
AMD 搶先挺進 7nm GPU 與 PCIe 4.0 發表 Radeon Instinct MI60 運算加速卡

AMD「Next Horizon」活動中,不僅揭曉 7nm Zen 2 “ROME” EPYC 處理器,更搶先挺進 7nm 製程 GPU 與 PCIe 4.0 規格,發表首款 Radeon Instinct MI60 與 MI50 運算加速卡。
Vega 架構優化 7nm 製程 Radeon Instinct MI60 運算加速卡
AMD 如期推出 Vega 架構優化並採用 7nm 製程的 GPU「Radeon Instinct MI60」運算加速卡,新製程與架構優化,讓 GPU 電晶體密度提高 2 倍,更有著 1.25 倍的性能提升,以及更高的每瓦效能。


MI60 著重於「FP64」與「FP32」加速運算,可加速深度學習所需的 Training 與 Inference 運算;以及 32GB HBM2 記憶體,不僅可達到 1TB/s 記憶體頻寬速度,更具備 End-to-End ECC 保護。
而 MI60 除了是首款 7nm GPU 之外,更是首款支援 PCIe 4.0 的繪圖處理器;而多 GPU 之間通過 Infinity Fabric 橋接,可達到 100GB/s per Link 的連接頻寬,而受惠於 PCIe 4.0 可讓 GPU 與 CPU 之間達到雙向 Bi-Directional 64GB/s 的頻寬;更支援硬體層級的 GPU 虛擬化技術。




性能方面,MI60 在一般運算如「雙精度矩陣乘法(DGEMM)」比起上一代 MI25 有著 8.8 倍的性能提升,達到 6.717 TFLOPS;而深度學習 Resnet-5o 的影像辨識速度,MI60 可達到每秒 498 張,更是 MI25 的 2.8 倍性能提升。
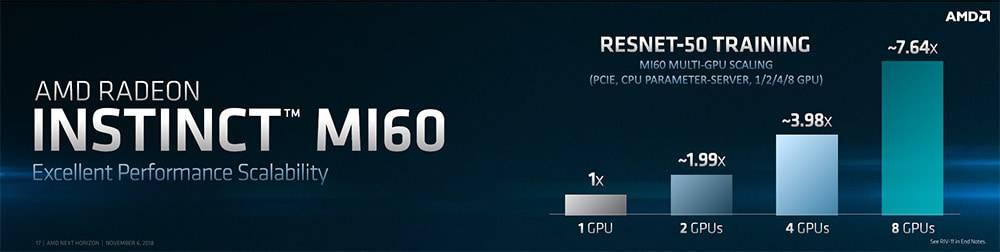
而且在 Resnet-5o 深度學習訓練上,有著近乎倍數的多 GPU 性能提升,2 GPU 有著 1.99 倍性能提升,8 GPU 更可保持在 7.64 倍的訓練性能提升。
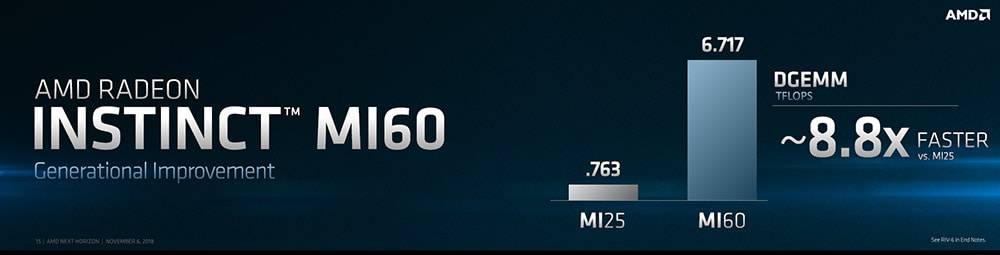

至於 MI60 與對手 Tesla V100 相互比較,雙精度矩陣乘法(DGEMM),MI60 有著 6.717 TFLOPS 快過 V100 的 6.627 TFLOPS;至於單精度矩陣乘法(SGEMM),MI60 有著 14 TFLOPS 運算能力,亦贏過 V100 的 13.1 TFLOPS;只不過,在 Resnet-5o 深度學習訓練上,MI60 僅每秒 334 張的處理速度,緊追在 V100 每秒 357 張的性能之後。


簡單來說 Radeon Instinct MI60 是世界首款 7nm GPU 產品,以及第一款支援 PCIe 4.0 的運算加速卡,更達到 1TB/s 記憶體頻寬速度,以及硬體層級虛擬化。針對 HPC 有著 7.4 TFLOPS FP64 的性能,對於深度學習的 Training 有著 14.7 TFLOPS FP 32 的性能,至於深度學習 Inference 有著 118 TOPS INT4 的性能表現。



-
 AI 獨領風騷!NVIDIA RTX AI PC 遍布原價屋全台門市。on 2026-06-01
AI 獨領風騷!NVIDIA RTX AI PC 遍布原價屋全台門市。on 2026-06-01 -
 一隻神裝秀翻全場,一套信仰打遍天下!ROG 信仰裝備鍵鼠耳椅限時優惠中!on 2026-05-31
一隻神裝秀翻全場,一套信仰打遍天下!ROG 信仰裝備鍵鼠耳椅限時優惠中!on 2026-05-31 -
 觸發快如閃電,優惠直降兩千!Glorious GMMK 3 HE 75%磁軸鍵盤限量優惠再送 Model O!on 2026-05-30
觸發快如閃電,優惠直降兩千!Glorious GMMK 3 HE 75%磁軸鍵盤限量優惠再送 Model O!on 2026-05-30 -







{kind=link}