工智慧(AI)推論平台。
在最新的 MLPerf 基準測試中,NVIDIA TensorRT-LLM 這個可加速和簡化大型語言模型的複雜推論工作的軟體將 GPT-J LLM 上的 NVIDIA Hopper 架構 GPU 效能較六個月前提高了近 3 倍。
速度的大幅提升展示了 NVIDIA 的晶片、系統和軟體全端平台在滿足運行生成式 AI 嚴苛要求方面的強大能力。
諸多領先的公司正在使用TensorRT-LLM 最佳化他們的模型。而 NVIDIA NIM 是一套推論微服務,其中包含 TensorRT-LLM 等推論引擎,讓企業比以往能更輕鬆地部署 NVIDIA 推論平台。
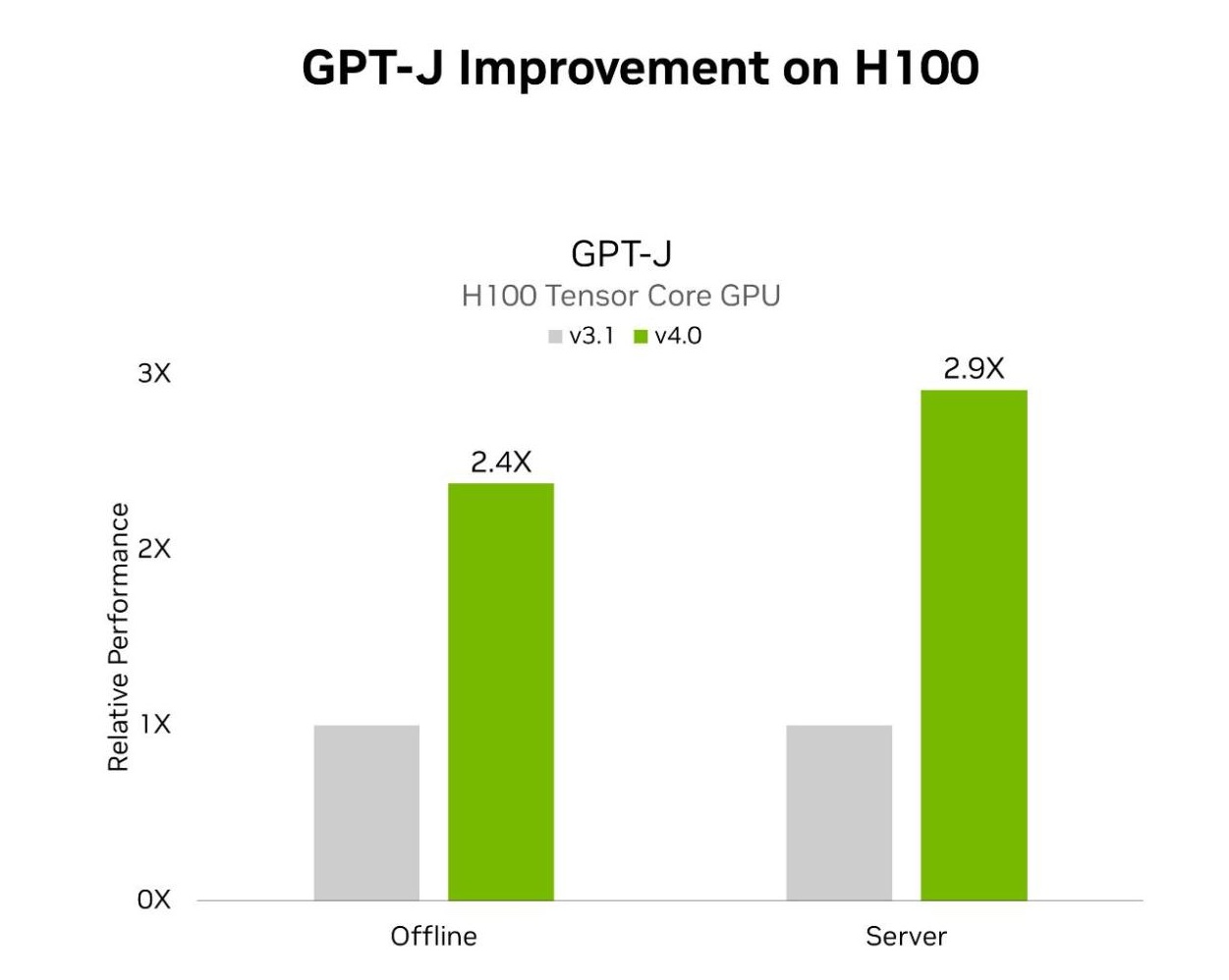
提高生成式 AI 的標準
在NVIDIA H200 Tensor核心GPU(最新的記憶體增強型 Hopper GPU)上運行的 TensorRT-LLM,在 MLPerf 迄今為止最大規模的生成式 AI 測試中提供了最快的運行推論效能。
新的基準測試使用 Llama 2 的最大版本,Llama 2 是最先進的大型語言模型,包含 700 億個參數。該模型比 9 月基準測試中首次使用的 GPT-J 大型語言模型大 10 倍以上。
記憶體增強型 H200 GPU 在 MLPerf 首次亮相時,使用 TensorRT-LLM 每秒產生高達 31,000 個詞元,創下了 MLPerf 的 Llama 2 基準測試的紀錄。
H200 GPU 的結果包括客製化散熱解決方案帶來的高達 14% 的增益。這是標準空氣冷卻以外的創新範例之一,系統製造商正在將其應用到 NVIDIA MGX 設計中,以將 Hopper GPU 的效能提升到新的高度。
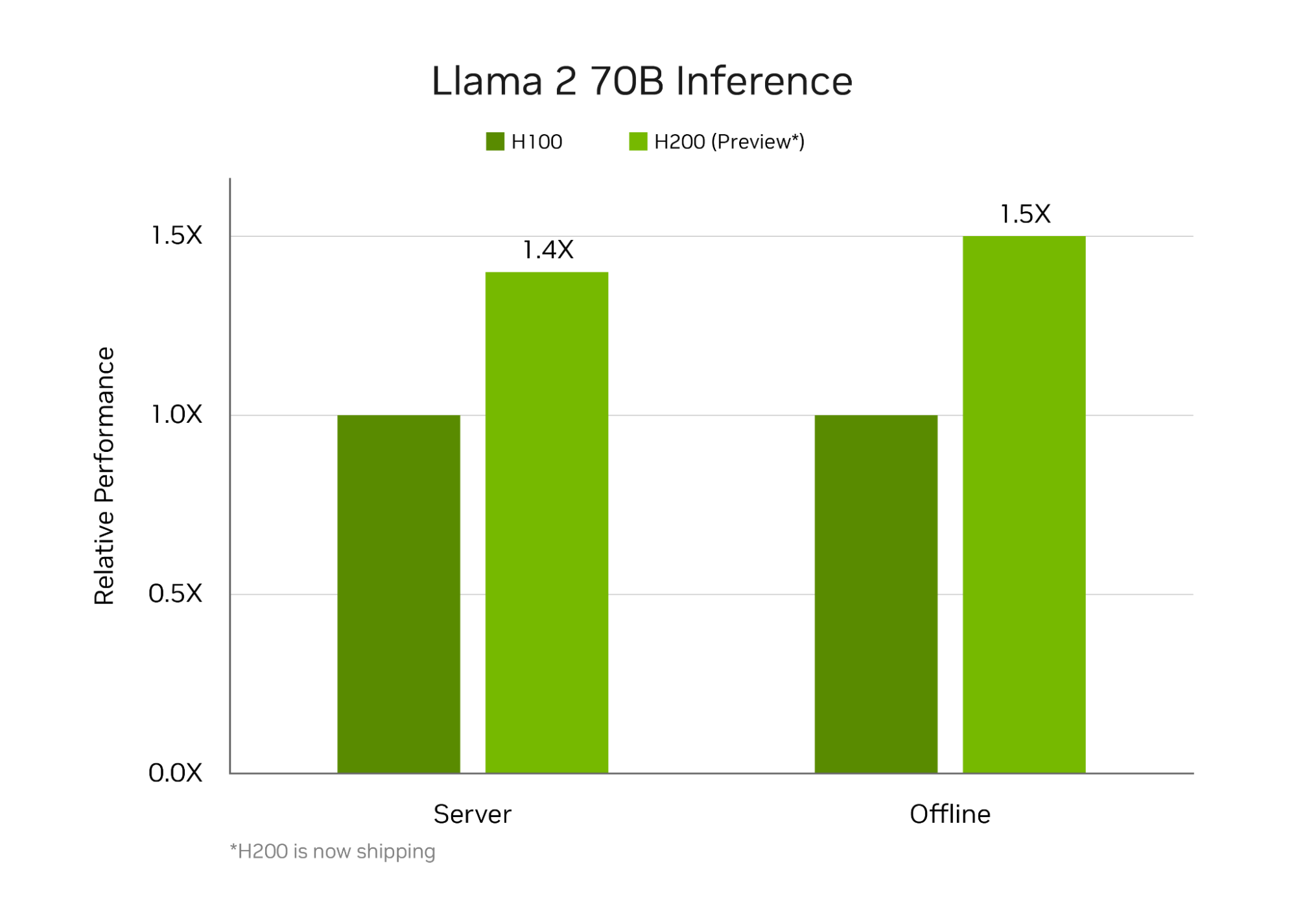
NVIDIA Hopper GPU 的記憶體提升
NVIDIA 現在已提供 H200 GPU 供客戶測試,並將於第二季出貨。H200 GPU 很快將由近 20 家領先的系統製造商和雲端服務供應商來提供。
H200 GPU 包含 141GB 高頻寬記憶體 HBM3e,運轉速度為 4.8TB/s。與 H100 GPU 相比,記憶體增加了 76%,運行速度提高了 43%。這些加速器可插入與 H100 GPU 相同的主機板和系統,並使用相同的軟體。
