
AMD 釋出更多 Zen 5 架構升級細節與 Strix Point / Granite Ridge SoC 資訊
AMD Tech Day 後又更新了更多關於 Zen 5、XDNA 2、RDNA 3.5 等架構的細節,以及 Strix Point SoC 與 Granite Ridge SoC 資訊。
Zen 5 的設計目標是提升 1T 與 2T 的性能,成為未來運算核心的基礎,並為了 AI 運算效能加入 AVX512 於 512-bit 的資料流。至於平台方面,Strix Point 行動處理器將提供 Zen 5 與 Zen 5c 兩種不同優化方向的同架構核心,並支援 FP512/FP256 資料流的變化,同時支援 4nm、3nm 與新增 ISA 指令集架構。

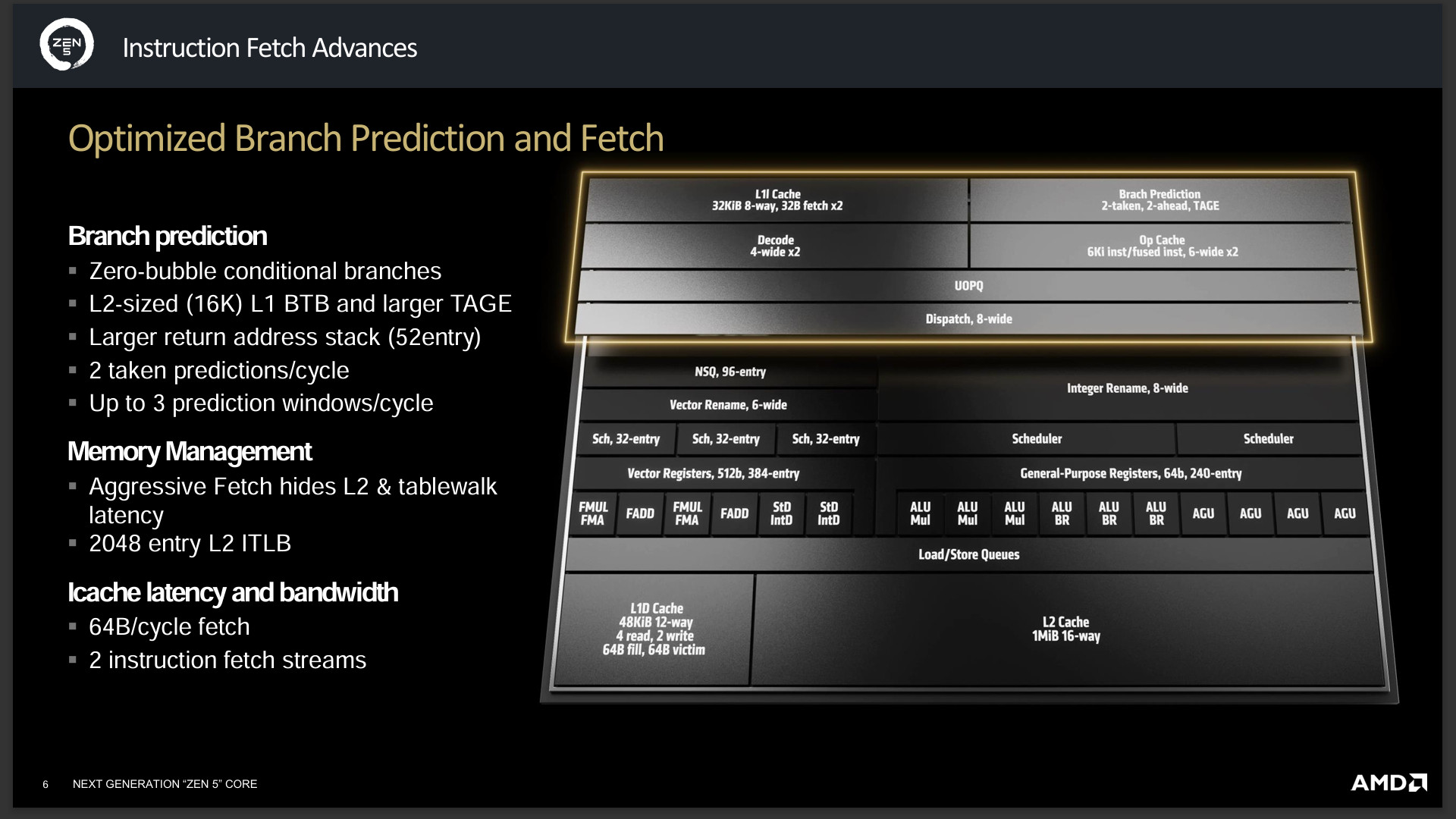
這代 Zen 5 的 Front-end 採用雙管齊下增加 Fetch、Decode 的管線,優化分支預測與預取 Zero-bubble 分支、L2-sized(16K) L1 BTB 與更大的 TAGE,同樣加大 return address stack(52entry),可在每週期處理 2 taken predictions、每週期 3 predictions windows。
