
NVIDIA Maxine 雲端 AI 視訊技術 Vid2Vid Cameo 讓會議畫面更完美
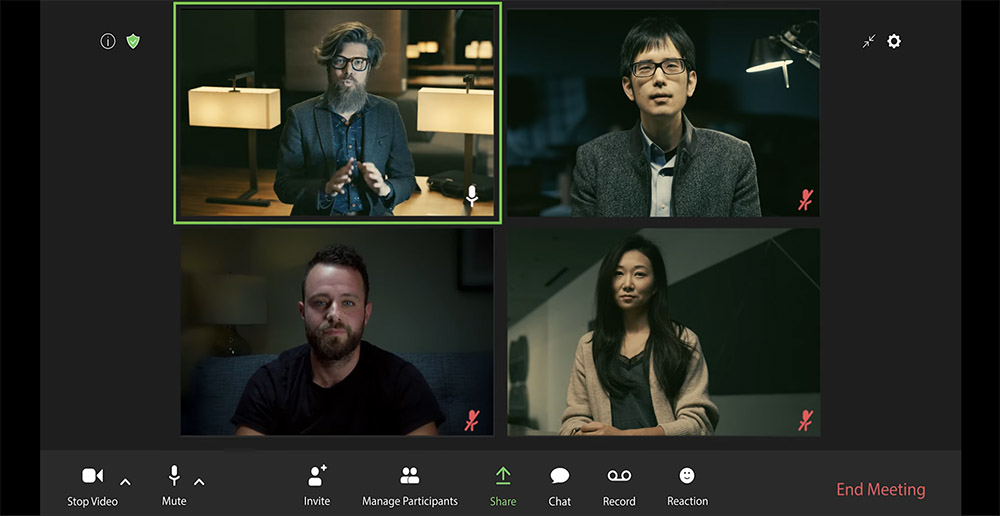
NVIDIA 研究人員所開發的 AI 工具 NVIDIA Maxine SDK 當中,有著相當多的深度學習模型其中包含 Vid2Vid Cameo,這模型利用生成對抗網路 (GAN),只需你的一張平面照片,就能產生出不同角度、立體的頭像。
就像 NVIDIA 敬致 Netflix 播出的《紙房子》影集中視訊的畫面,由 NVIDIA 研究人員來說明 Vid2Vid Cameo 可提供給視訊會議更完美的人體頭像,參與者只需要在加入視訊通話前先上傳一張參考圖片,可以是自己的真實照片或卡通圖片,就能使用這項功能。
Vid2Vid Cameo 只需要兩個元素,便能建立出用於視訊會議的逼真 AI 對話頭像,包含一張使用者的臉部照片以及一個視訊串流內容,該模型在 NVIDIA DGX 系統上使用 18 萬個高品質對話頭像的資料集來進行訓練。
Vid2Vid Cameo 的模式能夠辨識臉部的二十個關鍵點,這些關鍵點針對包括眼睛、嘴巴和鼻子在內的特徵位置進行編碼,接著模型會從通話者的參考圖片中擷取這些關鍵點,通話者的圖片可以事先發送給其他參與視訊會議的人,或從過往的會議中重複使用。
如此一來,視訊會議平台只需發送說話者臉部關鍵點的動作資料,而不用在每一個與會者之間發送龐大的即時視訊串流內容;對接收者來說,GAN 模型在接收端使用這些資訊來合成一個模仿參考圖片外觀的視訊內容。


利用 Vid2Vid Cameo 後,視訊會議只需傳送會議者臉部的位置及關鍵點,而並即時的在所有與會者電腦中,藉由 AI 來模擬出會議者的立體頭像,讓整體視訊會議品質可更佳流暢,且不影響視訊畫質。
NVIDIA 的研究人員發現,Vid2Vid Cameo 可以產生更為真實清晰的結果,不管參考圖片和視訊內容是否出自同一個人,還是當 AI 把一個人的動作轉移到另一個人的參考圖片上,它的表現都比最先進的模型更出色。

Vid2Vid Cameo 模型論文的作者為 NVIDIA 研究人員 Arun Mallya 和兩位來自台灣的 Ting-Chun Wang、和 Ming-Yu Liu。NVIDIA Research 團隊由全球兩百多名科學家組成,專注於 AI、電腦視覺、自動駕駛車、機器人和繪圖等領域。
在此特別感謝於 Netflix 播出的《紙房子》影集中,替教授進行英語配音的演員 Edan Moses,感謝他為上述我們最新的 AI 研究成果影片所做出的貢獻。
延伸閱讀:
-

-
 【門市限定】半價賦予螢幕自由!銀欣指定螢幕支架限量搭購優惠!on 2026-03-10
【門市限定】半價賦予螢幕自由!銀欣指定螢幕支架限量搭購優惠!on 2026-03-10 -
 和風大賞!Montech MKey Pro 75% 現折一千,送日系風格大鼠墊的限時雅興。on 2026-03-10
和風大賞!Montech MKey Pro 75% 現折一千,送日系風格大鼠墊的限時雅興。on 2026-03-10 -
 640g輕盈隨行,筆電視野翻倍!ACER PM161W 16吋攜帶型螢幕上市,限量再送藍芽靜音滑鼠一支。on 2026-03-09
640g輕盈隨行,筆電視野翻倍!ACER PM161W 16吋攜帶型螢幕上市,限量再送藍芽靜音滑鼠一支。on 2026-03-09

{kind=link}