
AMD 展示 Ryzen AI 7840U 運行 Mistral Instruct 語言模式贏過 155H 17% TPS

前陣子 AMD 分享過如何在 Ryzen AI PC 或 Radeon 顯示卡的平台上運行大型語言模型(Large Language Model,LLM),並透過啟動檢索增強生成(Retrieval Augmented Generation,RAG)功能增強和提供 LLM 內容,以及使用本地 LLM 進行編碼。在本地執行這些應用程式無需連接網路,能夠維護AI PC上的資料安全。
這次 AMD 則以 Ryzen AI 筆電對決 Intel Core Ultra 筆電,並主要採用本地運行的 LLM 模型,像是 Llama 2、Mistral AI、code llamma、RAG 等 LLM 模型。

Ryzen AI 7840U 對比 Core Ultra 7 155H 在 Mistral Instruct 7b Q4 K M 的模型上有著 17% 的 TPS(tokens per second)的效能領先,而在 LLAMA v2 Chat 則有著 14% TPS 提升。
至於 TTFT(time to first token)表現上,Ryzen AI 7840U 在 Mistral Instruct 7b Q4 K M 上帶來高達 41% 的效能提升,在 LLAMA v2 Chat 上更有高達 79% 的效能提升。
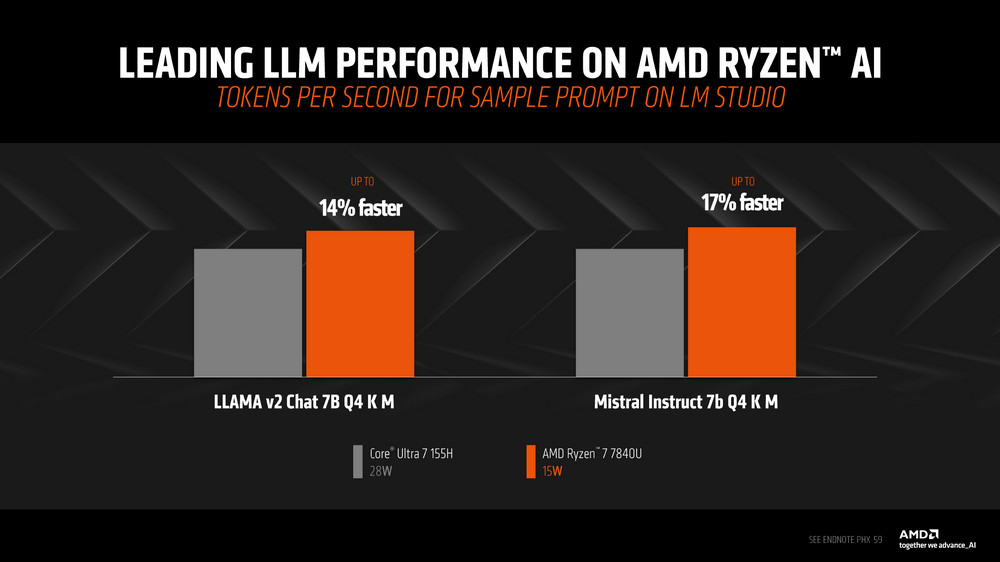
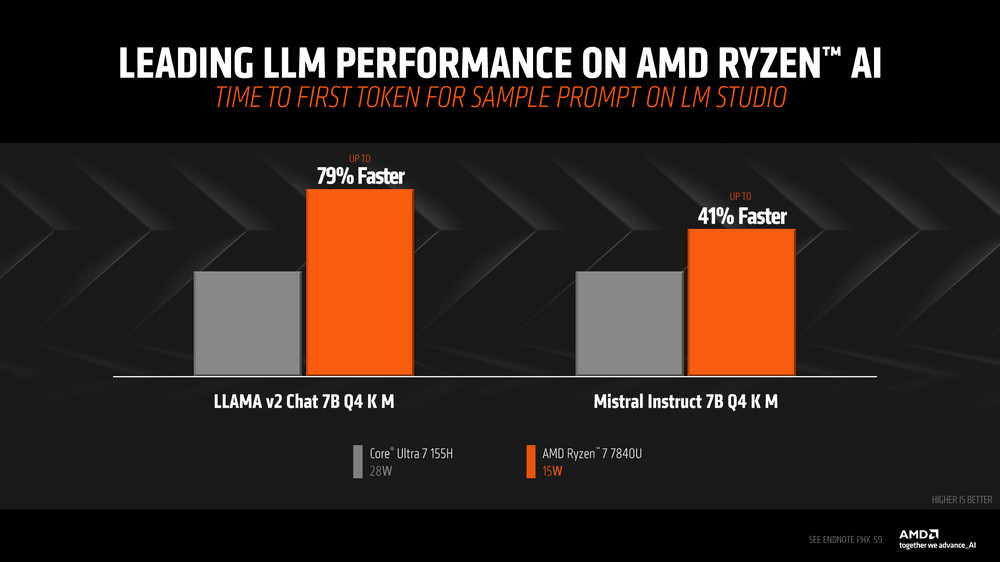
而 Mistral AI 一樣在 TPS、TTFT 等結果上都由 Ryzen AI 獲得較好的效能表現。
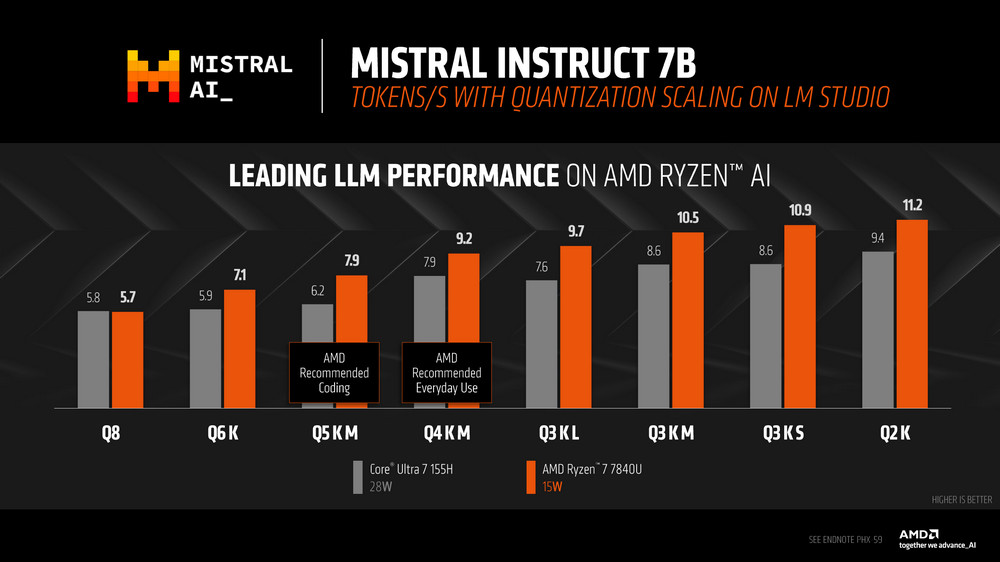
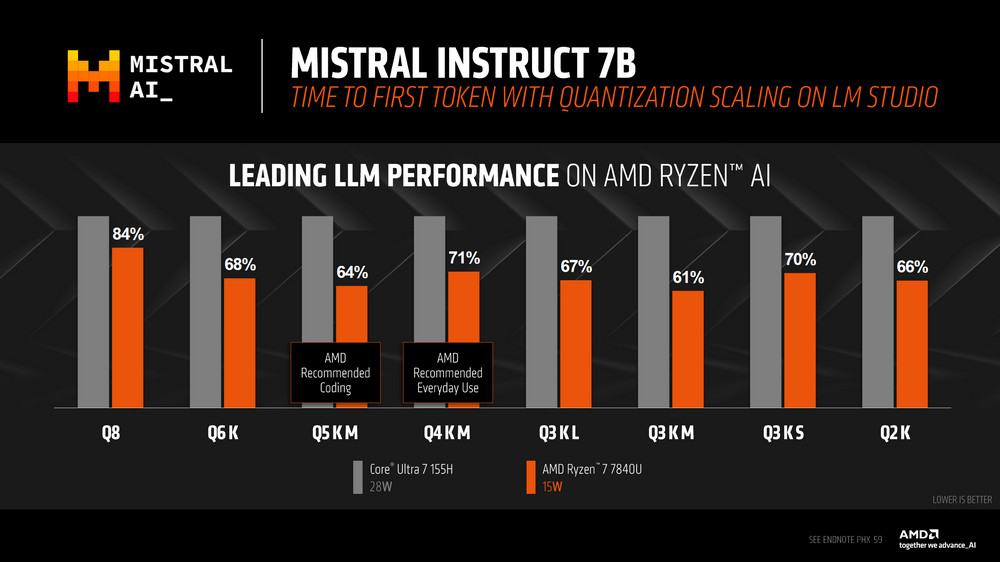
同樣 Llama 2 測試一樣在 TPS、TTFT 等結果有著更好的效能。
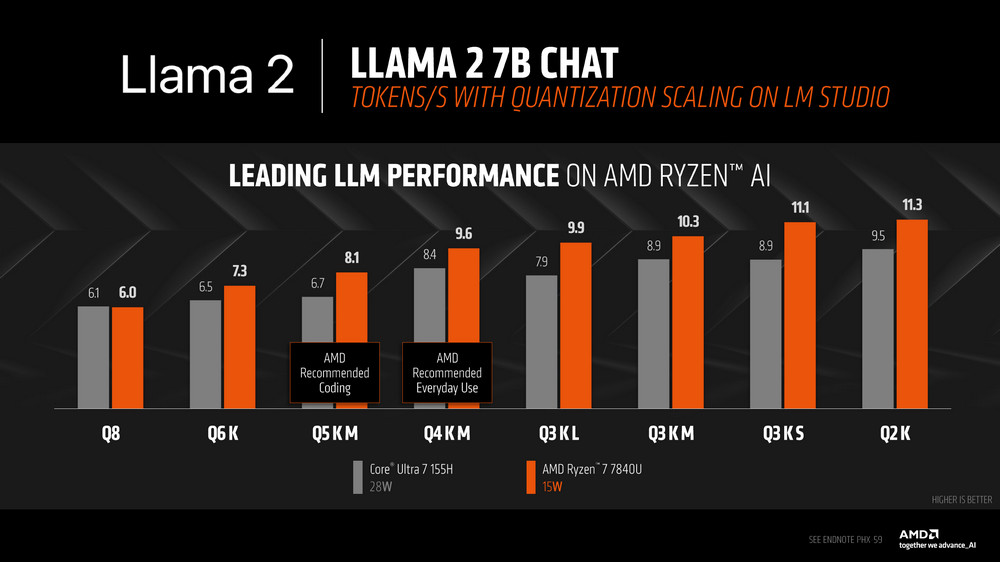
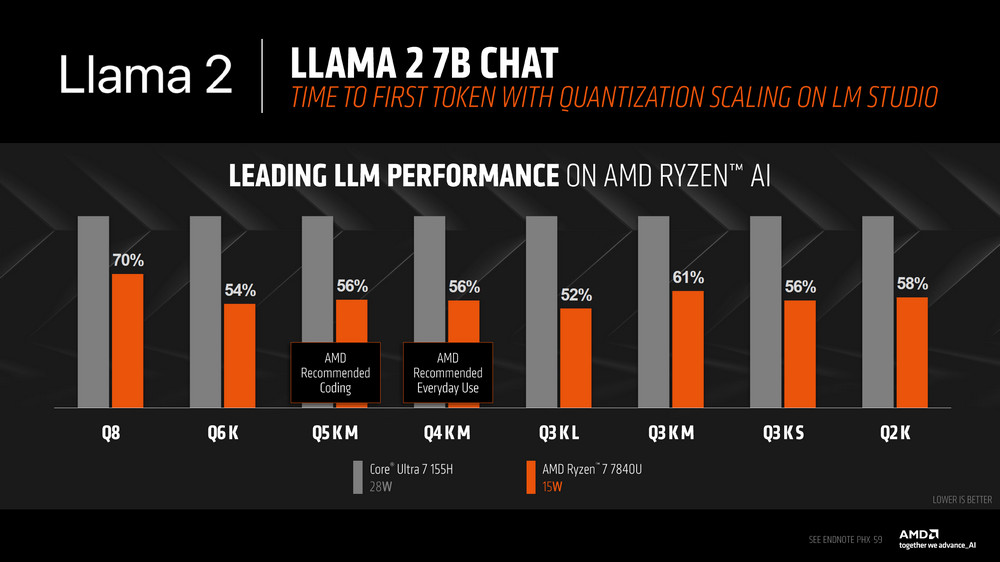
有興趣的玩家可以參考 AMD Blog 中的引導,在本地電腦上安裝 LLM 語言模型,建立自己的 AI 聊天機器人。
-

-
 【開箱】三千有找 Wi-Fi 7 隨便打!TP-Link Archer GE230 電競雙頻路由器。on 2026-05-21
【開箱】三千有找 Wi-Fi 7 隨便打!TP-Link Archer GE230 電競雙頻路由器。on 2026-05-21 -
 【原價屋搶購】你的神裝值得被看見!ROG Cronox GR801幻世神機殼上市,加碼送 ROG 大地墊。on 2026-05-21
【原價屋搶購】你的神裝值得被看見!ROG Cronox GR801幻世神機殼上市,加碼送 ROG 大地墊。on 2026-05-21 -
 行情天天亂漂移,想升級不用再看市場臉色!微星指定電競神機加碼16G享超值加購價!on 2026-05-20
行情天天亂漂移,想升級不用再看市場臉色!微星指定電競神機加碼16G享超值加購價!on 2026-05-20






{kind=link}