記憶體方面有著主動預取功能,可優先通過 L1 取得小 footprint 的資料,但同時加大 2048 entry L2 ITLB 快取滿足更大的 footprint 工作負載。並可在每週期預取 64B L2 快取資料與同時預取 2 Instruction。
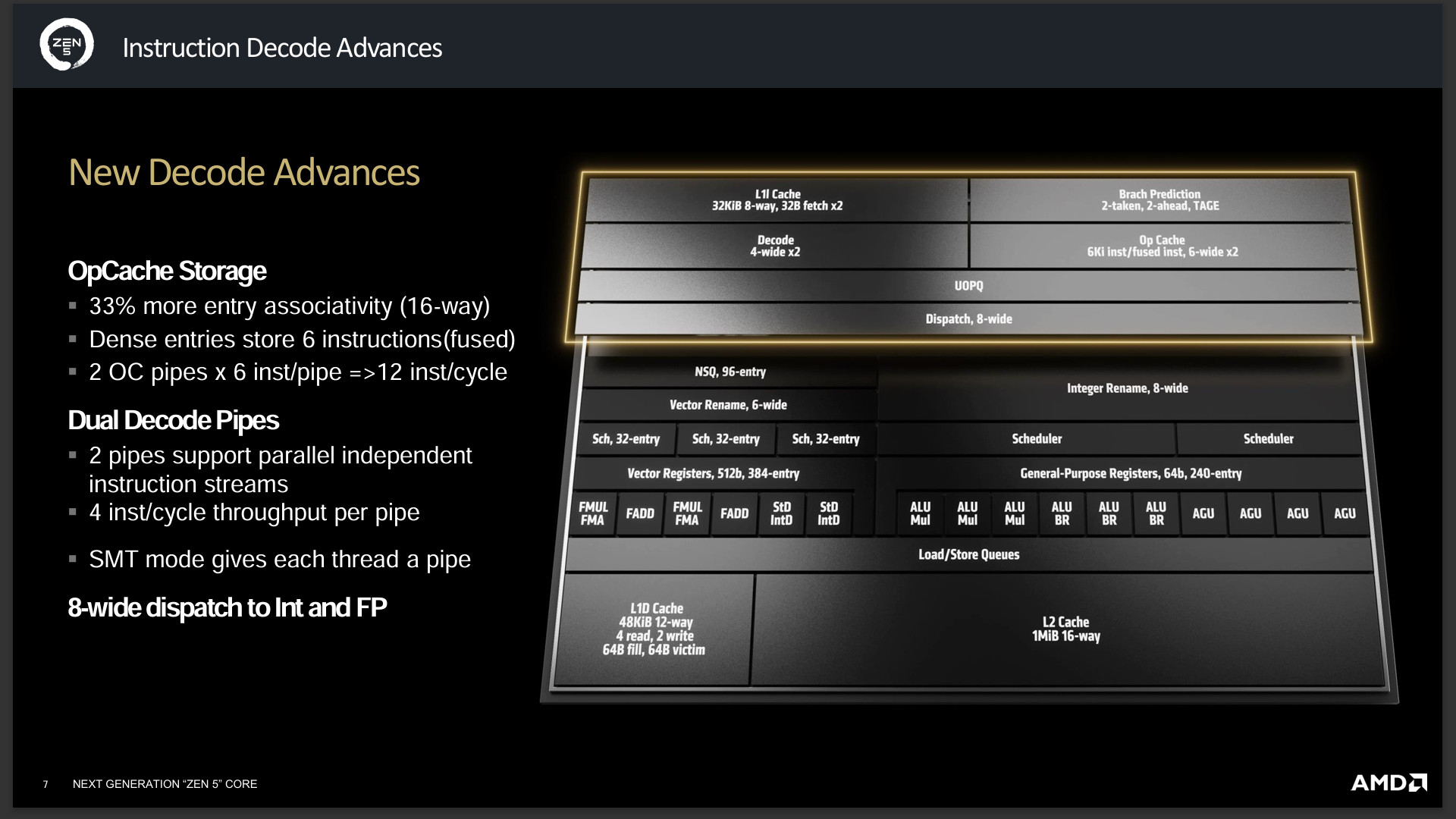
處理器解碼方面有著雙解碼管線 Dual Decode Pipes,且兩個管線是平行且獨立運作,每個管線每週期可處理 4 inst/cycle,而在 SMT 模式下每個執行緒都有著管線。至於工作分配上,有著 8-wide dispatch Int 與 FP 執行單元。
至於 OpCache 有著 33% entryassociativity(16-way)、密集儲存 6 instructions(fused) 以及每週期 12 inst/cycle 的儲存能力。
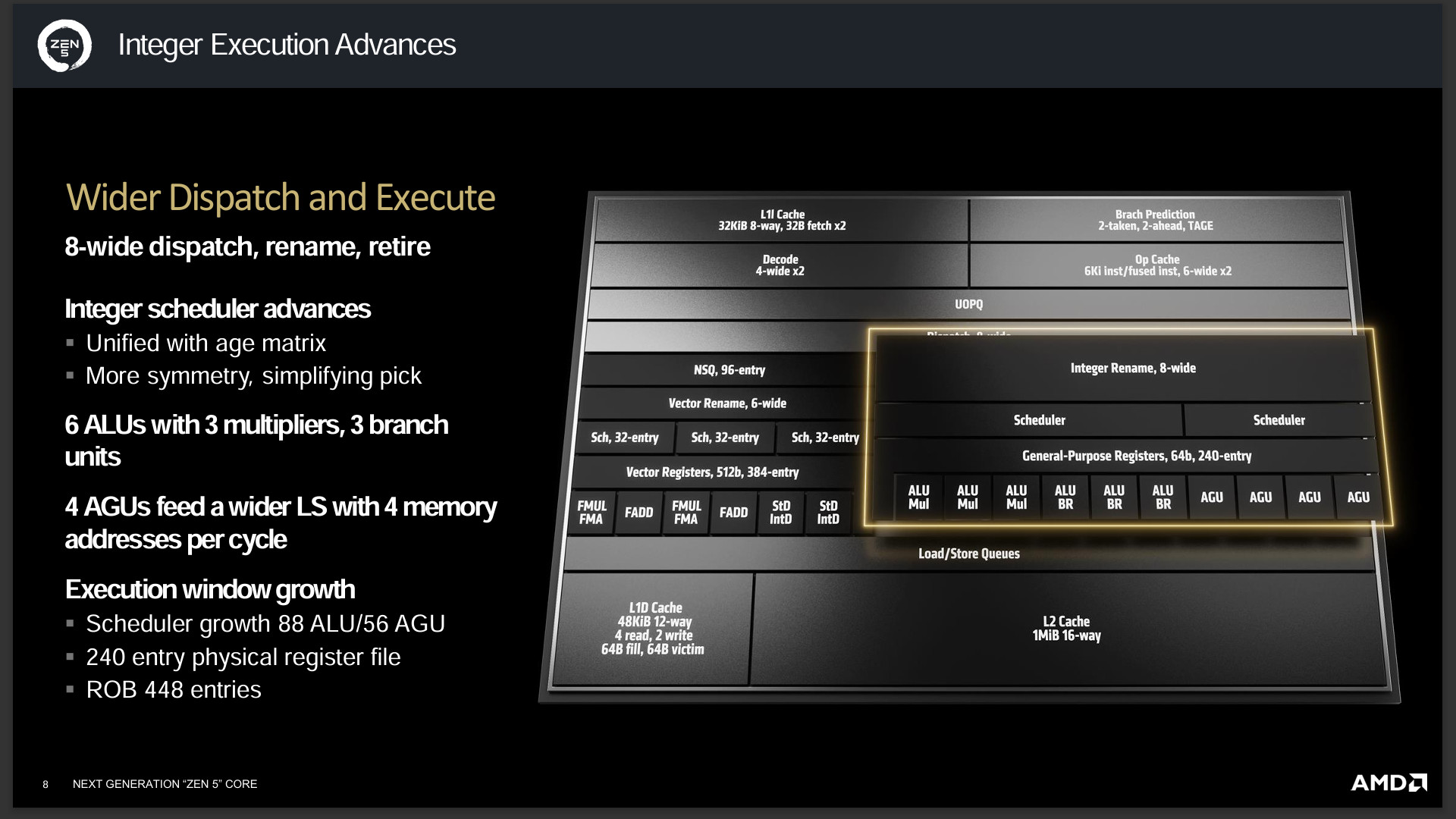
執行單元也具備著 8-wide dispatch、rename、retire,整數調度通過 age matrix 統一可以更對稱並簡化挑選。整數執行單元具備 6 ALU 包含 3 multiplies 與 3 branch,以及 4 AGUs 可每週期處理 4 memory addresses。