借助 HBM3e 記憶體,單個 H200 GPU 能以最高吞吐量運行整個 Llama 2 70B 模型,從而簡化並加速推論。
GH200 配備更多的記憶體
NVIDIA GH200 超級晶片中配備更多記憶體,最高可達 624GB 高速記憶體,其中包含 144GB 的 HBM3e 記憶體,此超級晶片將 Hopper 架構 GPU 和節能的 NVIDIA Grace CPU 結合在一個模組上。NVIDIA 加速器是首批使用 HBM3e 記憶體技術的加速器。
憑藉將近 5 TB/s 的記憶體頻寬,GH200 超級晶片在如推薦系統等記憶體密集型的 MLPerf 測試中提供了出色的效能。
橫掃每一個 MLPerf 測試
以每個加速器為基礎,Hopper GPU 在最新一輪MLPerf產業基準測試中,橫掃了所有AI推論測試。
這些基準測試涵蓋當今最受歡迎的AI工作負載和場景,包括生成式AI、推薦系統、自然語言處理、語音和電腦視覺。NVIDIA是唯一一家在最新一輪以及自 2020 年 10 月開始 MLPerf 資料中心推論基準測試以來,每一輪都提交所有工作負載結果的公司。
持續的效能提升意味著推論成本的降低,對於全球部署的數百萬個NVIDIA GPU來說,推論已成為日常工作中的一大部分,而且還在不斷增長。
推進一切可能
NVIDIA在基準測試中一個名為「開放組」的特別部分中展示了三種創新技術,這部分是為了測試先進的AI方法而創建。
NVIDIA 工程師使用了一種稱為結構化稀疏性(structured sparsity)的技術,使 Llama 2 的推論速度提高了 33%。結構化稀疏性是一種減少計算的方法,首次在 NVIDIA A100 Tensor核心GPU 中引入。
第二個開放組測試發現,使用剪枝技術(pruning)可以將推論速度提高高達40%,這是簡化AI模型(此例為大型語言模型)以增加推論吞吐量的一種方式。
最後,一種名為 DeepCache 的最佳化方法減少了對 Stable Diffusion XL 模型推論所需的數學運算,將效能提升了驚人的 74%。
所有這些結果都是在NVIDIA H100 Tensor核心GPU 上運行的。
使用者值得信賴的來源
MLPerf 的測試透明且客觀,因此使用者可以依靠結果做出明智的購買決定。
NVIDIA 的合作夥伴參與 MLPerf 是因為他們知道這對客戶評估 AI 系統和服務來說是一個很有價值的工具。
