
顯示記憶體延遲測試:AMD RNDA 2架構竟比NVIDIA Ampere GPU更優秀
經過多年發展GPU硬體也迎來了多級快取結構。透過精心的設計,其能夠有效緩和各個PC計算零件之間的性能掣肘。但不同GPU製造商之間的架構設計思路,仍有著較大的差別。以目前佔獨顯市場最多的NVIDIA和AMD為例,兩家公司旗下的競品GPU就有不同大小的寄存器和L1 / L2快取。

譬如NVIDIA A100 GPU 的L2快取容量為40MB,直接增加到了上一代V100 的七倍。顯然這考慮到了許多新應用需要更大的快取,且為後續不斷增長的使用需求而預留了一定的空間。有趣的是Chips and Cheese 於近日發布了一份有趣的報告,揭示了AMD 最新一代的RNDA 2、和NVIDIA Ampere GPU 之間的顯示記憶體延遲表現。
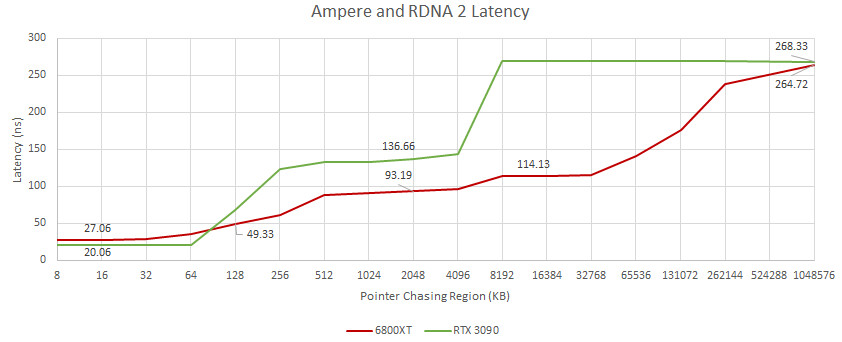
延遲比較(越低越好)
透過在OpenCL中使用簡單的指針追逐測試,其得到了一份有趣的結果。其中採用RDNA 2 架構的AMD Radeon RX 6800 XT顯示卡,其Infinity Cache高速快取的表現很亮眼。與採用Ampere 架構的NVIDIA GeForce RTX 3090旗艦顯示卡相比,即便顯示記憶體(VRAM)方面的延遲幾乎一致,但IF設計還是大幅降低了Radeon RX 6000顯示卡的訪問延遲。
TechPowerUp指出Ampere GPU使用了L1+L2快取系統,測試表明這套解決方案的效用相當緩慢。在從Ampere SM(L1快取)向L2傳輸的時候,數據延遲竟高達100ns 。另一方面儘管AMD RDNA 2 GPU擁有L0/L1/L2快取系統(Infinity Cache理論上也可以視作L3),但A卡的延遲仍低得多。即便從L1到L2,也只需66 ns 。
感興趣的朋友,可移步至Chips and Cheese查看全文。
-
 【開箱】散熱美學兼具,風流革新之作!Antec FLUX REAR 中塔式機殼。on 2026-03-31
【開箱】散熱美學兼具,風流革新之作!Antec FLUX REAR 中塔式機殼。on 2026-03-31 -
原價屋實體門市公休日。") 【公告】3/31(二)原價屋實體門市公休日。on 2026-03-30
【公告】3/31(二)原價屋實體門市公休日。on 2026-03-30 -

-
 【開箱】創作者與高階玩家首選!MSI MEG X870E ACE MAX 主機板。on 2026-03-30
【開箱】創作者與高階玩家首選!MSI MEG X870E ACE MAX 主機板。on 2026-03-30






{kind=link}