執行窗也有著顯著提升,Scheduler 提升至 88 ALU/56 AGU、240 entry physical register file、ROB 448 entrie。
根據前端、執行單元的提升 Load/Store 單元也加大資料頻寬,有著 48KB 12 -way L1D 快取 4-cycle load-to-use。更高的頻寬 4 LS 管線可處理每週期 4 loads/2 stores、4 整數 load 管線可組成 2, FP 管線、每週期 2 store commit 與 64B fill/victim from/to L2 Dcache。
TLB 快取方面 L1 具備 96 entry 完全關連的 all page size DTLB、L2 4k DTLB;並更有著更大的 In-Fight Window,像是 Load/Store queue 提升、Store coalescing buffer 提升、Scalable load ordering queue 提升。有著新 2D stride 資料預取同時提升 stream and region perefetchers。

FP 單元有著 512b 資料路徑的大提升、4 執行管線、2 LS/integer 暫存管線、2 512b loads/cycle 和 1 512b store/cycle、2-cycle FADD。執行窗 NSQ 提升至 8-wide dispatch、3 larger schedulers 1/pipe、實體暫存檔案加倍、ROG/retire 佇列提升。

以上是 Zen 5 架構的主要更新重點,而 Zen 5 與 Zen 5c 是採用同核心架構但不同優化所形成的獨立核心。
Zen 5 是優化最高 1T 執行效能的核心,目標是更高的時脈、更大的每核心 L3 快取設計,因此 Zen 5 核心相對耗電且需要較大的晶片面積。
而 Zen 5c 則是優化擴充性,在同樣的 IPC 與架構功能下,採用較低的時脈提升電源效率並採用較小的每核心 L3 快取。
這主要是提供給行動處理器 Strix Point 同時具備 Zen 5 與 Zen 5c 兩種核心,並通過簡易軟體調度核心運作功能。由於 Zen 5 與 Zen 5c 有著同樣的 IPC 與功能,因此調度上不太需要擔心效能落差過大或者調度錯誤的狀況,並且 Zen 5 與 Zen 5c 都支援 SMT 多執行緒,只需靠軟體在效能、效率上調度即可。
AMD 也認為桌上型處理器 Granite Ridge、Ryzen 9000 不需藉由 Zen 5c 來擴充多核心的平行運算效能,還是採用 Zen 5 策略力拼效能。