本輪在NVIDIA AI平台上提交結果的合作夥伴包括華碩電腦、思科、戴爾科技集團、富士通、技嘉科技、Google、慧與科技、聯想、Microsoft Azure、甲骨文、雲達科技、美超微、VMware(最近由博通收購)和緯穎科技。
NVIDIA在本次測試中使用的所有軟體都可以從MLPerf資源庫中取得,NVIDIA不斷將軟體最佳化結果放入NVIDIA的GPU應用軟體中心NGC以及 NVIDIA AI Enterprise的容器中。NVIDIA AI Enterprise為一個安全、受支援的平台,其中包含 NIM 推論微服務。
下一件大事
生成式AI的用例、模型大小和資料集不斷擴大。這就是 MLPerf 不斷發展的原因,增加了 Llama 2 70B 和 Stable Diffusion XL等主流模型的真實測試。
為了跟上大型語言模型規模的爆炸性增長,NVIDIA 創辦人暨執行長黃仁勳上週在GTC上宣布,NVIDIA Blackwell 架構 GPU將提供兆級參數 AI 模型所需的新效能水平。
大型語言模型的推論非常困難,需要專業知識和 NVIDIA 使用 Hopper 架構 GPU 和 TensorRT-LLM 在 MLPerf 上展示的全端架構。未來還會有更多。
了解有關 MLPerf 基準測試和本輪推論的技術細節。
-
 集結龍魂之力,尋找命定最強戰友!入主微星 MSI 電競主機加送 $1,990 電競鍵鼠組!on 2026-04-12
集結龍魂之力,尋找命定最強戰友!入主微星 MSI 電競主機加送 $1,990 電競鍵鼠組!on 2026-04-12 -
 8折全面翻新你的遊戲間!COUGAR指定電競桌/椅/沙發優惠開跑!on 2026-04-11
8折全面翻新你的遊戲間!COUGAR指定電競桌/椅/沙發優惠開跑!on 2026-04-11 -
 90 天故障換新承諾!原價屋 x 致態 ZHITAI 固態硬碟快換中心成立!on 2026-04-10
90 天故障換新承諾!原價屋 x 致態 ZHITAI 固態硬碟快換中心成立!on 2026-04-10 -
 嗑了AI效能Get嗨!HP HyperX OMEN 15-ga0008TX筆電優惠送無線電競滑鼠!on 2026-04-10
嗑了AI效能Get嗨!HP HyperX OMEN 15-ga0008TX筆電優惠送無線電競滑鼠!on 2026-04-10






{kind=link}