
NVIDIA 用 1,472 個 V100 GPU 加速 AI 語言模型 BERT 訓練效能

如今已有不少基本的對話式回覆機器人或 AI 服務已存在多年,然而想要在提升聊天機器人、智慧個人助理服務,以人類理解力的水平運作還是相當困難,主要是無法即時部署超大規模的 AI 模型進行訓練與推論。
NVIDIA 的 AI 平台率先訓練目前最先進的 AI 語言模型,BERT(Bidirectional Encoder Representations from Transformers)是由 Google 所開發的人工智慧自然語言模型,用不到 1 小時即可完成訓練,並在 2ms 內完成 AI 推論。根據 Juniper Research 的報告,光是數位語音助理市場規模預計在未來 5 年內將從 25 億美元成長到 80 億美元。此外, Gartner 也預測 2021 年,15% 的客服互動將完全由 AI 執行,與 2017 年相比增加 400%。
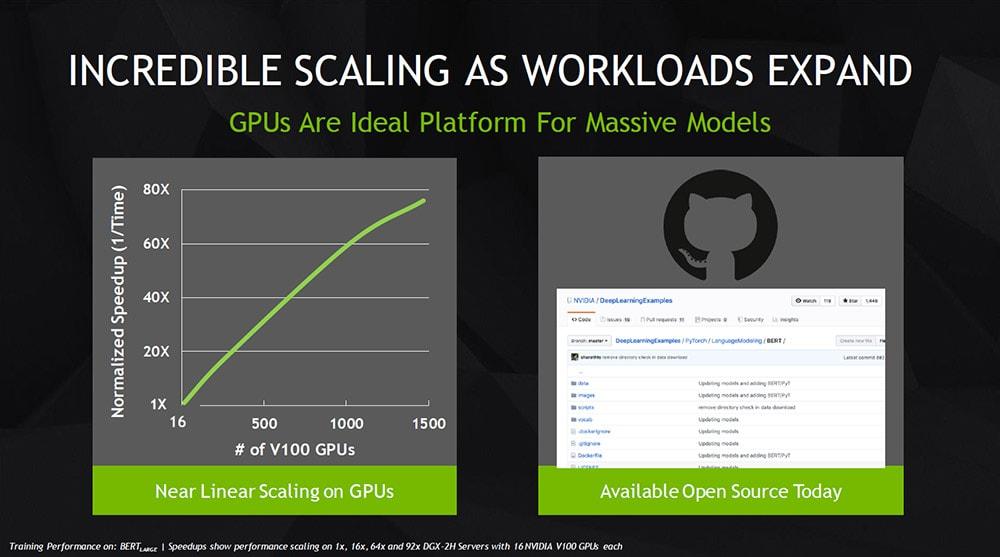
NVIDIA 採用內建 1,472 個 V100 GPU 所組成的 92 個 DGX-2HTM 系統 NVIDIA DGX SuperPOD,執行 AI 語言模型 BERT-Large,成功將 AI 訓練時間從先前的數日大幅縮短至僅 53 分鐘。此外,若只透過一台 NVIDIA DGX-2 系統也可在 2.8 天內就完成 BERT-Large 的訓練。

推論方面,可透過 NVIDIA T4 GPU 運行 TensorRT,在 BERT-Base SQuAD 資料集上僅用 2.2ms 就完成推論,不僅遠低於許多即時應用要求的 10ms 的處理門檻,也大幅領先以高度優化 CPU 程式碼執行的 40ms。
而 NVIDIA Research 在 Transformers 的基礎上著手建構與訓練全球最大的語言模型,並導入 BERT 採用的技術元件,以及許多其他自然語言的 AI 模型。NVIDIA的客製化模型擁有 83 億個參數,數量足足比 BERT-Large 多出 24 倍。

有興趣的開發者,可參考以下連結:
- NVIDIA GitHub BERT 模型的訓練程式碼與 PyTorch 學習框架*
- NGC 模型 Scripts與 TensorFlow 的 check-points
- GitHub 上針對 TensorRT 優化的BERT 範例
- Faster Transformer: C++ 語言 API、TensorRT 外掛與 TensorFlow OP
- MXNet Gluon-NLP 包含 AMP 對 BERT 的支援方案(訓練與推論)
- AI Hub 上針對 TensorRT 優化的BERT Jupyter 軟體說明註記
- Megatron-LM:用來訓練超大型 Transformer 模型的 PyTorch 程式碼
*NVIDIA BERT建置方案是熱門 Hugging Face repo程式庫的優化版本。
-
 【開箱】大佛 Plus!Intel Core Ultra 200S Plus 處理器效能解禁。on 2026-03-23
【開箱】大佛 Plus!Intel Core Ultra 200S Plus 處理器效能解禁。on 2026-03-23 -
 鍵盤甜!價格甜!連下午茶也甜給你!IROCKS K85R 無線機械式鍵盤降價再抽甜甜禮!on 2026-03-23
鍵盤甜!價格甜!連下午茶也甜給你!IROCKS K85R 無線機械式鍵盤降價再抽甜甜禮!on 2026-03-23 -
 【蝦皮商城限定】我出錢,安心用!買 acer 指定系列筆電送延長保固卡!on 2026-03-22
【蝦皮商城限定】我出錢,安心用!買 acer 指定系列筆電送延長保固卡!on 2026-03-22 -
 老牌保鏢在此誰敢造次?飛瑞 5SC/5E 指定款優惠,買再送 65W 快充頭護你周全!on 2026-03-21
老牌保鏢在此誰敢造次?飛瑞 5SC/5E 指定款優惠,買再送 65W 快充頭護你周全!on 2026-03-21






{kind=link}