Zen 5 新架構下 ISA 指令集也有更新,像是 MOVDIR/MOVD64B 可直接移動 4,8,64 bytes 資料跳過快取直至儲存;VP2INTERSECT、VNNI/VEX 等針對 AVX512 所增加的指令、PREFETCH 軟體預取指令至快取層級。並針對核心 / 虛擬化 / QoS 加入新的指令集。

我們從 Zen 5 對比 Zen 4 架構的表中,可見到 Zen 5 很大程度的加大、加寬核心的執行能力、快取與儲存等資源。
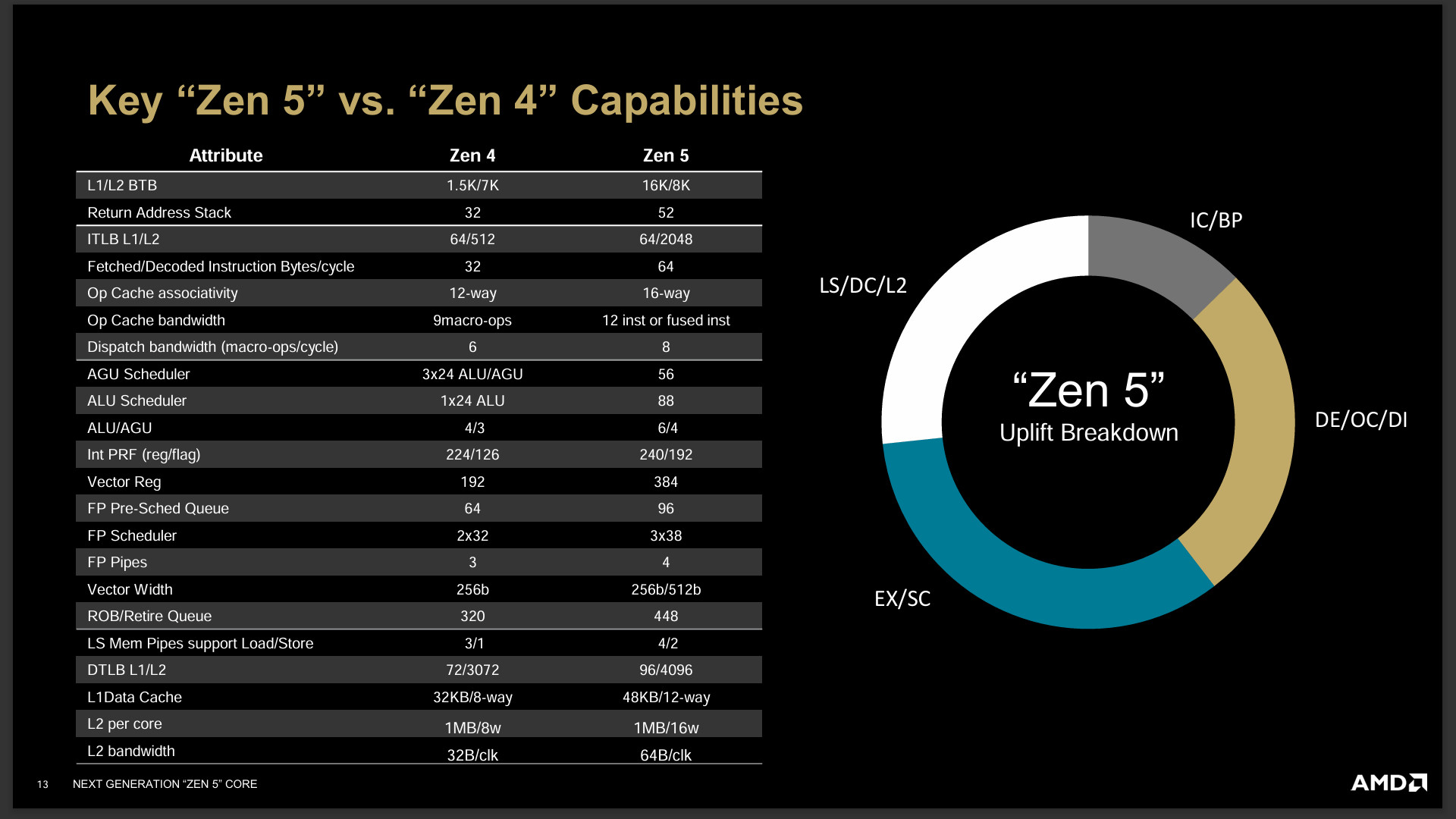
Zen 5 架構更新的重點在於新一代分支預測、加大更層級快取、雙 I-Fetch/decode 管線讓每管線處理 4 inst 指令、每週期可處理 8 ops 的整數或浮點數操作、執行單元有著更高的負載能力 6 整數 ALU 和 4 AGU 可每週期處理 4 memory addresses,還有著 6 FP ops/cycle 與 2-cycle FADD,以及完整支援 512b AVX512 資料寬度。
當然 Zen 5 架構每個核心都具備多執行緒 2 Threads。

Zen 5 Core Complex 設計下,加大了 L2 快取的 associativity 與頻寬,並降低 L3 快取的延遲,而且所有核心透過 L3 共用快取溝通。
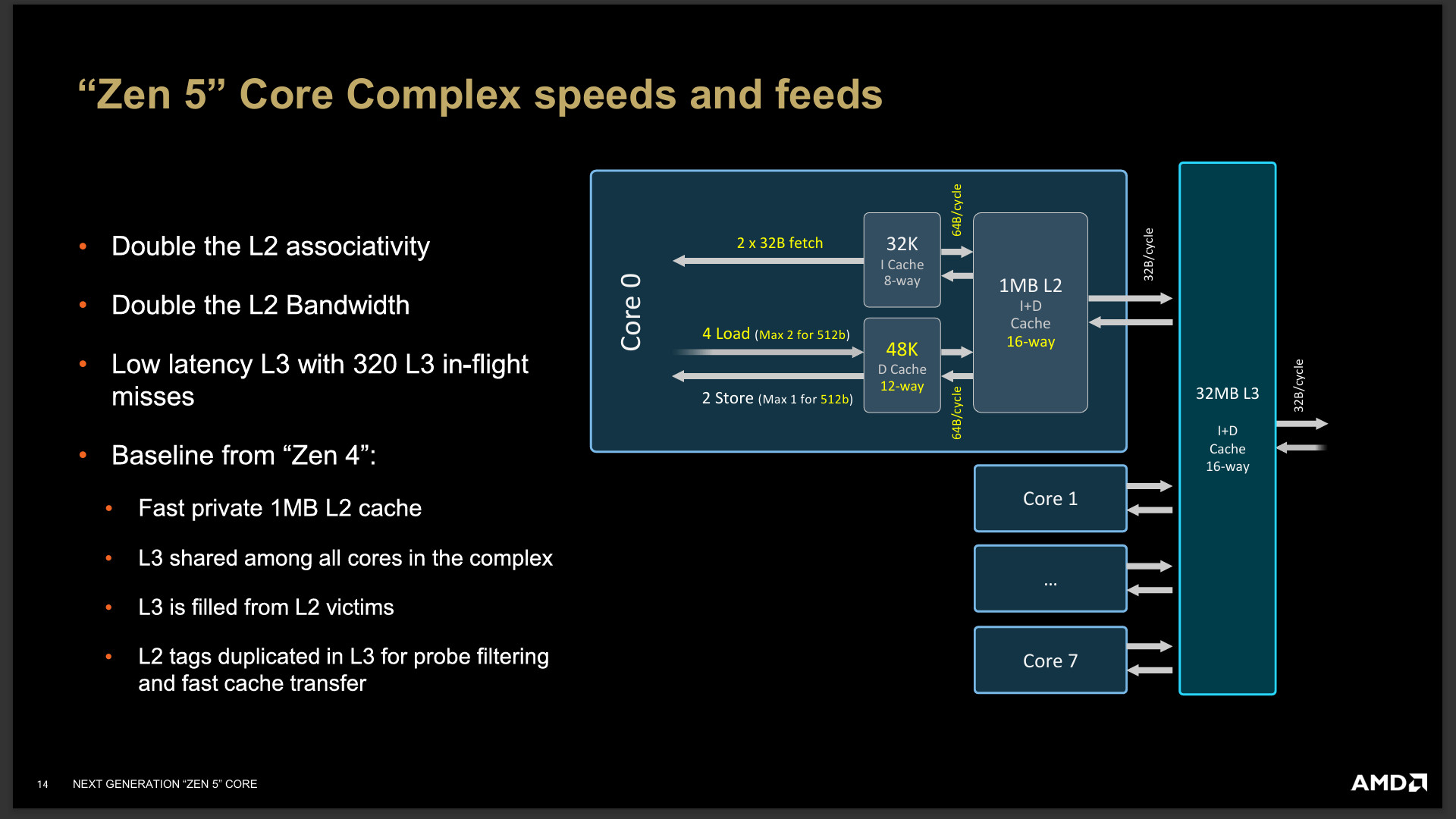
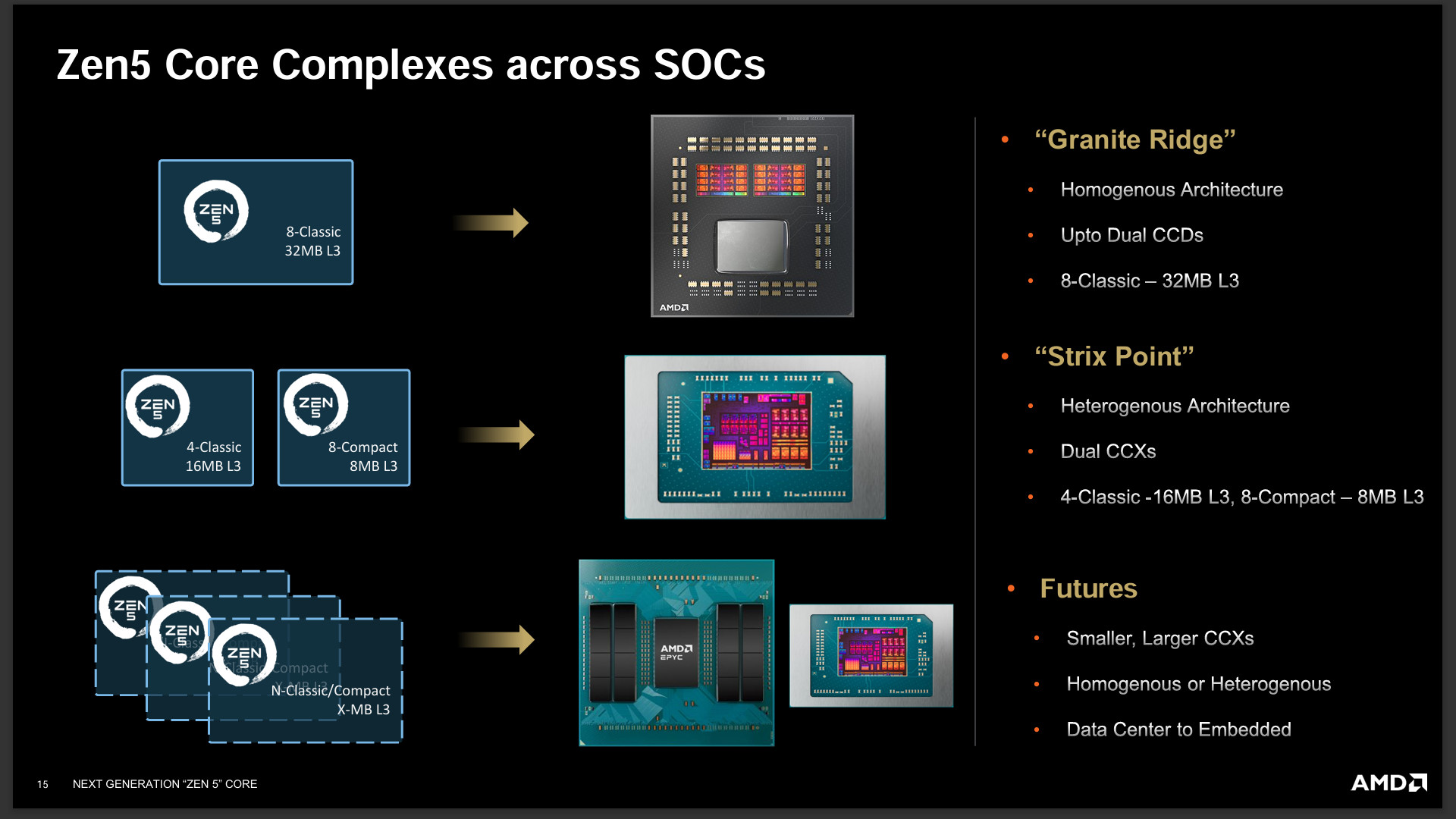
