
NVIDIA 與全球電腦製造商伙伴再創 MLPerf 人工智慧效能佳績

根據最新公布的 MLPerf 基準測試結果,NVIDIA 的合作夥伴目前提供用於訓練人工智慧 AI 的 GPU 加速系統,其速度較任何系統更快。
七間公司在最新一輪的產業基準測試中,提交至少十多套市售系統進行測試,其中大多為 NVIDIA 認證系統。NVIDIA 與戴爾 (Dell)、富士通 (Fujitsu)、技嘉 (GIGABYTE)、浪潮 (Inspur)、聯想 (Lenovo)、寧暢 (Nettrix) 及美超微 (Supermicro) 共同展示了使用 NVIDIA A100 Tensor 核心 GPU 訓練神經網路,所創造出引領業界的亮眼表現。
只有 NVIDIA 及其合作夥伴完整進行最新一輪基準測試中的八項作業負載。整體來說,搭載 NVIDIA 技術的提交資料共占了四分之三以上,且結果十分漂亮。
與去年的成績相比,NVIDIA 的效能表現提升了 3.5 倍。針對需要使用龐大運算資源的大規模作業,我們從破紀錄的 4,096 個 GPU 中集結資源,較任何其他參與測試的產品都還要更多。
MLPerf 為何如此重要
這是 NVIDIA 商業生態系第四度參加 MLPerf 訓練測試,也是表現最為亮眼的一次。MLPerf 為 2018 年 5 月成立的產業基準測試組織。
MLPerf 的測試成果讓用戶能在充分瞭解的情況下進行購買決策,並獲得數十間業界領導者的支持,包含阿里巴巴、Arm、百度、Google、英特爾 (Intel) 與 NVIDIA 等,其測試結果兼具透明性和客觀性。
這項測試基準以目前最熱門的 AI 作業負載和場景為基礎,涵蓋電腦視覺、自然語言處理、推薦系統、強化學習等,而訓練基準則聚焦於用戶最為關心的事情,也就是訓練一個全新 AI 模型所需耗費的時間。
速度加上彈性造就生產力
最終,客戶基礎設施投資的回報取決於他們的生產力。這來自於在運行多種 AI 作業負載時既快速又靈活的能力。
因此,這就是為什麼使用者需要一套靈活且強大的系統,能夠快速將各種 AI 模型投入生產環境並縮短上市時間,同時徹底發揮寶貴的資料科學團隊的生產力。
根據最新的 MLPerf 測試結果,NVIDIA AI 平台在商用 AI 超級電腦類別的所有八項基準測試中以最短的時間訓練模型,創下了效能記錄。
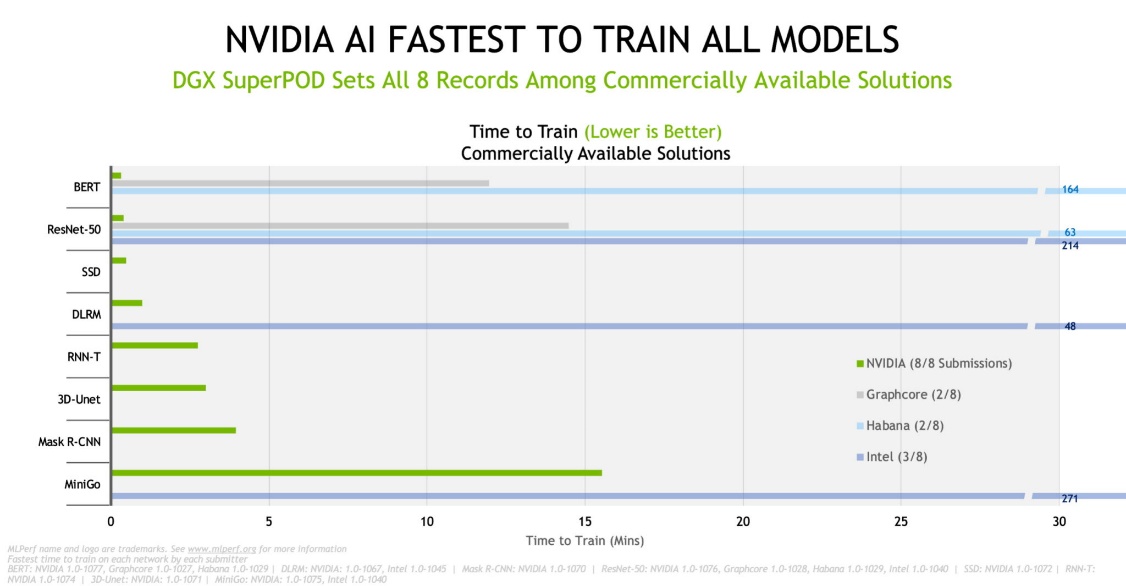
圖一_NVIDIA 基於 NVIDIA DGX SuperPOD 的 Selene 系統在商用系統上創造八項記錄
根據最新的 TOP500 排名,我們在當今世界上最快的商用 AI 超級電腦 Selene 上進行大規模測試。Selene 超級電腦與排行榜上其它十多套系統一樣,皆採用 NVIDIA DGX SuperPOD 架構。擴展到大型叢集的能力是 AI 領域最艱鉅的挑戰,也是我們的核心優勢之一。