Zen 5 核心架構將使用在 Granite Ridge 也就是 Ryzen 9000 桌上型處理器,有著雙 CCD 設計、8 個標準 Zen 5 核心最大 32MB L3 快取;而行動處理器 Strix Point 的 Ryzen AI 300,則是採用雙 CCX 設計 4 個標準 Zen 5 核心 16MB L3 快取與 8 個 Compact Zen 5c 8MB L3 快取。
Strix Point SoC 設計可見,雙 CCX 設計下包含 4 個核心共享較大 L3 快取的 Zen 5 與 8 核心共享較小 L3 快取的 Zen 5c,並通過 Infinity Fabric 連接系統 I/O 功能。核心一樣提供 PCIe 4.0 連接獨立 GFX GPU、無線整合、NVMe / SATA / USB4 與 PCIe 4.0 GPP 等連接性。
同時整合了 RDNA 3.5 16CU GPU、4 x 8 Array XDNA 2 引擎,以及 Multimedia Engines 負責影音 Code 解碼、音訊處理、顯示控制,以及 128b LPDDR5/DDR5 記憶體、16 PCIe 4.0 擴充、4 顯示輸出與更多的 USB 輸出功能。

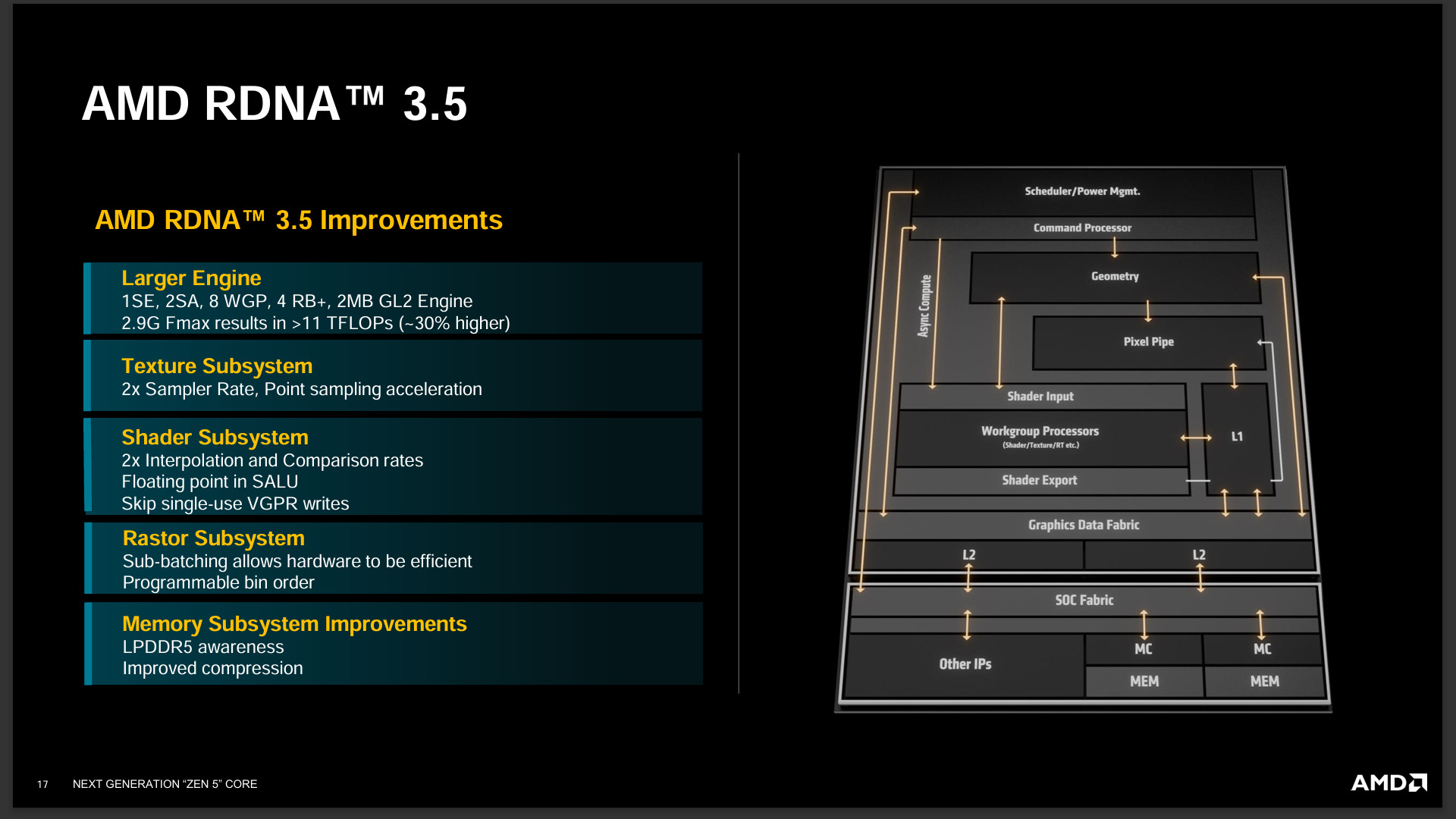
RDNA 3.5 針對每瓦效能優化帶來 2 倍 Texture Sampler Rate 與 Interpolation / Comparison Rate,這是針對繪圖最常見的兩項操作加倍處理速度,並針對 LPDDR5 進行批次處理降低記體存取次數與更好的壓縮技術,提升記憶體每 bit 操作的效能。
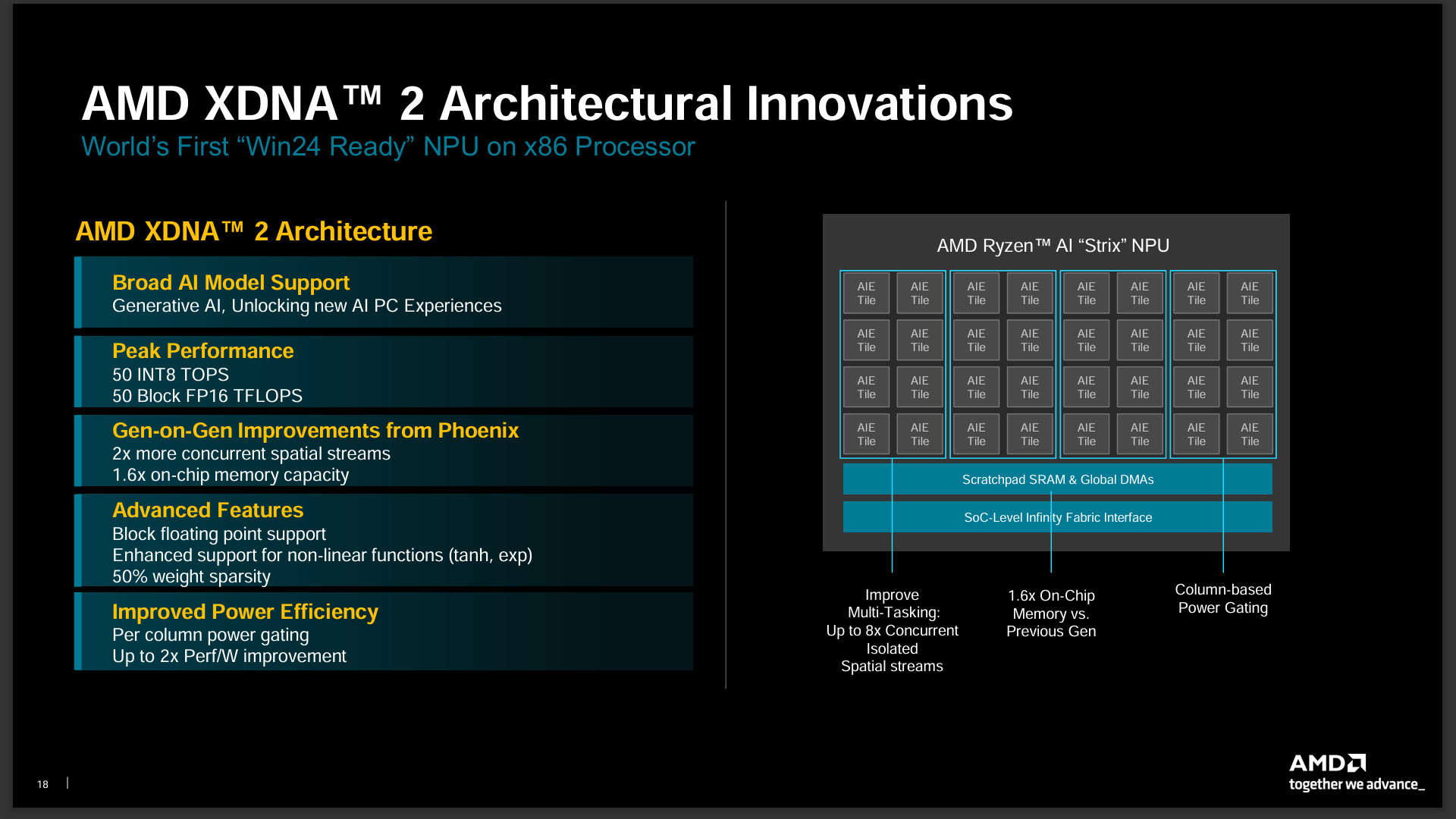
XDNA 2 擁有 32 個 AIE Tile、50 INT8 TOPS 與 50 Block FP16 TFLOPS 的 NPU 運算能力,強化非線性的處理、Block 浮點數運算,同樣加大 1.6x 的晶片記憶體與 2x Macs per tile。相比上一代能具備 5x 倍的運算能力、2x 倍的電源效率的提升。
Granite Ridge SoC 主要採用 2 個 Zen 5 CCD、最高 16 核心 32 執行緒,通過 Die-to-die Infinity Fabric 與 I/O Die 連接,並一樣整合 RDNA 2 架構 2CU 內顯、4 顯示輸出、28 條 PCIe 5.0、5 USB 與 128b DDR5 5600 MT/s 記憶體控制。

AMD 再次兌現承諾,Zen 5 帶來 16% IPC 效能提升、平衡且橫跨核心的 1T/2T 指令與資料吞吐量,完整的 512bit FP 資料流 AVX512 帶來更好 AI 效能提升,效率與效能的可調整性。