在晶片對晶片的比較中,NVIDIA 及合作夥伴在最新的商用系統測試中創造八項基準測試的紀錄。

圖二_A100 在商用系統類別中創下了八項全紀錄
整體來說,下方的測試結果顯示我們的效能在兩年半內提升了 6.5 倍,這證明了可以在 GPU、系統和軟體的全堆疊 (full-stack) NVIDIA 平台上進行作業。
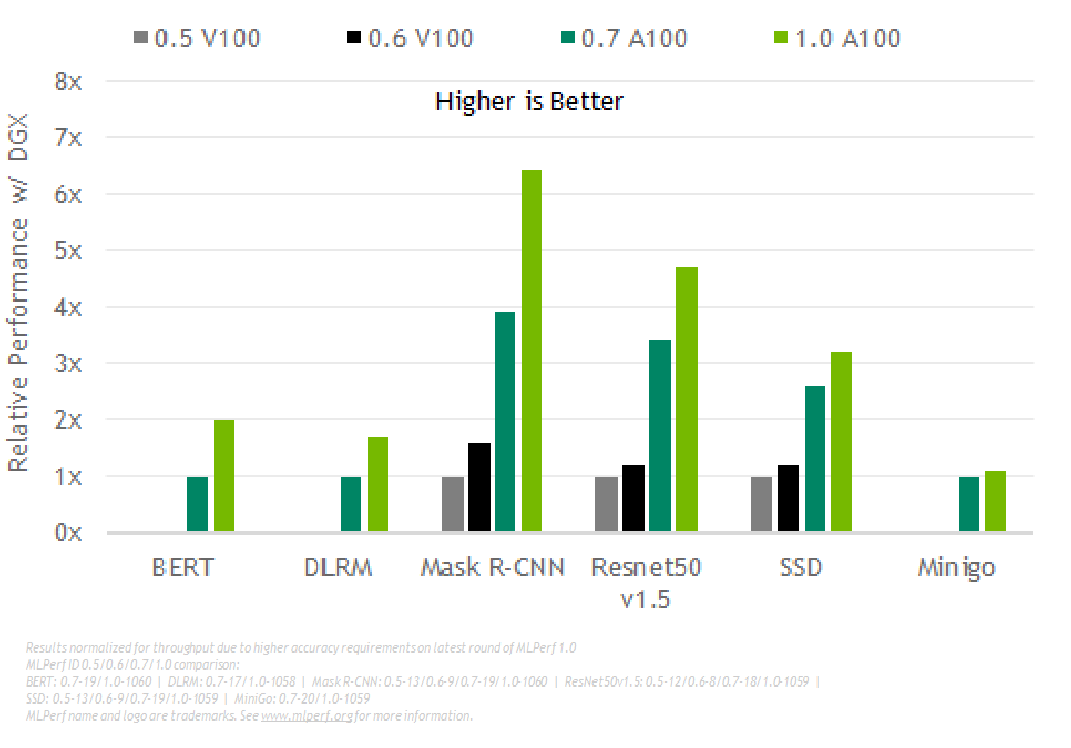
圖三_NVIDIA AI 透過全堆疊的改善帶來持續的效能提升
廣泛的生態系提供最佳價值和選擇
MLPerf 結果展示了各種基於 NVIDIA 的 AI 平台,以及許多創新系統的效能,包含從入門的邊緣伺服器到搭載數千個 GPU 的 AI 超級電腦。
參與最新基準測試的近二十家雲端服務供應商和 OEM 廠商,NVIDIA 的七個合作夥伴名列其中,其本地端的產品或計畫採用 NVIDIA A100 GPU 的雲端執行個體、伺服器和 PCIe 卡中,包括近 40 個 NVIDIA 認證系統。
我們的合作夥伴生態系為客戶提供廣泛的部署模型選擇,從按分鐘出租的執行個體到本地端的伺服器和託管服務,皆提供業內最高的價值。
所有 MLPerf 的測試結果都顯示了我們的效能持續在提升,這是因為我們的平台擁有成熟且不斷進化的軟體,讓團隊可以快速開始使用持續精進的系統。
我們是如何做到的
這是我們 A100 GPU 第二次參與 MLPerf 測試。在另一篇文章中,詳細描述了 GPU、系統、網路與 AI 軟體等方面的進步如何提升運算速度。
舉例來說,我們的工程師找到了一種使用 CUDA Graphs 啟動全神經網路模型的方法,CUDA Graphs 是一套由 NVIDIA CUDA 運作項目及其依賴項目構成的軟體套裝。如此一來便消除過去測試時 CPU 遇到的瓶頸,這些測試將 AI 模型作為許多單獨元件 (kernel) 的鏈來進行釋放。
此外,大規模測試使用 NVIDIA SHARP,該軟體可以整合網路交換器中的多項資料傳輸作業、減少網路流量與等待 CPU 處理的時間。
結合 CUDA Graphs 與 SHARP,使得資料中心可以運用破紀錄的 GPU 數量來進行訓練工作。這是如自然語言處理等許多領域所需要使用到的運算能力,在這些領域裡的 AI 模型規模持續成長,其包含數十億個參數。
其他優勢包含最新的 A100 GPU 將記憶體頻寬增加近 30%,達到每秒超過2 terabytes (TB) 的記憶體頻寬。
來自客戶對於 MLPerf 的回饋
各類型的 AI 用戶皆認為這些基準測試為其帶來實質的幫助。