AMD 新一代 Strix Point 筆電與 Granite Ridge 桌上型處理器都將在 7 月推出,各位玩家稍等等就能知道 AMD Zen 5 能否再次奪回效能寶座。

-
 就賣一周!BENQ RD280UG 現折 $1000 再送 $3490,限量 15 台開搶!on 2026-04-15
就賣一周!BENQ RD280UG 現折 $1000 再送 $3490,限量 15 台開搶!on 2026-04-15 -
 【開箱】4 螢幕輸出 + Thunderbolt 4!小而巧的華擎 DeskMini B860 準系統。on 2026-04-15
【開箱】4 螢幕輸出 + Thunderbolt 4!小而巧的華擎 DeskMini B860 準系統。on 2026-04-15 -
 【門市限定】龍魂戰機戰力覺醒!MSI電競系列筆電送RGB散熱支架!on 2026-04-14
【門市限定】龍魂戰機戰力覺醒!MSI電競系列筆電送RGB散熱支架!on 2026-04-14 -
 【開箱】戴上就拿不下來的輕!Logitech G325 LIGHTSPEED 雙模無線電競耳機。on 2026-04-14
【開箱】戴上就拿不下來的輕!Logitech G325 LIGHTSPEED 雙模無線電競耳機。on 2026-04-14






{kind=link}