瑞典 Chalmers University 的發言人表示:「MLPerf 基準測試提供針對多個跨 AI 平台且清楚的同類型比較,以展現其應用於各種真實案例的實際效能表現。」該大學進行從奈米技術到氣候研究等領域的研究工作。
這些基準幫助使用者找到能夠滿足全球部分規模最大、最先進工廠所要求的 AI 產品。例如,全球頂尖晶片製造商台積電,使用機器學習來提升光學鄰近效應修正功能 (OPC) 與蝕刻模擬 (etch simulation) 的表現。
台積電 OPC 部門主管 Danping Peng 表示:「為了充分發揮機器學習在模型訓練和推論的能力,我們與 NVIDIA 工程團隊合作,將 Maxwell 模擬與反向微影技術引擎轉移到 GPU 上,並看見執行速度大幅提升。MLPerf 基準測試是協助我們做出決定的一項重要因素。」
在醫學與製造領域逐漸受到青睞
這些基準也有助於研究人員突破 AI 的極限,以提升醫療保健水準。
德國癌症研究中心 DKFZ 的醫學影像運算部門負責人 Klaus Maier-Hein 表示:「我們與 NVIDIA 密切合作,將 3DUNet 等創新技術帶入醫療保健市場。產業標準的 MLPerf 基準測試提供相關的效能資料,讓 IT 組織和開發人員能夠取得精確的解決方案,以加速推動其特定專案和應用項目。」
全球研究與製造領域的領導者三星電子 (Samsung),在導入 AI 的過程中採用 MLPerf 基準測試,以提高產品效能及製造生產力。
三星電子的發言人表示:「我們必須具備最佳的運算平台,才能將先進的 AI 技術加以產品化。MLPerf 基準測試提供一個公開且直接的評估方法,讓我們能夠統一評估各平台供應商,進而簡化選擇的過程。」
取得相同的測試結果和工具
MLPerf 的資料儲存庫提供最新測試所使用的各套軟體,因此,所有人皆可重現我們的基準測試結果。我們會持續將這些程式碼加入深度學習框架和容器中,使用者可以在 NVIDIA 的 GPU 應用程式軟體中心 NGC 上取得。
它是全堆疊 AI 平台的一部分,經過最新的產業基準驗證,並且能夠從各個合作夥伴取得,用以處理當前真正的 AI 工作。
-
 經過種種的核算,酷!PC【領航員】主機升級最划算!on 2026-04-01
經過種種的核算,酷!PC【領航員】主機升級最划算!on 2026-04-01 -
 一人買全家享!Synology BeeStation 4TB 私有雲加碼再送可攜式螢幕!on 2026-04-01
一人買全家享!Synology BeeStation 4TB 私有雲加碼再送可攜式螢幕!on 2026-04-01 -

-
 【開箱】散熱美學兼具,風流革新之作!Antec FLUX REAR 中塔式機殼。on 2026-03-31
【開箱】散熱美學兼具,風流革新之作!Antec FLUX REAR 中塔式機殼。on 2026-03-31






{kind=link}